blog 이전
- git blog io 사용할때 쓴 포스팅 이전 - 현재 형식에 맞게 수정
This commit is contained in:
BIN
src/assets/myPhoto.jpg
Normal file
BIN
src/assets/myPhoto.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 363 KiB |
@@ -4,7 +4,6 @@ date: 2026-01-12
|
||||
tags: 개발, product, lotto
|
||||
excerpt: 작은 실험으로 시작한 로또 페이지를 앞으로 어떻게 발전시키려는지 정리했습니다.
|
||||
---
|
||||
|
||||
# 로또 실험실을 조금 더 재미있게
|
||||
|
||||
처음에는 숫자를 뽑는 기능만 있었지만, 데이터 기록과 패턴 시각화를 더해보고 싶었습니다.
|
||||
@@ -15,3 +14,4 @@ excerpt: 작은 실험으로 시작한 로또 페이지를 앞으로 어떻게
|
||||
- 개인별 기록을 비교할 수 있는 리포트
|
||||
|
||||
이 블로그에 중간 과정과 고민들을 계속 기록해 보려고 합니다.
|
||||
|
||||
|
||||
@@ -4,7 +4,6 @@ date: 2026-01-18
|
||||
tags: 일상, intro, blog
|
||||
excerpt: 이제부터 개발 기록과 여행 기록을 이곳에 차곡차곡 쌓아갑니다.
|
||||
---
|
||||
|
||||
# 새 블로그를 열었습니다
|
||||
|
||||
처음엔 로또 페이지로 시작했지만, 이 공간을 개인 아카이브로 확장하려고 합니다.
|
||||
@@ -16,3 +15,4 @@ excerpt: 이제부터 개발 기록과 여행 기록을 이곳에 차곡차곡
|
||||
- 나만의 프로젝트 회고
|
||||
|
||||
첫 페이지를 열어둡니다. 천천히 채워나갈게요.
|
||||
|
||||
|
||||
@@ -4,7 +4,6 @@ date: 2022-03-11
|
||||
tags: 일상
|
||||
excerpt: 일상 기록 첫 번째 이야기
|
||||
---
|
||||
|
||||
# 일상 기록 첫 번째 이야기
|
||||
|
||||
~~깃~~ 블로그를 만들면서 앞으로 써 내려갈 일상 디렉토리의 첫 번째 포스트를 작성해 봅니다.
|
||||
@@ -17,4 +16,4 @@ excerpt: 일상 기록 첫 번째 이야기
|
||||
|
||||
때문에 일상 포스트를 꼭 해보고 싶었다.
|
||||
|
||||
~~깃~~ 블로그 일상 포스트 시작합니다.
|
||||
~~깃~~ 블로그 일상 포스트 시작합니다.
|
||||
@@ -4,7 +4,6 @@ date: 2022-03-13
|
||||
tags: 일상
|
||||
excerpt: 깃 저장소 변경하면서 잠깐 쉬는 타임에 끄적여보는 일상 기록
|
||||
---
|
||||
|
||||
# 일상 기록 - 깃 저장소 변경
|
||||
|
||||
기존 학부시절부터 사용했던 깃 저장소([git_storage_gahu](https://github.com/gahu))에서 했었던 프로젝트와 공부 했던 기록들을 정리해서
|
||||
@@ -18,3 +17,4 @@ excerpt: 깃 저장소 변경하면서 잠깐 쉬는 타임에 끄적여보는
|
||||
블로그 작업 준비도 하면서 기존 프로젝트들을 옮기고 정리한다는게 쉬운 일은 아니지만
|
||||
지금 목표로 하고 있는 일이 있기 때문에 시작을 할 수 있었던것 같고,
|
||||
무엇보다도 새로 산 Macbook M1 Max를 잘 활용해 볼 수 있는 기회가 되지 않을까 생각하면서 작업하고 있다.
|
||||
|
||||
@@ -4,7 +4,6 @@ date: 2022-03-15
|
||||
tags: 일상
|
||||
excerpt: 오랜만에 삼겹살집에 가서 먹부림한 하루 기록.
|
||||
---
|
||||
|
||||
# 일상 기록 - 삼겹살 먹부림
|
||||
|
||||
오늘 오랜만에 집 근처에 있는 삼겹살집에 갔다.
|
||||
@@ -16,3 +15,4 @@ excerpt: 오랜만에 삼겹살집에 가서 먹부림한 하루 기록.
|
||||
돼지 반마리를 시켰는데, 위에 사진 처럼 두꺼운 삼겹살과 항정살, 갈비살, 목살 등이 500g 나오는데 우리 둘이서는 이정도가 딱 정당히 배부르고 좋은 것 같다.
|
||||
|
||||
최근에 감기 기운이 있어서 목도 칼칼하니 별로 좋지 않았는데 기름진 고기를 먹으며 힐링했던 시간
|
||||
|
||||
@@ -2,9 +2,8 @@
|
||||
title: 소고기 먹부림
|
||||
date: 2022-04-02
|
||||
tags: 일상
|
||||
excerpt: 여의도 창고 43에서 오랜만에 소고기와 와인을 즐긴 기록.
|
||||
excerpt: 승토리와 여의도 창고 43 출격
|
||||
---
|
||||
|
||||
# 일상 기록 - 소는 누가~~ 키우나?!
|
||||
|
||||
오랜만에 승토리와 몸보신(?)을 하기 위해서 여의도에 있는 고깃집을 탐색했다.
|
||||
@@ -47,3 +46,4 @@ excerpt: 여의도 창고 43에서 오랜만에 소고기와 와인을 즐긴
|
||||
입에 넣자마자 사라지는 마법을 느끼며 정말 괜찮은 소고기를 먹어본 것 같다.
|
||||
|
||||
고기와 와인을 먹고 냉면, 깍두기 볶음밥까지 완벽하게 마무리를 지으며 배 터지게 잘 먹고서 나왔다. :)
|
||||
|
||||
@@ -1,10 +1,9 @@
|
||||
---
|
||||
title: 코딩테스트
|
||||
title: 오늘의집 코딩테스트
|
||||
date: 2022-04-09
|
||||
tags: 공부
|
||||
tags: 일상
|
||||
excerpt: 오늘의집 코딩테스트를 치르며 느낀 점을 정리한 기록.
|
||||
---
|
||||
|
||||
# 코딩 테스트 기록
|
||||
|
||||
오늘의집 개발자 대규모 채용 코딩테스트
|
||||
@@ -22,3 +21,4 @@ excerpt: 오늘의집 코딩테스트를 치르며 느낀 점을 정리한 기
|
||||
지금까지 알고리즘을 이렇게 꾸준히 한 경험이 많지 않아서인지 생각보다 구현에는 어려움이 없었고, 평소에 얼마나 하느냐가 크게 다가왔었다. ~~(심지어 전날 새벽까지 놀고 집중해서 할 수 있었다는게 놀라울 정도)~~
|
||||
|
||||
목표인 IT 대장급이라고 불리는 기업의 코테 올솔할 수 있는 실력을 갖출때까지 멈추지 않고 계속 할 것이다.
|
||||
|
||||
@@ -4,7 +4,6 @@ date: 2022-04-25
|
||||
tags: 일상
|
||||
excerpt: 바쁜 일정 속에서 다시 루틴을 잡아가려는 마음 기록.
|
||||
---
|
||||
|
||||
# 일상의 기록 - 04월25일
|
||||
|
||||
최근에는 업무도 바빠서 늦게까지 야근하고, 그러지 않은 날에는 미뤄진 약속을 가느라고 목표로 했던 1일 1commit 100일 목표에서 많이 떨어지게 된 것 같다.
|
||||
@@ -14,3 +13,4 @@ excerpt: 바쁜 일정 속에서 다시 루틴을 잡아가려는 마음 기록.
|
||||
처음 1일 1commit을 목표로 했을 때에는 공부도 흥미롭고, 일도 여유가 있었기 때문에 공부에 투자하는 시간도 많았는데 그러지 못하는게 너무 불편한 상황이 되었다.
|
||||
|
||||
이번주만 지나면 그래도 여유를 찾을 수 있을것 같으니 좀 더 공부하고 목표를 채워가는 일상을 기록 할 수 있도록 노력할 것이다.
|
||||
|
||||
@@ -1,10 +1,9 @@
|
||||
---
|
||||
title: 식의약 공공데이터 활용 공모전 준비
|
||||
date: 2022-06-09
|
||||
tags: 개발, 아이디어
|
||||
tags: 일상
|
||||
excerpt: 공공데이터 공모전 준비 과정과 아이디어 선정 기록.
|
||||
---
|
||||
|
||||
# 식의약 공공데이터 활용 공모전 준비
|
||||
|
||||
이번에 같은 팀의 동료와 동기 3명이서 식의약 공공데이터 활용을 해서 웹/앱 개발을 하는 공모전에 참가하려고 한다. <br />
|
||||
@@ -17,3 +16,4 @@ excerpt: 공공데이터 공모전 준비 과정과 아이디어 선정 기록.
|
||||
(개발하느라 고생할거 생각하면 아찔하긴 하다..) <br />
|
||||
|
||||
8월 초까지 개발이 어느정도 완료가 되어야 하니 스케줄 정해진대로 완료해서 좋은 성과를 냈으면 한다. <br />
|
||||
|
||||
@@ -1,10 +1,9 @@
|
||||
---
|
||||
title: 식의약 공공데이터 활용 공모전 1차 평가 통과
|
||||
date: 2022-07-06
|
||||
tags: 개발, 아이디어
|
||||
tags: 일상
|
||||
excerpt: 공모전 1차 통과 후 일정과 해야 할 일 정리.
|
||||
---
|
||||
|
||||
# 식의약 공공데이터 활용 공모전 1차 평가 통과
|
||||
|
||||
'그린라이트'라는 장기 기증 활성화를 주제로 하는 캠페인의 이름을 따서 식의약 공공데이터 활용 공모전에 지난 6월에 참가를 했었다. <br/>
|
||||
@@ -15,3 +14,4 @@ excerpt: 공모전 1차 통과 후 일정과 해야 할 일 정리.
|
||||
공공데이터도 사용 신청도 미흡한 상태라 걱정이 되긴 하지만 팀원들과 모여서 합의하고 일정 및 업무 분담을 하기로 했다.
|
||||
|
||||
이번에도 좋은 결과를 거둘 수 있는 공모전이 되었으면 좋겠다고 생각하고 있다.
|
||||
|
||||
@@ -4,7 +4,6 @@ date: 2023-04-29
|
||||
tags: 일상
|
||||
excerpt: 오랜만에 기록을 다시 시작하며 하루를 정리한 글.
|
||||
---
|
||||
|
||||
# 일상의 기록
|
||||
|
||||
오랫만에 일상의 기록
|
||||
@@ -29,3 +28,4 @@ excerpt: 오랜만에 기록을 다시 시작하며 하루를 정리한 글.
|
||||
또한 승토리와 6월에 결혼을 준비하는 단계에 도입하기로 했다.
|
||||
이것은 엄청나게 의미 있는 것이며, 인생에서 전환기가 될 수 있다고 생각한다.
|
||||
지금 이사가는 집에서 같이 시작하기에는 내가 생각했던 부분보다는 소소할 수 있겠지만, 차근차근 준비해보려고 한다. 💪
|
||||
|
||||
@@ -4,14 +4,6 @@ date: 2022-04-07
|
||||
tags: 개발
|
||||
excerpt: slick 슬라이더, 목차, 페이지 버튼, 유튜브 임베드 추가 정리.
|
||||
---
|
||||
|
||||
# 게시글 테스트
|
||||
|
||||
* toc
|
||||
{:toc .large-only}
|
||||
|
||||
---
|
||||
|
||||
## slick image
|
||||
[Slick](https://kenwheeler.github.io/slick/)
|
||||
slick 사이트에 들어가서 `get it now`를 눌러 다운로드 받아주어 slick 폴더를 `/assets/css/slick`에 복사>붙여넣기 해준다.
|
||||
@@ -261,3 +253,4 @@ a.external::after, a::after {
|
||||
|
||||
---
|
||||
|
||||
|
||||
12
src/content/blog/dev/flutter/2022-04-05-flutter-envbuild.md
Normal file
12
src/content/blog/dev/flutter/2022-04-05-flutter-envbuild.md
Normal file
@@ -0,0 +1,12 @@
|
||||
---
|
||||
title: Flutter 개발
|
||||
date: 2022-04-05
|
||||
tags: flutter, 개발
|
||||
excerpt: Flutter 개발 환경 세팅
|
||||
---
|
||||
# Flutter 개발 환경
|
||||
|
||||
플러터 개발을 위해 Android Studio를 설치하고 개발 프로젝트를 만들어서 emulator를 실행시켰다.
|
||||

|
||||
|
||||
생소하다면 생소한 디렉토리 구성과 환경을 구축해보고 나니 이제부터 시작이겠구나 막막하면서도 두근거림이 있다.
|
||||
108
src/content/blog/dev/flutter/2022-04-05-flutter-start.md
Normal file
108
src/content/blog/dev/flutter/2022-04-05-flutter-start.md
Normal file
@@ -0,0 +1,108 @@
|
||||
---
|
||||
title: Flutter 개발 일지
|
||||
date: 2022-04-05
|
||||
tags: flutter, 개발
|
||||
excerpt: Flutter에 대한 이해
|
||||
---
|
||||
# Flutter?
|
||||
|
||||
* toc
|
||||
{:toc .large-only}
|
||||
|
||||
> Flutter란 생소한 언어의 출현과 동시에 정말 흥미가 생겼다.
|
||||
네이티브 앱에 근접한 속도를 내면서 하나의 코드로 Android, iOS를 동시에 개발할 수 있다니!
|
||||
때문에 배워보면서, 개발해보면서 시대의 흐름을 따라가보려고 한다.
|
||||
|
||||
### 작성되는 글
|
||||
|
||||
이 디렉토리에는 플러터에 대해서 공부하고 내용을 정리하면서 내가 이해한 내용을 작성하는 저장소이다.
|
||||
|
||||
플러터는 다트를 기반으로 하는 애플리케이션 개발 언어이다. 여러 장점을 가지고 있으며 무엇보다도 안드로이드와 애플을 구분없이 개발 할 수 있다는 점에서 내 관심을 끌었다.
|
||||
|
||||
또한 네이티브 앱 못지 않은 빠른 속도를 자랑한다니 이런 어썸한 언어에 관심이 가는게 당연하지 않겠는가?
|
||||
|
||||
때문에 이 카테고리는 플러터를 배우며, 개발하며 익힌 지식이나 정리할 내용들을 작성하는 저장소이다.
|
||||
|
||||
지금 구상하고 있는 앱이 두 가지 정도 있는데, 이것을 실용화 할 수 있을 정도의 수준까지 더 노력해보려 한다.
|
||||
|
||||
--------------------------------------------------------
|
||||
|
||||
## 플러터의 등장 배경
|
||||
|
||||
2007년 애플의 아이폰이 등장한 이후 스마트폰은 끊임없이 발전하고 있습니다. 애플은 iOS 운영체제를 발표하면서 오브젝트브-C(Objective-C)로 만든 아이폰용 앱을 출시할 수 있는 앱스토어를 만들었습니다. 그로부터 1년 뒤 구글도 안드로이드 운영체제를 발표하면서 자바(Java)를 사용해 안드로이드용 앱을 판매할 수 있는 구글 플레이를 만들었습니다.
|
||||
|
||||
다양한 기업이 잇따라 이 싸움에 뛰어들었지만 10년이 훨씬 지난 지금도 안드로이드와 iOS의 점유율이 거의 100%라고 해도 과언이 아닐 정도로 두 플랫폼이 모바일 시장을 장악하고 있습니다.
|
||||
")
|
||||
|
||||
애플과 구글은 각자의 앱 개발 생태계를 확장하려는 목적으로 새로운 언어를 내놓았습니다. 애플은 오브젝티브-C 대신에 스위프트(Swift)라는 언어를 만들었고, 구글은 코틀린(Kotlin)이라는 새로운 언어로 자바를 대체하려고 합니다. 새롭게 등장한 두 언어는 지금도 계속 진화하면서 앱 개발 환경을 더 나은 방향으로 이끌고 있습니다. 오브젝티브-C나 스위프트로 iOS 앱을 개발하거나 자바나 코틀린으로 안드로이드 앱을 개발하는 것처럼 각 모바일 운영체제에 맞는 언어로 개발한 앱을 네이티브 앱(native app)이라고 합니다.
|
||||
|
||||
## 웹앱, 하이브리드 앱의 등장
|
||||
|
||||
두 회사가 시장을 나눠 먹는 사이 개발자들은 더 많은 사용자가 앱을 사용하게 하려고 똑같은 앱을 iOS용과 안드로이드용으로 두 번 개발해야 했습니다. 개발자에게는 조금 피곤한 상황이지 않을 수 없었죠. 그래서 "하나의 소스로 안드로이드와 iOS 모두에서 실행할 수 있는 방법이 없을까?" 를 고민하게 되었고, 그 결과로 웹앱과 하이브리드 앱이 등장했습니다.
|
||||
|
||||
**웹앱** (web apps)은 웹 기술을 이용해서 만든 앱입니다. 앱의 화면을 나타내는 뷰(view)를 모바일용 웹으로 만들어서 다양한 기종과 해상도에 대응하며 빠르게 개발할 수 있습니다. 요즘은 네이티브 앱처럼 알림도 보내고 오프라인에서도 동작하는 **프로그레시브 웹앱** (progressive web apps, PWA)도 주목받고 있습니다.
|
||||
그리고 **하이브리드 앱** (hybride apps)은 웹앱을 만든 후 별도의 프레임워크를 이용해 운영체제별로 동작하는 앱을 만드는 기술입니다.
|
||||
|
||||
하지만 이러한 기술로 만든 앱은 네이티브 앱과 비교해 상대적으로 속도가 느리고 애니메이션 사용에도 제약이 있는 등 스마트폰의 성능을 충분히 활용할 수 없었습니다. 이때 리액트 네이티브가 등장했습니다.
|
||||
|
||||
## 리액트 네이티브와 플러터
|
||||
|
||||
페이스북에서 만든 **리액트 네이티브** (React Native)는 여러 운영체제에서 동작하는 앱을 개발 할 수 있는 크로스 플랫폼 앱 개발 프레임워크입니다. 특히 웹 개발자에게 익숙한 자바스크립트를 사용하므로 웹 개발자가 새로운 언어를 배우지 않고서도 앱을 개발할 수 있는 길을 터주었습니다. 또한 네이티브 언어로 개발할 때는 사용자 인터페이스(UI, user interface)를 변경할 때마다 다시 빌드해야 했지만, 리액트 네이티브는 코드를 변경하면 화면에 바로 표시되므로 개발 효율도 좋습니다.
|
||||
|
||||
리액트 네이티브에서는 자바스크립트가 다리 역할을 하면서 안드로이드나 iOS의 네이티브 API에 접근합니다. 똑같은 자바스크립트 코드가 안드로이드와 iOS처럼 각기 다른 운영체제에서 실행되게 연결해 주는 거죠. 따라서 웹앱이나 하이브리드 앱보다는 속도가 빠르지만 화면에 표시할 내용이 많으면 느려질 수 있습니다. 그리고 운영체제가 업데이트되면 디자인이 의도한 바와 달라질 수 있습니다.
|
||||
|
||||
반면에 **플러터** (Flutter)는 똑같이 크로스 플랫폼 앱 개발 프레임워크지만 구글에서 만든 다트(Dart)라는 언어를 사용합니다. 따라서 자바나 C# 같은 컴파일 언어가 가진 특징을 활용해 앱을 개발할 수 있습니다.
|
||||
|
||||
플러터는 크게 프레임워크와 엔진, 임베더 계층으로 구성되어 있습니다. 프레임워크 계층에는 다트 언어로 개발된 여러 가지 클래스가 있으며 이러한 클래스를 이용해 앱을 개발합니다. 그 다트 언어로 개발된 여러 가지 클래스가 있으며 이러한 클래스를 이용해 앱을 개발합니다. 그리고 엔진 계층은 플러터의 코어를 담당하는데 대부분 C와 C++ 언어로 만들어졌습니다. 여기서는 데이터 통신, 다트 컴파일, 렌더링 그리고 시스템 이벤트 등을 처리합니다.
|
||||
|
||||

|
||||
|
||||
마지막으로 임베더 계층에는 플러터 앱이 크로스 플랫폼에서 동작하도록 플러터 엔진이 렌더링한 결과를 플랫폼별 네이티브 언어로 뷰를 만들어 화면에 보여줍니다. 안드로이드 앱은 자바와 C, C++ 언어로 만들고, iOS 앱은 오브젝티브-C와 오브젝티브-C++ 언어로 만듭니다. 그리고 리눅스와 윈도우 앱은 C++ 언어로 만듭니다. 따라서 다트 언어로 소스 파일만 작성하면 플러터의 각 계층을 거쳐 플랫폼별 앱을 개발할 수 있습니다. 이 가운데 내부적인 처리는 신경 쓰지 않고서 플러터나 다트 언어를 업데이트만 하면 됩니다.
|
||||
|
||||
| 구분 | 리액트 네이티브 | 플러터 |
|
||||
|-----|-------------|------|
|
||||
|개발 주체| 페이스북 | 구글 |
|
||||
| 언어 | 자바스크립트 | 다트 |
|
||||
| 출시 | 2015년도 |2017년도|
|
||||
| 성능 | 빠르지만 네이티브 앱큼은 아님 | 네이티브 앱에 근접한 속도 |
|
||||
|학습 곡선| 높음(네이티브 앱 개발자 기준) | 낮음(네이티브 앱 개발자 기준) |
|
||||
|대표 앱| 페이스북, 인스타그램, 핀터레스트 등 | 알리바바, 구글 애드센스, 리플렉틀리 등 |
|
||||
|장점| - 저변이 넓은 자바스크립트 생태계 | - 다양한 위젯 |
|
||||
| | - 웹 개발자의 접근성 | - 강력한 애니메이션 기능 |
|
||||
| | - npm으로 많은 패키지 이용 가능 | - 블루투스 등 네이티브 하드웨어와의 연결성 |
|
||||
|단점| - 기본 위젯이 부족해 커스텀해서 사용 | - 플러터 SDK로 앱 크기가 큼(네이티브 대비) |
|
||||
| | - 안드로이드/iOS 네이티브 위젯을 이용하기에 OS 판올림에 따른 업데이트 필요 | - 아직 개발 생태계가 성숙하지 않아 빠른 피드백 얻기가 어려움 |
|
||||
| | - 블루투스 등 네이티브 커스텀해 통신하는 부분 개발이 어려움 | - 업데이트 주가가 빠름(분기별) |
|
||||
|최종 목표| 자바스크립트로 웹, 앱, 데스크톱 모든 플랫폼을 개발할 수 있는 통합 솔루션 개발 | 안드로이드, iOS, 웹, 윈도우 10 앱을 같은 코드로 개발할 수 있는 플랫폼 개발|
|
||||
|
||||
## 플러터가 주목받는 이유
|
||||
|
||||
플러터를 상징하는 대표적인 특징 3가지!
|
||||
|
||||
### 하나, 높은 개발 효율
|
||||
|
||||
플러터를 이용하면 안드로이드와 iOS 앱을 동시에 개발할 수 있어서 효율적입니다. 이렇게 개발된 앱은 어떤 운영체제에서도 똑같은 사용자 인터페이스와 사용자 경험(UX, user experience)을 제공합니다. 또한, 플러터의 **핫 리로드** (hot reload) 기능은 소스 수정 후 번거로운 빌드 과정 없이 결과 화면에 바로 표시해 주므로 개발 시간을 줄일 수 있습니다.
|
||||
|
||||
### 둘, 유연한 사용자 인터페이스
|
||||
|
||||
역동적이면서도 유연한 사용자 인터페이스는 플러터의 큰 장점입니다. 다양한 **위젯** (widget)을 제공하므로 사용자 맞춤형 앱을 쉽게 만들 수 있습니다. 만약 원하는 위젯이 없으면 선과 도형으로 직접 그려서 만들 수도 있습니다.
|
||||
또한, 강력한 애니메이션 기능을 제공하여 복잡한 계산식 없이 적은 노력으로 만족스러운 사용자 경험을 줄 수 있습니다. 플로터의 위젯을 활용하면 iOS에서 구글의 머터리얼 디자인이 적용된 앱을 만들거나 반대로 안드로이드에서 iOS스타일 앱을 개발할 수도 있습니다.
|
||||
> 플러터에서는 iOS 스타일의 위젯을 쿠퍼티노(cupertino)라고 부릅니다.
|
||||
|
||||
### 셋, 빠른 속도
|
||||
|
||||
플러터는 전체 화면을 그릴 때 **스키아** (skia) 엔진을 이용합니다. 예를 들어 배경은 노란색으로 하고 그 위에 아이콘을 그린다고 했을 때, 플러터는 노란색을 전체 화면에 칠한 다음 아이콘을 그리는 두 번의 작업을 한 번에 해서 초당 60프레임 이상의 속도로 화면을 갱신합니다.
|
||||
이처럼 빠르고 자연스러운 화면 전환 덕분에 네이티브 앱과 속도 차이를 거의 느낄 수 없습니다.
|
||||
> 스키아는 C++로 개발된 오픈소스 2D 그래픽 엔진으로 플러터뿐만 아니라 크롬, 안드로이드, 파이어폭스, 리브레오피스 등 다양한 플랫폼과 제품에서 사용되고 있습니다.
|
||||
|
||||
---
|
||||
|
||||
### 플러터 갤러리
|
||||
|
||||
[](https://gallery.flutter.dev/#/)
|
||||
|
||||
|
||||
-----
|
||||
|
||||
플러터의 주목도가 최근 로켓성장하는 이유가 다 있는것 같다. <br/>
|
||||
그래서 Dart 언어를 익히면서 플러터 공부를 해보려고 한다. <br/>
|
||||
496
src/content/blog/dev/flutter/2022-04-06-flutter-dart.md
Normal file
496
src/content/blog/dev/flutter/2022-04-06-flutter-dart.md
Normal file
@@ -0,0 +1,496 @@
|
||||
---
|
||||
title: Dart 언어
|
||||
date: 2022-04-06
|
||||
tags: flutter, 개발
|
||||
excerpt: 다트? 알아보자
|
||||
---
|
||||
# 플러터를 위한 필수! 다트를 알자!
|
||||
|
||||
* toc
|
||||
{:toc .large-only}
|
||||
|
||||
플러터는 다트(Dart)라는 프로그래밍 언어로 개발됐습니다. 따라서 플러터를 사용하려면 다트라는 새로운 언어를 알아야 합니다.
|
||||
다트 홈페이지에는 `"자바나 C# 개발자라면 하루면 배울 수 있다."` 라고 소개하는 것처럼 다트는 생각보다 어렵지 않은 언어입니다.
|
||||
|
||||
다트 언어의 철학은 "간단하게 배워서 다양한 플랫폼에 써먹자!" 입니다. 지금 다트를 익혀 두면 모바일 앱뿐만 아니라 서버와 웹 프런트엔드, 데스크톱 앱을 만들 수도 있습니다.
|
||||
다만, 플러터가 주제이므로 다트를 전문적으로 배우지는 않고 핵심 내용만 간략하게 다룰 예정입니다.
|
||||
|
||||
## 다트(Dart)!
|
||||
|
||||
다트는 구글이 Web Front-end 구현을 목적으로 개발한 프로그래밍 언어로 2011년 10월에 공개되었습니다.
|
||||
다트는 마치 카멜레온처럼 어떻게 활용하느냐에 따라 서버나 웹, 앱을 만들 때 사용할 수 있습니다.
|
||||
|
||||
### 다트 언어의 9가지 특징
|
||||
|
||||
다트는 다른 언어와 비교해 9가지 두드러진 특징이 있습니다.
|
||||
|
||||
1. 다트는 main() 함수로 시작합니다.
|
||||
2. 다트는 어디에서나 변수를 선언하고 사용할 수 있습니다.
|
||||
3. 다트에서는 모든 변수가 객체입니다. 그리고 모든 객체는 Object 클래스를 상속받습니다.
|
||||
4. 다트는 자료형이 엄격한 언어입니다. 이 말은 변수에 지정한 자료형과 다른 유형의 값을 저장하면 오류가 발생한다는 의미입니다. 만약 여러 자료형을 허용하려면 dynamic 타입을 이용할 수 있습니다.
|
||||
5. 다트는 제네릭 타입을 이용해 개발할 수 있습니다. 그리고 `List<int>`처럼 int형을 넣을 수도 있고, `List<dynamic>`처럼 다양한 데이터를 넣을 수도 있습니다.
|
||||
6. 다트는 public, protected 같은 키워드가 없습니다. 만약 외부로 노출하고 싶지 않다면 변수나 함수 이름 앞에 언더스코어(_)를 이용해 표시할 수 있습니다.
|
||||
7. 변수나 함수의 시작은 언더스코어 또는 문자열로 시작하고 그 이후에 숫자를 입력할 수 있습니다.
|
||||
8. 다트는 삼항 연산자를 사용할 수 있습니다.
|
||||
9. Null safety를 지원합니다. 이는 2.0에서 새롭게 추가된 기능으로, Null safety를 이용하면 컴파일 전에 널 예외(Null Exception)를 알 수 있으므로 널에 대한 오류가 발생하지 않도록 작업할 수 있습니다.
|
||||
|
||||
#### 8) 삼항연산자
|
||||
|
||||
다음 코드에서 첫 번째 줄을 보면 isPublic이 참이면 "public", 참이 아니면 "private"를 반환하여 visibility에 지정합니다. 두 번째 줄은 매개변수로 전달받은 name이 null이면 "Guest"를 반환하고, 아니면 매개변수로 전달 받은 값을 그대로 반환합니다.
|
||||
```dart
|
||||
var visibility = isPublic ? 'public' : 'private';
|
||||
String playerName(String name) => name ?? 'Guest';
|
||||
```
|
||||
|
||||
### 간단한 코드로 다트의 특징 이해하기
|
||||
|
||||
다트로 만든 프로그램의 시작점은 자바나 C처럼 **main()** 함수입니다.
|
||||
|
||||
```dart
|
||||
// 함수 정의
|
||||
printInteger(int aNumber) {
|
||||
print('The number is $aNumber.'); // 콘솔에 출력
|
||||
}
|
||||
|
||||
// main() 함수에서 시작
|
||||
main() {
|
||||
var number = 42; // 동적 타입 변수 지정
|
||||
printInteger(number); // 함수 호출
|
||||
}
|
||||
```
|
||||
```console
|
||||
결과 >
|
||||
The number is 42.
|
||||
```
|
||||
> `var 키워드로 변수를 선언하면 해당 변수에 저장되는 값의 유형에 따라 자료형이 정해집니다. 이것을 자료형 추론(type inference)이라고 합니다.`
|
||||
|
||||
다트에서는 문자열을 표현할 때는 큰따옴표나 작은따옴표를 이용하는데, 이때 따옴표 안에 **`${표현식}`**과 같은 형태로 사용하면 표현식에 변수를 직접 넣을 수 있습니다.
|
||||
|
||||
| 구분 | 자료형 | 설명 |
|
||||
|:---:|:----:|:-----:|
|
||||
| 숫자 | int | 정수형 숫자 |
|
||||
| | double | 실수형 숫자 |
|
||||
| | num | 정수형 또는 실수형 숫자 |
|
||||
|문자열| String | 텍스트 기반 문자 |
|
||||
|논리형| bool | True나 false |
|
||||
| 자료형 추론 | var | 입력받은 값에 따라 자료형 결정. 한 번 결정된 자료형은 변경 불가 |
|
||||
| | dynamic | 입력받은 값에따라 자료형 결정. 다른 변수 입력하면 자료형 변경 가능 |
|
||||
|
||||
|
||||
### Null safety
|
||||
|
||||
Null safety를 사용하려면 pubspec.yaml 파일의 SDK 환경을 변경해야 합니다. 다음과 같이 2.12.0 버전 이상부터 Null safety를 지원합니다.
|
||||
```yaml
|
||||
enviroment:
|
||||
sdk: ">=2.12.0 <3.0.0"
|
||||
```
|
||||
> [버전 표기 이해](https://gahusb.github.io/devlog/web-npmcarrot.html)
|
||||
|
||||
변수를 선언할 때 사용하는 것으로, 자료형 다음에 `?`를 붙이면 Null이 가능하고 붙이지 않으면 Null이 불가능합니다. 그리고 식 다음에 `!`를 붙이면 Null이 아님을 직접 표시합니다.
|
||||
|
||||
```dart
|
||||
int? couldReturnNullButDoesnt() => -3;
|
||||
|
||||
void main() {
|
||||
int? couldBeNullButIsnt = 1; // null로 변경 가능
|
||||
List<int?> listThatCouldHoldNulls = [2, null, 4]; // List의 int에 null 값 포함 가능
|
||||
List<int>? nullsList; // List 자체가 null일 수 있음
|
||||
int a = couldBeNullButIsnt; // null을 넣으면 오류
|
||||
int b = listThatCouldHoldNulls.first; // int b는 ?가 없으므로 오류
|
||||
int b = listThatCouldHoldNulls.first!; // null이 아님을 직접 표시
|
||||
int c = couldReturnNullButDoesnt().abs(); // null일 수도 있으므로 abs()에서 오류
|
||||
int c = couldReturnNullButDoesnt()!.abs(); // null이 아님을 직접 표시
|
||||
|
||||
print('a is $a.');
|
||||
print('b is $b.');
|
||||
print('c is $c.');
|
||||
}
|
||||
```
|
||||
|
||||
Null safety를 사용하는 이유는 프로그램 실행 중 널 예외가 발생하면 프로그램이 중지되는데, 이를 코드 단계에서 구분하여 작성할 수 있도록 하기 위해서입니다. 이런 이유로 요즘 나오는 언어 중에는 Null safety를 제공하는 언어가 많습니다.
|
||||
|
||||
### 다트가 제공하는 키워드
|
||||
|
||||
| 키워드 | - | - | - |
|
||||
| :--: |:--:|:--:|:--:|
|
||||
| abstract | dynamic | implements | show |
|
||||
| as | else | import | static |
|
||||
| assert | enum | in | super |
|
||||
| async | export | interface | switch |
|
||||
| await | extends | is | sync |
|
||||
| break | external | library | this |
|
||||
| case | factory | mixin | throw |
|
||||
| catch | false | new | true |
|
||||
| class | final | null | try |
|
||||
| const | finally | on | typedef |
|
||||
| continue | for | operator | var |
|
||||
| convariant | Function | part | void |
|
||||
| default | get | rethrow | while |
|
||||
| deferred | hide | return | with |
|
||||
| do | if | set | yield |
|
||||
|
||||
> [다트가 제공하는 키워드](https://dart.dev/guides/language/language-tour#keywords)
|
||||
|
||||
---
|
||||
## 비동기 처리 방식
|
||||
|
||||
다트는 비동기 처리를 지원하는 언어입니다. 비동기(asynchronous)란 언제 끝날지 모르는 작업을 기다리지 않고 다음 작업을 처리하게 하는 것을 의미합니다. 만약 비동기를 지원하지 않고 동기(synchronous)로만 처리한다면 어떤 작업이 오래 걸릴 경우 사용자는 실행이 멈춘 것으로 생각하고 프로그램을 종료할 수 있습니다. 일반적으로 네트워크에서 데이터를 가져오거나 데이터베이스 쓰기, 파일 읽기 등의 작업은 상황에 따라 언제 끝날지 알 수 없으므로 비동기로 처리합니다.
|
||||
|
||||
|
||||
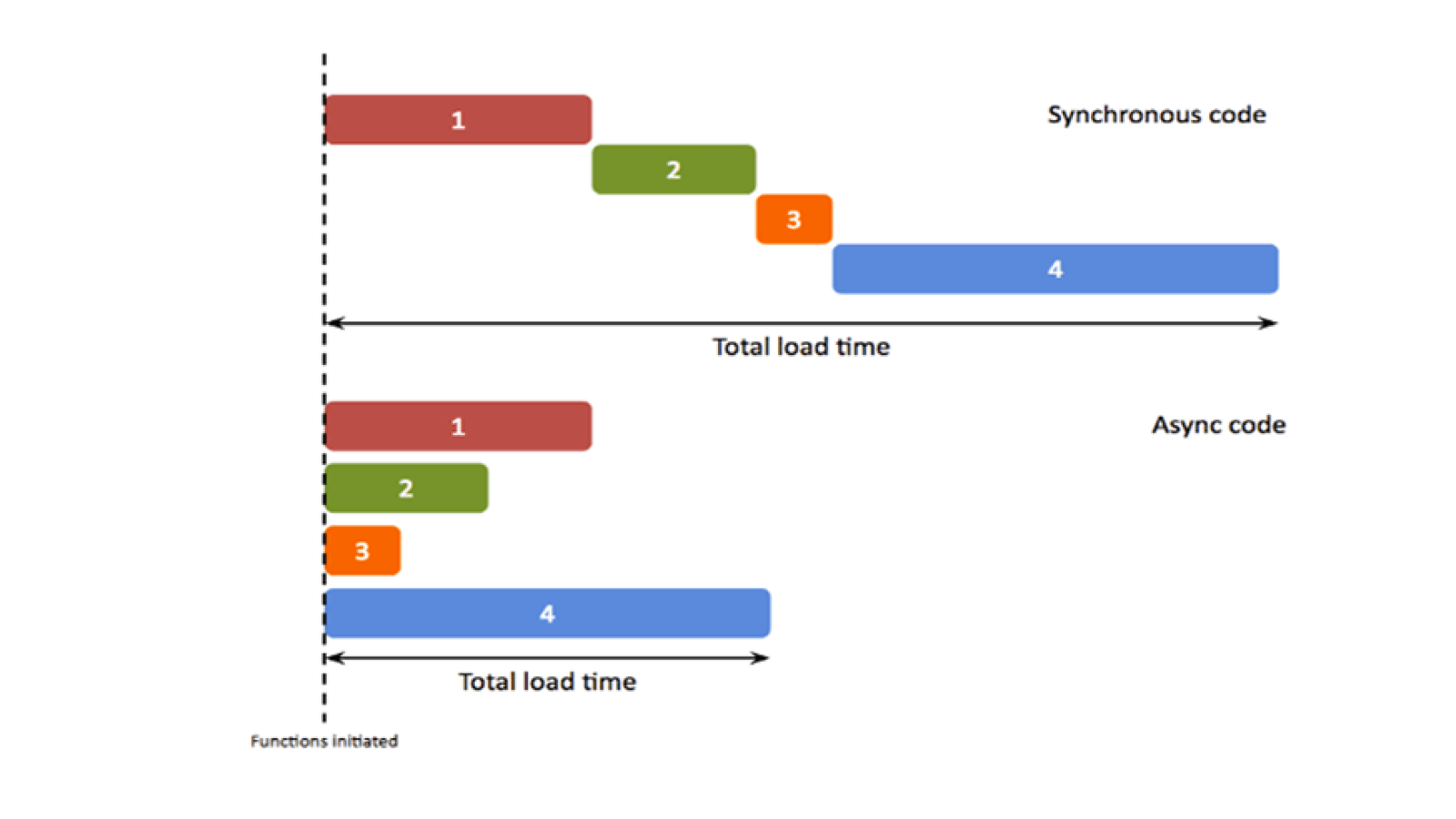 <sup>[1](#footnote_1)</sup>
|
||||
<a name="footnote_1">1</a>: 출처: DEV.to
|
||||
|
||||
### 비동기 프로세스의 작동 방식
|
||||
|
||||
다트는 async와 await 키워드를 이용해 비동기 처리를 구현합니다.
|
||||
1. 함수 이름 뒤, 본문이 시작하는 중괄호 `{` 앞에 async 키워드를 붙여 비동기로 만든다.
|
||||
2. 비동기 함수 안에서 언제 끝날지 모르는 작업 앞에 await 키워드를 붙인다.
|
||||
3. 2번 작업을 마친 결과를 받기 위해 비동기 함수 이름 앞에 Future(값이 여러 개면 Stream) 클래스를 지정한다.
|
||||
|
||||
다음 예시를 보겠습니다.
|
||||
|
||||
```dart
|
||||
void main() {
|
||||
checkVersion();
|
||||
print('end process');
|
||||
}
|
||||
Future checkVersion() async {
|
||||
var version = await lookUpVersion();
|
||||
print(version);
|
||||
}
|
||||
|
||||
int lookUpVersion() {
|
||||
return 12;
|
||||
}
|
||||
```
|
||||
|
||||
일반적인 생각으로 코드를 보면 main() 함수에서 제일 먼저 checkVersion() 함수를 호출했으므로 checkVersion() 함수에 있는 lookUpVersion() 함수가 호출되어 12를 전달받아 출력한 다음, 다시 main()으로 돌아와서 'end process'가 출력될 것 같습니다. 하지만 결과는 다음과 같습니다.
|
||||
|
||||
```console
|
||||
실행 결과 >
|
||||
end process
|
||||
12
|
||||
```
|
||||
|
||||
이러한 결과가 나오는 이유는 먼저 checkVersion() 함수를 보면 이름 앞뒤로 Future와 async가 붙었습니다. 이렇게 하면 checkVersion() 함수를 비동기로 만들겠다는 의미입니다. 즉, checkVersion() 함수 안에 await가 붙은 함수를 비동기로 처리한 다음 그 결과는 Future 클래스에 저장해 둘 테니 먼저 checkVersion() 함수를 호출한 main() 함수의 나머지 코드를 모두 실행하라는 의미입니다. 그리고 main() 함수를 모두 실행했으면 그때 Future 클래스에 저장해 둔 결과를 이용해서 checkVersion() 함수의 나머지 코드를 실행합니다.
|
||||
|
||||
앞선 코드에서 lookUpVersion() 함수 앞에 await 키워드가 붙었습니다. await 키워드는 처리를 완료하고 결과를 반환할 때까지 이후 코드의 처리를 멈춥니다. 따라서 lookUpVersion() 함수를 호출해 version 변수에 12가 저장된 다음에야 비로소 print(version) 문으로 이를 출력합니다.
|
||||
이처럼 비동기 함수에서 어떤 결과값이 필요하다면 해당 코드를 await로 지정합니다. 그러면 네트워크 지연 등으로 제대로 된 값을 반환받지 못한 채 이후 과정이 실행되는 것을 방지할 수 있습니다.
|
||||
|
||||
이러한 비동기 처리를 이용하면 지연이 발생하는 동안 애플리케이션이 멈춰 있지 않고 다른 동작을 하게 할 수 있습니다.
|
||||
|
||||
### 비동기 함수가 반환하는 값 활용하기
|
||||
|
||||
비동기 함수가 반환하는 값을 처리하려면 then() 함수를 이용합니다.
|
||||
|
||||
```dart
|
||||
void main() async {
|
||||
await getVersionName().then((value) => {
|
||||
print(value);
|
||||
});
|
||||
print('end process');
|
||||
}
|
||||
|
||||
Future<String> getVersionName() async {
|
||||
var versionName = await lookUpVersionName();
|
||||
return versionName;
|
||||
}
|
||||
|
||||
String lookUpVersionName() {
|
||||
return 'Android Q';
|
||||
}
|
||||
```
|
||||
```console
|
||||
실행 결과 >
|
||||
Android Q
|
||||
end process
|
||||
```
|
||||
|
||||
코드를 보면 Future<String>이라는 반환값을 정해 놓은 getVersionName() 이라는 함수가 있습니다. 이 함수는 async 키워드가 붙었으므로 비동기 함수입니다. 이처럼 비동기 함수가 데이터를 성공적으로 반환하면 호출하는 쪽에서 then() 함수를 이용해 처리할 수 있습니다.
|
||||
|
||||
then() 이외에 error() 함수도 이용할 수 있습니다. error() 함수는 실행 과정에서 오류가 발생했을 때 호출되므로 이를 이용해 예외를 처리할 수 있습니다.
|
||||
|
||||
### 다트와 스레드
|
||||
|
||||
다트는 **하나의 스레드(thread)로 동작**하는 프로그래밍 언어입니다. 그래서 await 키워드를 잘 사용해야 합니다.
|
||||
|
||||
```dart
|
||||
void main() {
|
||||
printOne();
|
||||
printTwo();
|
||||
printThree();
|
||||
}
|
||||
|
||||
void printOne() {
|
||||
print('One');
|
||||
}
|
||||
|
||||
void printThree() {
|
||||
print('Three');
|
||||
}
|
||||
|
||||
void printTwo async {
|
||||
Future.delayed(Duration(seconds: 1), () {
|
||||
print('Future!!');
|
||||
});
|
||||
print('Two');
|
||||
}
|
||||
```
|
||||
```console
|
||||
실행 결과 >
|
||||
One
|
||||
Two
|
||||
Three
|
||||
Future!!
|
||||
```
|
||||
'One' 출력 이후에 printTwo() 함수에 진입하면 Future를 1초 지연했으므로 async로 정의한 비동기 함수의 특징에 대해 'Two'가 먼저 출력됩니다. 그리고 'Three'를 출력하고 'Future!!'가 가장 늦게 출력됩니다.
|
||||
|
||||
이때, printTwo() 함수를 다음과 같이 수정한다면?
|
||||
```dart
|
||||
void printTwo() async {
|
||||
await Future.delayed(Duration(seconds: 2), () {
|
||||
print('Future Method');
|
||||
});
|
||||
print('Two');
|
||||
}
|
||||
```
|
||||
Future.delayed() 코드 앞에 await 키워드를 붙였으므로 이후 코드의 실행이 멈춥니다.
|
||||
따라서 printTwo() 함수를 벗어나 main() 함수의 나머지 코드를 모두 실행하고, 그 다음에 await가 붙은 코드부터 차례대로 실행합니다.
|
||||
```console
|
||||
실행 결과 >
|
||||
One
|
||||
Three
|
||||
Future Method
|
||||
Two
|
||||
```
|
||||
이처럼 await 키워드를 이용하면 await가 속한 함수를 호출한 쪽의 프로세스가 끝날 때까지 기다리기 때문에 이를 잘 고려해서 프로그램을 작성해야 합니다.
|
||||
|
||||
---
|
||||
|
||||
## JSON 데이터 주고 받기
|
||||
|
||||
애플리케이션을 개발하다 보면 서버와의 통신이 중요하다는 것을 알게 됩니다. 대부분 앱은 서버와 데이터를 주고 받으며 상호 작용하고 화면에 필요한 데이터를 출력합니다. 이러한 데이터를 교환할 때 가장 많이 쓰는 형식이 **JSON**입니다.
|
||||
직접 문자열 형태나 XML을 이용해 데이터를 주고 받기도 하지만, 가장 편리하면서 파일 크기도 작은 JSON 형식을 주로 이용합니다. 다트에서는 이러한 JSON 통신을 간편하게 이용할 수 있습니다.
|
||||
JSON을 사용하려면 소스에 convert라는 라이브러리를 포함해야 합니다.
|
||||
```dart
|
||||
import 'dart:conver';
|
||||
|
||||
void main() {
|
||||
var jsonString = '''
|
||||
[
|
||||
{"score": 40},
|
||||
{"score": 80}
|
||||
]
|
||||
''';
|
||||
var scores = jsonDecode(jsonString);
|
||||
print(scores is List); // true
|
||||
var firstScore = scores[0];
|
||||
print(firstScore is Map); // true
|
||||
print(firstScore['score'] == 40); // true
|
||||
}
|
||||
```
|
||||
위 코드에서 jsonString 변수에 저장된 데이터가 JSON을 형태의 문자열입니다. 이 데이터를 convert 라이브러리에 있는 jsonDecode() 함수에 전달한 후 그 결과를 scores 변수에 저장했습니다. jsonDecode() 함수는 JSON 형태의 데이터를 dynamic 형식의 리스트로 변환해서 반환해 줍니다.
|
||||
scores 변수가 리스트인지는 True/False로 점검할 수 있습니다.
|
||||
|
||||
그리고 scores 리스트에서 첫 번째 값을 firstScore에 저장합니다. 이 값은 키(key)와 값(values)이 있는 Map 형태입니다. print(firstScore['score'] == 40) 코드는 firstScore 데이터의 score 키에 해당하는 값이 40이라는 것을 나타냅니다. 이처럼 jsonDecode() 함수를 이용하면 서버에서 JSON 데이터를 받아서 사용할 수 있습니다.
|
||||
|
||||
이제 애플리케이션에서 서버로 데이터를 보내는 예도 살펴보겠습니다. 이때는 jsonEncode() 함수를 이용해 JSON 형태로 변환한 데이터를 서버로 보낼 수 있습니다.
|
||||
|
||||
```dart
|
||||
import 'dart:convert';
|
||||
|
||||
void main() {
|
||||
var scores = [
|
||||
{'score': 40},
|
||||
{'score': 80},
|
||||
{'score': 100, 'overtime': true, 'special_guest': null},
|
||||
];
|
||||
|
||||
var jsonText = jsonEncode(scores);
|
||||
print(jsonText ==
|
||||
'[{"score": 40},{"score": 80},'
|
||||
'{"score": 100, "overtime": true,'
|
||||
'"special_guest": null}]'); // true 출력
|
||||
}
|
||||
```
|
||||
|
||||
scores 데이터는 배열로 이루어졌고 각 항목은 score값으로 구성되며 마지막 항목에는 overtime과 special_guest값을 추가했습니다.
|
||||
앞의 코드에서는 {"score": 40}처럼 키에 큰따옴표를 사용해 JSON 데이터임을 표시했고, 지금 코드는 {'score': 40}처럼 작은따옴표를 이용해 변수임을 표시했습니다.
|
||||
|
||||
이 scores 데이터를 인자로 jsonEncode() 함수를 호출하면 키값이 큰따옴표로 묶이고 전체 데이터를 작은따옴표로 한 번 묶어서 JSON 형태의 데이터가 됩니다.
|
||||
이처럼 다트는 간단하게 JSON을 만들고 파싱하여 데이터를 주고받는 기능을 제공합니다.
|
||||
|
||||
---
|
||||
|
||||
## 스트림 통신하기
|
||||
|
||||
애플리케이션을 개발하다 보면 데이터를 순서대로 주고받아야 할 때가 있습니다. 데이터를 순서대로 주고받을 것으로 생각해서 화면을 구성했는데 네트워크나 와이파이 연결이 끊기거나 특정 API 호출이 늦어져 순서가 달라지면 애플리케이션이 원하는 흐름대로 작동하지 않을 수도 있습니다.
|
||||
|
||||
이처럼 순서를 보장받고 싶을 때 스트림(stream)을 이용합니다.
|
||||
스트림은 처음에 넣은 데이터가 꺼낼 때도 가장 먼저 나오는 데이터 구조로 생각할 수 있습니다. 따라서 스트림을 이용하면 데이터를 차례대로 주고받는 코드를 작성할 수 있습니다.
|
||||
|
||||
```dart
|
||||
import 'dart:async';
|
||||
|
||||
Future<int> sumStream(Stream<int> stream) async {
|
||||
var sum = 0;
|
||||
await for (var value in stream) {
|
||||
print('sumStream : $value');
|
||||
sum += value;
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
|
||||
Stream<int> countStream(int to) async* {
|
||||
for (int i = 0; i <= to; i++) {
|
||||
print('countStream : $i');
|
||||
yield i;
|
||||
}
|
||||
}
|
||||
|
||||
main() async {
|
||||
var stream = countStream(10);
|
||||
var sum = await sumStream(stream);
|
||||
print(sum); // 55
|
||||
}
|
||||
```
|
||||
|
||||
main() 함수를 살펴보면 먼저 countStream(10) 함수를 호출합니다. 이 함수는 async*dhk yield 키워드를 이용해 비동기 함수로 만들었습니다. 이 함수는 for 문을 이용해 1부터 int형 매개변수 to로 전달받은 숫자까지 반복합니다.
|
||||
|
||||
async* 명령어는 앞으로 yield를 이용해 지속적으로 데이터를 전달하겠다는 의미입니다. 위 코드에서 yield는 int형 i를 반환하는데, return은 한 번 반환하면 함수가 끝나지만 yield는 반환 후에도 계속 함수를 유지합니다.
|
||||
|
||||
이렇게 받은 yield값을 인자ㅗ sumStream() 함수를 호출하면 이 값이 전달될 때마다 sum 변수에 누적해서 반환해 줍니다. 그리고 main() 함수에서 이 값을 받아서 출력하면 55가 나옵니다.
|
||||
출력 결과를 보면 함수가 어떤 흐름으로 진행되는지 알 수 있을겁니다.
|
||||
|
||||
```console
|
||||
실행 결과 >
|
||||
countStream : 1
|
||||
sumStream : 1
|
||||
countStream : 2
|
||||
sumStream : 2
|
||||
...
|
||||
countcountStream : 9
|
||||
sumStream : 9
|
||||
countStream : 10
|
||||
sumStream : 10
|
||||
55
|
||||
```
|
||||
이처럼 스트림을 이용하면 데이터를 차례대로 받아서 처리할 수 있습니다.
|
||||
|
||||
아니면 then() 함수를 이용해 스트림 코드를 작성할 수도 있습니다.
|
||||
```dart
|
||||
main() {
|
||||
var stream = Stream.fromIterable([1, 2, 3, 4, 5]);
|
||||
|
||||
// 가장 앞의 데이터 결과: 1
|
||||
stream.first.then((value) => print('first: $value'));
|
||||
// 가장 마지막 데이터의 결과 : 5
|
||||
stream.last.then((value) => print('last: $value'));
|
||||
// 현재 스트림이 비어 있는지 확인: false
|
||||
stream.isEmpty.then((value) => print('isEmpty: $value'));
|
||||
// 전체 길이: 5
|
||||
stream.length.then((value) => print('length: $value'));
|
||||
}
|
||||
```
|
||||
코드를 보면 Stream클래스를 이용해 배열을 하나 만든 후 함수를 이용해서 값을 가져옵니다.
|
||||
그런 다음 then() 함수로 가져다 사용합니다.
|
||||
그런데 이 코드는 그대로 실행하면 오류가 발생합니다. 일단 스트림을 통해 데이터를 사용하면 데이터는 사라지기 때문입니다. 따라서 다음처럼 한 번만 실행하도록 변경해야 합니다.
|
||||
|
||||
```dart
|
||||
main() {
|
||||
var stream = Stream.fromIterable([1, 2, 3, 4, 5]);
|
||||
|
||||
// 가장 마지막 데이터의 결과: 5
|
||||
stream.last.then((value) => print('last: $value'));
|
||||
}
|
||||
```
|
||||
|
||||
스트림은 실시간으로 서버를 살펴보다가 서버에서 데이터가 변경되면 화면을 새로 고침하지 않더라도 자동으로 변경된 데이터가 반영되어야 할 때 사용할 수 있는 유용한 클래스입니다.
|
||||
|
||||
---
|
||||
|
||||
## 다트 프로그램 만들기
|
||||
### 1. 구구단 프로그램 작성하기
|
||||
```dart
|
||||
void main() {
|
||||
for(int i = 0; i <= 9; i++) {
|
||||
for(int j = 0; j <=9; j++) {
|
||||
print('$i * $j = ${i * j}');
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 2. 자동차 클래스 구현하기
|
||||
다음과 같은 속성을 포함하는 클래스를 만들어 봅니다.
|
||||
| 이름 | 자료형 | 의미 |
|
||||
|:---:|:----:|:---:|
|
||||
|maxSpeed|int|최고 속도|
|
||||
|price|num|가격|
|
||||
|name|String|이름|
|
||||
|
||||
Car 클래스 안에 saleCar()라는 이름으로 함수를 작성합니다. 이 함수는 자동차 가격을 10% 할인해서 반환합니다. 그리고 main() 함수에서 Car 클래스를 이용해 다음과 같은 속성값으로 3종류의 자동차를 선언합니다. 새로운 객체를 선언할 때 자바에선는 new라는 키워드를 사용하지만 다트에서는 생략할 수 있습니다. 물론 사용해도 무방합니다.
|
||||
|
||||
|maxSpeed|price|name|
|
||||
|:----:|:----:|:----:|
|
||||
|320|100000|BMW|
|
||||
|250|70000|BENZ|
|
||||
|200|80000|FORD|
|
||||
|
||||
BMW를 3번 할인하는 함수를 호출한 뒤에 차량 가격을 출력해봅니다.
|
||||
|
||||
```dart
|
||||
void main() {
|
||||
Car bmw = Car(320, 100000, BMW);
|
||||
Car benz = Car(250, 70000, BENZ);
|
||||
Car ford = Car(200, 80000, FORD);
|
||||
|
||||
bmw.saleCar();
|
||||
bmw.saleCar();
|
||||
bmw.saleCar();
|
||||
print(bmw.price);
|
||||
}
|
||||
|
||||
class Car {
|
||||
int maxSpeed;
|
||||
num price;
|
||||
String name;
|
||||
|
||||
Car(int maxSpeed, num price, String name) {
|
||||
this.maxSpeed = maxSpeed;
|
||||
this.price = price;
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
num saleCar() {
|
||||
price = price * 0.9;
|
||||
return price;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3. 로또 번호 생성기
|
||||
무작위 수를 생성하는 랜덤 함수를 이용하려면 dart:math 라이브러리를 사용해야 합니다.
|
||||
<code>import 'dart:math' as math;</code>
|
||||
as math 코드는 import한 dart:math 라이브러리를 math라는 이름으로 사용하겠다는 의미입니다. 이 math를 이용해 6개의 무작위 수를 만드는 로또 번호 생성기를 만들어 봅시다. 만약, 생성한 번호가 중복일 경우에는 다시 생성합니다.
|
||||
|
||||
```dart
|
||||
import 'dart:collection';
|
||||
import 'dart:math' as math;
|
||||
|
||||
void main() {
|
||||
var rand = math.Random();
|
||||
HashSet<int> lotteryNumber HashSet();
|
||||
|
||||
while(lotteryNumber.length < 6) {
|
||||
lotteyNumber.add(rand.nextInt(45) + 1);
|
||||
}
|
||||
print(lotteryNumber);
|
||||
}
|
||||
```
|
||||
```console
|
||||
실행 결과 >
|
||||
{2, 9, 13, 24, 33, 42}
|
||||
```
|
||||
|
||||
HashSet를 사용하려면 dart:collection이라는 라이브러리를 import해야 합니다.
|
||||
47
src/content/blog/dev/sideprojects/2022-11-01-glotto.md
Normal file
47
src/content/blog/dev/sideprojects/2022-11-01-glotto.md
Normal file
@@ -0,0 +1,47 @@
|
||||
---
|
||||
title: GLotto
|
||||
date: 2022-11-01
|
||||
tags: sideprojects, 개발
|
||||
excerpt: GLotto 추첨기에 대한 아이디어
|
||||
---
|
||||
# 사이드 프로젝트 - GLotto 추첨기
|
||||
## GLotto 개요
|
||||
|
||||
사이드 프로젝트를 시작하면서 제일 먼저 만들어볼 수 있는게 무엇이 있을까 생각해보았다. <br />
|
||||
그래서 생각한게 로또 추첨기를 이전 데이터를 통계적 기반으로 추첨해주는 추첨기를 만들어보면 어떨까라고 생각을 해보았다. <br />
|
||||
|
||||
사실 로또라는게 독립적 수행이기 때문에 이전의 결과가 이후의 결과에 영향을 미치지는 않다는것을 알지만 이것을 통계적으로 누적된 데이터를 활용하여 번호를 뽑아낼 수 있다면 어떨까라고 생각하면서 시작하게 되었다. <br />
|
||||
이전의 데이터를 학습시키고 이 데이터를 기반으로 통계에 근거하여 좀 더 맞아 떨어지는 번호를 생성해내면 어떨까라는게 아이디어의 시작이었다. <br />
|
||||
|
||||
---
|
||||
|
||||
## 설계
|
||||
- 클라이언트 : 안드로이드 어플리케이션
|
||||
- 서버 : 스프링 서버
|
||||
- 데이터베이스 : mariaDB
|
||||
|
||||
간단히 언제든지 들고다니면서 번호를 받을 수 있고, 이것으로 수익성을 낼 수 있는 방법이 뭐가 있을까 고민하다보니 안드로이드에 출시하여 사용해보면 어떨까 생각해보았다. 안드로이드 앱 출시 경험도 해보고, 서버와 데이터베이스를 연동하여 이전 실제 데이터들은 서버에 계속해서 누적하면서 만들어내는 것이다.
|
||||
|
||||
Synology NAS를 활용하여 Spring Server를 구동하고, MariaDB를 구축하여 해당 서비스를 구현하고자 한다.<br />
|
||||
(진작에 이렇게 좀 활용해보지 NAS사고 지금까지 그냥 저장소로만 사용하다니 멍충..)
|
||||
|
||||
---
|
||||
|
||||
## 구현
|
||||
### 클라이언트
|
||||
이 사이드 프로젝트를 제일 먼저 하게된 이유는 앞으로 사이드 프로젝트를 만들기 위해 포토샵을 필수적으로 배울수밖에 없게 되었는데, 가장 간단하게 UI를 뽑아낼 수 있을것 같아서이다.
|
||||
|
||||
그냥 로또 공만 그려서 번호를 뿌려주거나 로또 용지를 그려서 위에 뿌려주면 되니 참 쉽지 않은가? <br />
|
||||
그 외에 다른 앱적인 요소는 Material 3.0을 적극 활용해보려고 한다. <br />
|
||||
|
||||
### 서버
|
||||
사실 제일 걱정되는 부분이 이 부분이었다. 나만의 서버를 구축하여 서비스를 만들어낸다는것 자체가 경험이 많이 부족하고, 이전에 배웠던 Spring 내용은 내 머릿속에 거의 남아있지 않았기 때문이랄까....? <br />
|
||||
그래도 NAS에 Spring war를 올려서 구동할 수 있게끔 제공하고 있어서 다행이었다. <br />
|
||||
서버를 따로 구입하기에는 좀...😕<br />
|
||||
|
||||
### 데이터베이스
|
||||
데이터베이스는 NAS에 MediaWiki를 만들어본 경험이 있었기 때문에 MariaDB를 그대로 사용하기로 했다. 그나마 알고 있는게 SQL문이기 때문에 적극적으로 활용할 수 있고, 사실 추첨 번호만 저장하면 되기 때문에 그리 복잡하지도 않다. <br />
|
||||
CRUD만 구현해두면 앞으로 변동 가능한 부분도 많고, 손 쉽게 활용할 수 있을것 같았다. <br />
|
||||
|
||||
대충 위에서 정리한대로 진행 할 예정이고, 가능하면 구현하면서 새롭게 배운 내용들도 같이 정리하려고 한다. <br />
|
||||
사이드 프로젝트 가보자구우~~~!
|
||||
@@ -0,0 +1,28 @@
|
||||
---
|
||||
title: 사이드 프로젝트 시작?!
|
||||
date: 2022-11-01
|
||||
tags: sideprojects, devlog, ??
|
||||
excerpt: 사이드 프로젝트 시작?!
|
||||
---
|
||||
# 사이드 프로젝트 시작?!
|
||||
## 사이드 프로젝트를 시작하게된 계기
|
||||
사실 사이드 프로젝트를 시작하려고 생각하고 메모 했던 내용은 늘 있었다. 그럼에도 시간이 없다는 핑계로.. 아이디어가 없다는 핑계로.. 처음부터 만들어 볼 여유가 좀처럼 생기지 않았다.<br />
|
||||
그래도 뭔가 작은 프로젝트를 만들기 시작하고, 회사 일에도 여유가 생기고부터 만들어보고 싶었던것들을 리스트화하고 이것을 정리하면서 만들어갈 필요성을 느꼈다.<br />
|
||||
뭐, 이것도 결국에는 내 경험치가 될 것이니까?
|
||||
|
||||
## 사이드 프로젝트 계획
|
||||
- 리스트 업
|
||||
- 실현 가능성을 기반으로 우선순위 정리
|
||||
- 설계
|
||||
- 프로젝트 별 관리
|
||||
|
||||
## 리스트 업
|
||||
중간 중간 생각나는대로 리스트업을 업데이트 할 예정인데 우선 정리한것들은 이렇다.<br />
|
||||
|
||||

|
||||
|
||||
NAS Note에 정리한 아이디어의 일부인데 진작에 좀 활용할껄 너무 늦은거 아니니.. <br />
|
||||
|
||||
## 계획
|
||||
우선적으로 포토샵을 아직 배우는중이기 때문에 UI작업이 제일 까다롭지 않을것 같은 로또앱을 출시해보려고 한다. <br />
|
||||
해당 내용은 다른 포스트로 업로드 할 예정이다.
|
||||
40
src/content/blog/dev/synology/2022-11-23-synology-start.md
Normal file
40
src/content/blog/dev/synology/2022-11-23-synology-start.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
title: Synology NAS 사용 정리
|
||||
date: 2022-11-23
|
||||
tags: synology, 개발
|
||||
excerpt: 시놀로지 NAS
|
||||
---
|
||||
## 왜 NAS?
|
||||
요즘에는 사람들이 NAS를 많이들 활용하고 있다.<br />
|
||||
NAS는 Network Attached Storage의 약자로 네트워크에 연결된 저장장치로 사람들이 흔히 쓰는 클라우드의 기능을 하고 있는 일종의 서버이다.
|
||||
|
||||
단순히 클라우드 서비스와 같이 저장소로 활용을 많이 하고 있지만, 그 뿐만이 아닌 서버 운영, DB, 공유 등의 다양한 기능을 제공하기도 한다. <br />
|
||||
또한 어디서든 외장하드 같은 것을 번거롭게 들고 다니지 않아도 된다. <br />
|
||||
이 부분이 내가 NAS를 구매한 이유 중 하나이다. <br />
|
||||
|
||||
사실 NAS를 구매한건 22년 05월로 사용한지는 벌써 반년이 지났지만 이제서야 글로 작성하면서 사용했던 방식이나 활용법을 글로 적어보려고 한다...ㅎ <br />
|
||||
구매한 이유는 가족들의 사진을 저장하고 어디서든 공유하면서 사용하기 위한 목적이 우선적이면서 무료 클라우드가 가득 찼기에 매달 요금을 내면서 사용하기 싫었기 때문에 큰 출혈이 있더라고 구매하였다. <br />
|
||||
|
||||
그러면서 더더욱 욕심을 내며 사이드 프로젝트를 위한 서버로도 활용하면 좋을 것 같다는 생각을 했기 때문에 관련 기능을 지원하는 NAS를 찾아보았다. <br />
|
||||
(실제로 이 글을 쓰는 지금 서버로 활용하여 개발한 프로젝트가 2~3개는 된다.)
|
||||
|
||||
## Synology
|
||||
여러가지 장비를 비교하며 찾아보다가 Synology 사의 장비를 구매하기로 결정했다. <br />
|
||||
그 이유는 DSM센터를 통해서 사용하기 편리한 UI를 제공하고 있으며, Synology사의 다양한 내부 패키지 기능을 활용하면 사용 범위성이 무궁무진하기 때문이다. <br />
|
||||
|
||||
현재 구매한 NAS는 DS220+ 2Bay 제품으로, 가격적으로도 그렇고 내가 원하는 기능 정도로만 사용하기에 적당한 제품이다. <br />
|
||||

|
||||
|
||||
내가 NAS를 사용하면서 현재 쓰고 있는 기능들은 아래와 같다. <br />
|
||||
> - DS Photo를 통해 가족들이랑 연결해서 모바일의 사진을 저장하고 공유하는 기능
|
||||
> - Video Station 기능을 통해 나만의 OTT 서비스
|
||||
> - 개인 파일들의 저장
|
||||
> - Note Station을 통한 나만의 노트 정리
|
||||
> - 웹 서비스 구동
|
||||
> - MariaDB 구동
|
||||
> - 안드로이드 앱을 위한 Spring 서버 (사이드 프로젝트)
|
||||
> - Docker 활용하기
|
||||
|
||||
이제와서 봐도 참 알차게 사용한것 같아서 뿌듯하네! <br />
|
||||
|
||||
이렇게 다양하게 활용하면서 익혔던 기능이나 까먹기 쉬운 기능들을 정리하려고 한다. <br />
|
||||
12
src/content/blog/ideas/2022-03-17-startideas.md
Normal file
12
src/content/blog/ideas/2022-03-17-startideas.md
Normal file
@@ -0,0 +1,12 @@
|
||||
---
|
||||
title: 아이디어나 기록 시작
|
||||
date: 2022-03-17
|
||||
tags: 아이디어
|
||||
excerpt: 아이디어나 생각 기록 포스트 시작
|
||||
---
|
||||
# 아이디어나 생각 기록 포스트 시작
|
||||
일상 기록하는 디렉토리를 만들고 나니 내 생각이나 아이디어가 떠오르면 작성할 수 있는 페이지가 있다면 좋을 것 같다는 생각이 들었다.
|
||||
|
||||
평소에 이런 저런 생각을 많이 하는 나는 좋은 생각이 떠오르다가도 메모장에 적던 습관이 부족해서 금방 잊곤 했는데, 그런 생각을 간단하게 적을 수 있다면 좋을 것 같아서 따로 분리하게 되었다.
|
||||
|
||||
이 디렉토리가 가득 찰 수 있다면 좋겠는걸..
|
||||
17
src/content/blog/study/algorithms/2022-03-08-firsttest.md
Normal file
17
src/content/blog/study/algorithms/2022-03-08-firsttest.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
title: 첫 번째 테스트
|
||||
date: 2022-03-08
|
||||
tags: algorithms, 공부
|
||||
excerpt: Study-Algorithms-test
|
||||
---
|
||||
# Study-Algorithms-test
|
||||
> 알고리즘을 공부하고 기록하는 페이지를 모아 놓는다.
|
||||
|
||||
### 작성되는 글
|
||||
이 디렉토리에는 알고리즘에 대해서 공부하고 내용을 정리하면서 내가 이해한 내용을 작성하는 저장소이다.
|
||||
|
||||
지금까지는 머리속으로 이해하고 그것을 활용하는 방식으로 공부를 했지만 성과가 항상 좋지만은 않았다.
|
||||
|
||||
그래서 내가 공부하고 이해한 내용을 바탕으로 글로 작성하면서 다시 한 번 떠올리고, 작성하면서 생각의 오류를 수정하고, 남에게 보여지는 글이기 때문에 정확히 알아야만 할 수 있다고 생각이 든다.
|
||||
|
||||
이 공간을 가득 채울 수 있도록 다시 한 번 다짐해 본다!
|
||||
7
src/content/blog/study/algorithms/2022-03-14-greedy.md
Normal file
7
src/content/blog/study/algorithms/2022-03-14-greedy.md
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
title: Greedy Algorithm
|
||||
date: 2022-03-14
|
||||
tags: algorithms, 공부
|
||||
excerpt: 그리디 알고리즘이란?
|
||||
---
|
||||
|
||||
215
src/content/blog/study/algorithms/2022-03-24-arraysort.md
Normal file
215
src/content/blog/study/algorithms/2022-03-24-arraysort.md
Normal file
@@ -0,0 +1,215 @@
|
||||
---
|
||||
title: Array Sort
|
||||
date: 2022-03-24
|
||||
tags: algorithms, 공부
|
||||
excerpt: sort에 대한 정리
|
||||
---
|
||||
# 각 언어별 sort에 대한 정리
|
||||
sort는 자주 사용하면서도 나중에 사용 할때마다 조금씩 헷갈리는 부분이라 정리해둘까 한다.
|
||||
|
||||
## JAVA
|
||||
자바에 여러가지 방식이 있다.
|
||||
- Comparator
|
||||
- Comparable
|
||||
- Lambda
|
||||
|
||||
### Comparator
|
||||
Comparator 방식으로 내가 자주 사용하는 방식이다.
|
||||
이 방식을 사용하면 개인적으로 내가 원하는 정렬 방식으로 변경하기도 간편하다고 생각하기 때문이다.
|
||||
|
||||
아래 코드를 보면
|
||||
|
||||
1차원 배열
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
import java.util.Comparator;
|
||||
|
||||
int N = 10;
|
||||
int[] arr = new int[N];
|
||||
|
||||
Arrays.sort(arr, new Comparator<Integer>) {
|
||||
@Override
|
||||
public int compare(Object o1, Object o2) {
|
||||
return o1 - o2; // 오름차순
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
2차원 배열
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
import java.util.Comparator;
|
||||
|
||||
int N = 10;
|
||||
int[][] arr = new int[N][N];
|
||||
|
||||
Arrays.sort(arr, new Comparator<int[]>) {
|
||||
@Override
|
||||
public int compare(int[] o1, int[] o2) {
|
||||
if(o1[0] == o2[0]) {
|
||||
return o1[1] - o2[1]; // 오름차순
|
||||
} else {
|
||||
return o1[0] - o2[0];
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
위 소스는 기본적으로 오름차순으로 되어 있고, 내림차순으로 정렬을 원한다면 반대로 리턴해준다.
|
||||
```java
|
||||
return o2 - o1; // 내림차순
|
||||
```
|
||||
|
||||
기본적으로 리턴의 값이 음수이면 오름차순, 양수이면 내림차순으로 정렬이 된다고 생각하면 이해하기 쉽다.
|
||||
|
||||
|
||||
### Comparable
|
||||
Comparable 인터페이스에는 comepareTo() 추상메서드 하나만 존재한다.
|
||||
|
||||
주어진 객체보다 작으면 음수, 같으면0, 크면 양수를 리턴한다.
|
||||
|
||||
```java
|
||||
public class NameCard implements Comparable<NameCard> {
|
||||
public String name;
|
||||
public int age;
|
||||
|
||||
public NameCard(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int compareTo(NameCard o) {
|
||||
if(this.age < o.age) {
|
||||
return -1;
|
||||
} else (this.age > o.age) {
|
||||
return 1;
|
||||
} else
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
List<NameCard> list = new ArrayList<>();
|
||||
list.add(new NameCard("김자바", 9));
|
||||
list.add(new NameCard("박파이썬", 10));
|
||||
list.add(new NameCard("신씨", 1));
|
||||
list.add(new NameCard("양자스", 7));
|
||||
|
||||
Collections.sort(list);
|
||||
|
||||
for(NameCard n : list) {
|
||||
System.out.println(n.name + " " + n.age);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> Result : <br>
|
||||
신씨 1 <br>
|
||||
양자스 7 <br>
|
||||
김자바 9 <br>
|
||||
박파이썬 10 <br>
|
||||
|
||||
|
||||
### Lambda
|
||||
람다 방식으로도 간결하게 표현하여 정렬할 수 있다.
|
||||
|
||||
1차원 배열
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
|
||||
int N = 10;
|
||||
int[] arr = new int[N];
|
||||
|
||||
Arrays.sort(arrays, (o1, o2) -> o1 - o2);
|
||||
```
|
||||
|
||||
2차원 배열
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
|
||||
int N = 10;
|
||||
int[] arr = new int[N];
|
||||
|
||||
Arrays.sort(arrays, (o1, o2) -> o1[0] == o2[0] ? o1[1] - o2[1] : o1[0] - o2[0]);
|
||||
```
|
||||
|
||||
같은 방식이지만 사용하면서 더 편한 방법으로 사용하면 될 것 같다.
|
||||
|
||||
--------
|
||||
|
||||
## JavaScript
|
||||
자바스크립트 방식은 최근에 웹 프론트 개발자로 이직하기 위해서 알고리즘을 하면서 사용해 보았다.
|
||||
|
||||
```javascript
|
||||
let arr = [];
|
||||
|
||||
arr.sort([compareFunction]);
|
||||
```
|
||||
**파라미터** <br>
|
||||
**compareFunction** <br>
|
||||
> 정렬 순서를 정의하는 함수 <br>
|
||||
*이 값이 생략되면, 배열의 element들은 문자열로 취급되어 유니코드 값 순서대로 정렬된다.* <br>
|
||||
이 함수는 두 개의 배열 element를 파라미터로 입력 받는다. <br>
|
||||
이 함수가 a, b 두개의 element를 파라미터로 입력받을 경우, <br>
|
||||
이 함수가 리턴하는 값이 0보다 작을 경우, a가 b보다 앞에 오도록 정렬하고, <br>
|
||||
이 함수가 리턴하는 값이 0보다 클 경우, b가 a보다 앞에 오도록 정렬한다. <br>
|
||||
만약 0을 리턴하면, a와 b의 순서를 변경하지 않는다. <br>
|
||||
|
||||
|
||||
**리턴값** <br>
|
||||
*compareFunction* 규칙에 따라서 정렬된 배열을 리턴한다.<br>
|
||||
이때, 원본 배열인 arr가 정렬이 되고, 리턴하는 값 또한 원본 배열인 arr을 가리키고 있다.
|
||||
|
||||
```javascript
|
||||
const arr1 = [2, 1, 3];
|
||||
const arr2 = ['banana', 'apple', 'orange'];
|
||||
|
||||
arr1.sort();
|
||||
document.writeln(arr1 + '<br>');
|
||||
|
||||
arr2.sort();
|
||||
document.writeln(arr2 + '<br>');
|
||||
```
|
||||
> Result : <br>
|
||||
1, 2, 3 <br>
|
||||
apple,banana,orange <br>
|
||||
|
||||
```javascript
|
||||
const arr = [2, 1, 3, 10];
|
||||
|
||||
arr.sort(function(a, b) {
|
||||
return a - b;
|
||||
});
|
||||
document.writeln(arr + '<br>');
|
||||
```
|
||||
|
||||
> Result : <br>
|
||||
1, 2, 3, 10
|
||||
|
||||
이 경우에도 a - b가 음수면 오름차순, 양수면 내림차순이 된다.
|
||||
|
||||
또한 객체로 구분하여 정렬하는 방법도 생각해 볼 수 있다.
|
||||
|
||||
```javascript
|
||||
const arr = [
|
||||
{name: 'banana', price: 3000},
|
||||
{name: 'apple', price: 1000},
|
||||
{name: 'orange', price: 500}
|
||||
];
|
||||
|
||||
arr.sort(function(a, b) {
|
||||
return a.price - b.price;
|
||||
});
|
||||
document.writeln(JSON.stringify(arr[0]) + '<br>');
|
||||
```
|
||||
|
||||
> Result <br>
|
||||
{name: 'orange', price: 500},
|
||||
{name: 'apple', price: 1000},
|
||||
{name: 'banana', price: 3000},
|
||||
|
||||
|
||||
틀리거나 이상한 내용이 있다면 알려주세요!
|
||||
@@ -0,0 +1,184 @@
|
||||
---
|
||||
title: Samsung sorftware Algorithms. 14501 퇴사
|
||||
date: 2022-03-08
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 14501.퇴사 - 삼성기출문제 (from.백준알고리즘)
|
||||
---
|
||||
# 14501.퇴사 - 삼성기출문제 (from.백준알고리즘)
|
||||
|
||||
해당 문제는 DP(Dynamic Programing) 또는 완전탐색으로 풀 수 있는 문제입니다.
|
||||
|
||||
우선 문제를 DP를 이용해서 풀어보고, 그 다음 완전탐색을 이용해서 풀어 보았습니다.
|
||||
|
||||
---
|
||||
|
||||
### **14051\. 퇴사**
|
||||
|
||||
상담원으로 일하고 있는 백준이는 퇴사를 하려고 한다.
|
||||
|
||||
오늘부터 N+1일째 되는 날 퇴사를 하기 위해서, 남은 N일 동안 최대한 많은 상담을 하려고 한다.
|
||||
|
||||
백준이는 비서에게 최대한 많은 상담을 잡으라고 부탁을 했고, 비서는 하루에 하나씩 서로 다른 사람의 상담을 잡아놓았다.
|
||||
|
||||
각각의 상담은 상담을 완료하는데 걸리는 기간 Ti와 상담을 했을 때 받을 수 있는 금액 Pi로 이루어져 있다.
|
||||
|
||||
N = 7인 경우에 다음과 같은 상담 일정표를 보자.
|
||||
|
||||
| | 1일 | 2일 | 3일 | 4일 | 5일 | 6일 | 7일 |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| Ti | 3 | 5 | 1 | 1 | 2 | 4 | 2 |
|
||||
| Pi | 10 | 20 | 10 | 20 | 15 | 40 | 200 |
|
||||
|
||||
1일에 잡혀있는 상담은 총 3일이 걸리며, 상담했을 때 받을 수 있는 금액은 10이다. 5일에 잡혀있는 상담은 총 2일이 걸리며, 받을 수 있는 금액은 15이다.
|
||||
|
||||
상담을 하는데 필요한 기간은 1일보다 클 수 있기 때문에, 모든 상담을 할 수는 없다. 예를 들어서 1일에 상담을 하게 되면, 2일, 3일에 있는 상담은 할 수 없게 된다. 2일에 있는 상담을 하게 되면, 3, 4, 5, 6일에 잡혀있는 상담은 할 수 없다.
|
||||
|
||||
또한, N+1일째에는 회사에 없기 때문에, 6, 7일에 있는 상담을 할 수 없다.
|
||||
|
||||
퇴사 전에 할 수 있는 상담의 최대 이익은 1일, 4일, 5일에 있는 상담을 하는 것이며, 이때의 이익은 10+20+15=45이다.
|
||||
|
||||
상담을 적절히 했을 때, 백준이가 얻을 수 있는 최대 수익을 구하는 프로그램을 작성하시오.
|
||||
|
||||
**입력(Input)**
|
||||
|
||||
첫째 줄에 N (1 ≤ N ≤ 15)이 주어진다.
|
||||
|
||||
둘째 줄부터 N개의 줄에 Ti와 Pi가 공백으로 구분되어서 주어지며, 1일부터 N일까지 순서대로 주어진다. (1 ≤ Ti ≤ 5, 1 ≤ Pi ≤ 1,000)
|
||||
|
||||
**출력(Output)**
|
||||
|
||||
첫째 줄에 백준이가 얻을 수 있는 최대 이익을 출력한다.
|
||||
|
||||
---
|
||||
|
||||
## 1\. DP로 접근
|
||||
|
||||
해당 문제는 첫째날-->마지막날로 접근하는 것보다, 마지막날-->첫째날로 접근하는 것이 더 쉽습니다.
|
||||
|
||||
7일에 잡혀있는 일은 2일이 걸리기 때문에 아무리 금액이 높더라도 진행할 수 없습니다.
|
||||
|
||||
6일에도 4일이 걸리기 때문에 N+1 즉, 7일이 넘어가기 때문에 진행할 수 없습니다.
|
||||
|
||||
5일에는 2일이 걸리는 일이 있습니다. 5~6일에 일을 하고 얻는 15의 수익이 얻을 수 있는 최대 수익입니다.
|
||||
|
||||
4일째에는 1일짜리 일을 추가로 하고, 5일까지의 일에 더해주는 것이 최대 수익이 됩니다. 즉, 20 + 15 = 35
|
||||
|
||||
3일째에도 1일짜리 일을 추가로 하고, 4일까지의 일에 더해주는 것이 최대 수익이 됩니다. 10 + 20 + 15 = 45
|
||||
|
||||
2일째에는 5일이 걸리는 일이 있습니다. 5일을 했을때 최대 이익과 위에서 했던 일중에서 비교를 해봐야 합니다.
|
||||
|
||||
2~6일까지 일을 해서 얻는 수익은 20입니다.
|
||||
|
||||
이것은 3~6까지 세가지 일을 해서 얻는 수익 45와 비교하면 낮습니다. 그러므로 2일째 일은 하지 않습니다.
|
||||
|
||||
1일째에도 마찬가지로 3일이 걸리는 일이 있습니다.
|
||||
|
||||
1~3일을 일을 하면 10의 수익을 얻을 수 있습니다.
|
||||
|
||||
이것은 3일째에 일을 하는 10의 수익과 같습니다. 그러므로 1일째에 일을 선택하던지 3일째의 일을 선택하던지 하면 최대 수익을 얻을 수 있습니다.
|
||||
|
||||
| | 1일 | 2일 | 3일 | 4일 | 5일 | 6일 | 7일 |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| Ti | 3 | 5 | 1 | 1 | 2 | 4 | 2 |
|
||||
| Pi | 10 | 20 | 10 | 20 | 15 | 40 | 200 |
|
||||
| DP | 45 | 45 | 45 | 35 | 15 | \- | \- |
|
||||
|
||||
이러한 조건에서 위와 같이 최대 수익은 45가 나올 수 있습니다.
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
/**
|
||||
* 14501. 퇴사
|
||||
* @author gahusb
|
||||
* Input : N - 퇴사전까지 남은 기간, Ti - 상담을 완료하는데 걸리는 기간, Pi - 상담을 했을 때 받을 수 있는 금액
|
||||
* Output : 상담을 적절히 했을 때, 백준이가 얻을 수 있는 최대 수익
|
||||
*
|
||||
*/
|
||||
public class Resignation {
|
||||
static int[] t, p, dp;
|
||||
|
||||
static void calcMaxIncome(int dDay) {
|
||||
int next;
|
||||
|
||||
for (int i = dDay; i > 0; i--) {
|
||||
next = i + t[i];
|
||||
if (next > dDay + 1) {
|
||||
dp[i] = dp[i + 1];
|
||||
} else {
|
||||
dp[i] = dp[i + 1] > dp[next] + p[i] ? dp[i + 1] : dp[next] + p[i];
|
||||
}
|
||||
}
|
||||
|
||||
System.out.println(dp[1]);
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
int N = Integer.parseInt(st.nextToken());
|
||||
t = new int[N+2];
|
||||
p = new int[N+2];
|
||||
dp = new int[N+2];
|
||||
for (int i = 1; i <= N; i++) {
|
||||
if (!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
t[i] = Integer.parseInt(st.nextToken());
|
||||
p[i] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
|
||||
calcMaxIncome(N);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2\. 완전탐색
|
||||
|
||||
\-- 완전 탐색의 방법은 나중에 추후 업데이트 --
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
```java
|
||||
public class Resignation {
|
||||
static int[] t, p;
|
||||
static int N, income;
|
||||
|
||||
static void calcMaxIncome(int day, int cost) {
|
||||
if(day > N) {
|
||||
return;
|
||||
}
|
||||
|
||||
income = income > cost ? income : cost;
|
||||
|
||||
for (int i = day; i < N; i++) {
|
||||
calcMaxIncome(i + t[i], cost + p[i]);
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
t = new int[N];
|
||||
p = new int[N];
|
||||
for (int i = 0; i < N; i++) {
|
||||
if (!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
t[i] = Integer.parseInt(st.nextToken());
|
||||
p[i] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
|
||||
calcMaxIncome(0, 0);
|
||||
System.out.println(income);
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,195 @@
|
||||
---
|
||||
title: SSamsung sorftware Algorithms. 14502 연구소
|
||||
date: 2022-03-08
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 14502.연구소 - 삼성기출문제 (from.백준알고리즘)
|
||||
---
|
||||
# 14502.연구소 - 삼성기출문제 (from.백준알고리즘)
|
||||
|
||||
해당 문제는 완전탐색으로 풀 수 있는 문제다. 벽을 세우는 경우를 전부 해보고 안전 영역의 최대 크기를 구하면 된다.
|
||||
|
||||
---
|
||||
|
||||
### 14502\. 연구소
|
||||
|
||||
인체에 치명적인 바이러스를 연구하던 연구소에서 바이러스가 유출되었다. 다행히 바이러스는 아직 퍼지지 않았고, 바이러스의 확산을 막기 위해서 연구소에 벽을 세우려고 한다.
|
||||
|
||||
연구소는 크기가 N×M인 직사각형으로 나타낼 수 있으며, 직사각형은 1×1 크기의 정사각형으로 나누어져 있다. 연구소는 빈 칸, 벽으로 이루어져 있으며, 벽은 칸 하나를 가득 차지한다.
|
||||
|
||||
일부 칸은 바이러스가 존재하며, 이 바이러스는 상하좌우로 인접한 빈 칸으로 모두 퍼져나갈 수 있다. 새로 세울 수 있는 벽의 개수는 3개이며, 꼭 3개를 세워야 한다.
|
||||
|
||||
예를 들어, 아래와 같이 연구소가 생긴 경우를 살펴보자.
|
||||
|
||||
> 2 0 0 0 1 1 0
|
||||
> 0 0 1 0 1 2 0
|
||||
> 0 1 1 0 1 0 0
|
||||
> 0 1 0 0 0 0 0
|
||||
> 0 0 0 0 0 1 1
|
||||
> 0 1 0 0 0 0 0
|
||||
> 0 1 0 0 0 0 0
|
||||
|
||||
이때, 0은 빈 칸, 1은 벽, 2는 바이러스가 있는 곳이다. 아무런 벽을 세우지 않는다면, 바이러스는 모든 빈 칸으로 퍼져나갈 수 있다.
|
||||
|
||||
2행 1열, 1행 2열, 4행 6열에 벽을 세운다면 지도의 모양은 아래와 같아지게 된다.
|
||||
|
||||
> 2 1 0 0 1 1 0
|
||||
> 1 0 1 0 1 2 0
|
||||
> 0 1 1 0 1 0 0
|
||||
> 0 1 0 0 0 1 0
|
||||
> 0 0 0 0 0 1 1
|
||||
> 0 1 0 0 0 0 0
|
||||
> 0 1 0 0 0 0 0
|
||||
|
||||
바이러스가 퍼진 뒤의 모습은 아래와 같아진다.
|
||||
|
||||
> 2 1 0 0 1 1 2
|
||||
> 1 0 1 0 1 2 2
|
||||
> 0 1 1 0 1 2 2
|
||||
> 0 1 0 0 0 1 2
|
||||
> 0 0 0 0 0 1 1
|
||||
> 0 1 0 0 0 0 0
|
||||
> 0 1 0 0 0 0 0
|
||||
|
||||
벽을 3개 세운 뒤, 바이러스가 퍼질 수 없는 곳을 안전 영역이라고 한다. 위의 지도에서 안전 영역의 크기는 27이다.
|
||||
|
||||
연구소의 지도가 주어졌을 때 얻을 수 있는 안전 영역 크기의 최댓값을 구하는 프로그램을 작성하시오.
|
||||
|
||||
#### 입력 (Input)
|
||||
|
||||
첫째 줄에 지도의 세로 크기 N과 가로 크기 M이 주어진다. (3 ≤ N, M ≤ 8)
|
||||
|
||||
둘째 줄부터 N개의 줄에 지도의 모양이 주어진다. 0은 빈 칸, 1은 벽, 2는 바이러스가 있는 위치이다. 2의 개수는 2보다 크거나 같고, 10보다 작거나 같은 자연수이다.
|
||||
|
||||
빈 칸의 개수는 3개 이상이다.
|
||||
|
||||
#### 출력(Output)
|
||||
|
||||
첫째 줄에 얻을 수 있는 안전 영역의 최대 크기를 출력한다.
|
||||
|
||||
---
|
||||
|
||||
1\. 문제풀이
|
||||
|
||||
이 문제를 풀때에 생각해야할 부분은 두 가지 입니다.
|
||||
|
||||
1. 이 차원 배열로 이루어진 map에 임의의 벽 3개를 어떤 방식으로 세운다고 가정할 것인가?
|
||||
2. 확산시 방문 체크와 어떻게 전체에 바이러스를 퍼졌다고 할까?
|
||||
|
||||
1번은 완전 탐색 DFS를 통해서 세우고 해제하고를 하며 재귀를 돌아 최종적으로 벽을 3개 세웠을 때, 확산을 실행하여 남은 안전 영역을 구하면 됩니다.
|
||||
|
||||
2번은 확산에 대한 좌표를 큐에 담고, 큐에서 바이러스가 있는 공간을 하나씩 빼서 상, 하, 좌, 우로 바이러스가 퍼질 수 있는 공간이면 맵에 기록하고 큐에 새로운 바이러스를 넣어주며 큐에 더이상 확산할 수 있는 바이러스가 없을때까지 반복하여 해결합니다.
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.ArrayList;
|
||||
import java.util.LinkedList;
|
||||
import java.util.Queue;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class Institute {
|
||||
// 벽을 3개 세운 뒤, 바이러스가 퍼질 수 없는 곳을 안전 영역이라고 한다.
|
||||
// 바이러스는 상, 하, 좌, 우로 퍼져 나간다.
|
||||
// 0은 빈칸, 1은 벽, 2는 바이러스
|
||||
static int N, M, safty, listSize;
|
||||
static ArrayList<Block> list, virusList;
|
||||
static Queue<Block> virus;
|
||||
static int[][] map;
|
||||
static boolean[][] visited;
|
||||
static int[][] dif = {
|
||||
{0, 1, -1, 0},
|
||||
{1, 0, 0, -1},
|
||||
};
|
||||
|
||||
static void virus(int cnt, int idx) {
|
||||
if(cnt == 3) {
|
||||
visited = new boolean[N][M];
|
||||
diffusion();
|
||||
int max = searchSafy();
|
||||
if(max > safty) safty = max;
|
||||
return;
|
||||
}
|
||||
|
||||
if(listSize <= idx) return;
|
||||
|
||||
Block tmp = list.get(idx);
|
||||
map[tmp.x][tmp.y] = 1;
|
||||
virus(cnt + 1, idx + 1);
|
||||
map[tmp.x][tmp.y] = 0;
|
||||
virus(cnt, idx + 1);
|
||||
}
|
||||
|
||||
static void diffusion() {
|
||||
virus.clear();
|
||||
|
||||
for (int i = 0; i < virusList.size(); i++) {
|
||||
virus.add(virusList.get(i));
|
||||
}
|
||||
|
||||
while(!virus.isEmpty()) {
|
||||
Block tmp = virus.poll();
|
||||
visited[tmp.x][tmp.y] = true;
|
||||
for (int i = 0; i < 4; i++) {
|
||||
int nx = tmp.x + dif[0][i];
|
||||
int ny = tmp.y + dif[1][i];
|
||||
if(0 <= nx && nx < N && 0 <= ny && ny < M && map[nx][ny] == 0 && !visited[nx][ny]) {
|
||||
visited[nx][ny] = true;
|
||||
virus.add(new Block(nx, ny));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
static int searchSafy() {
|
||||
int area = 0;
|
||||
|
||||
for (int i = 0; i < N; i++) {
|
||||
for (int j = 0; j < M; j++) {
|
||||
if(map[i][j] == 0 && !visited[i][j]) area++;
|
||||
}
|
||||
}
|
||||
|
||||
return area;
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
M = Integer.parseInt(st.nextToken());
|
||||
map = new int[N][M];
|
||||
list = new ArrayList<>();
|
||||
virusList = new ArrayList<>();
|
||||
virus = new LinkedList<Block>();
|
||||
for (int i = 0; i < N; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
for (int j = 0; j < M; j++) {
|
||||
map[i][j] = Integer.parseInt(st.nextToken());
|
||||
if(map[i][j] == 0) {
|
||||
list.add(new Block(i, j));
|
||||
listSize++;
|
||||
} else if(map[i][j] == 2) virusList.add(new Block(i, j));
|
||||
}
|
||||
}
|
||||
|
||||
safty = 0;
|
||||
virus(0, 0);
|
||||
|
||||
System.out.println(safty);
|
||||
}
|
||||
|
||||
public static class Block {
|
||||
int x, y;
|
||||
public Block(int x, int y) {
|
||||
this.x = x;
|
||||
this.y = y;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,152 @@
|
||||
---
|
||||
title: Samsung sorftware Algorithms. 14503 로봇 청소기
|
||||
date: 2022-03-09
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 14503.로봇 청소기 - 삼성기출문제 (from.백준알고리즘)
|
||||
---
|
||||
# 14503.로봇 청소기 - 삼성기출문제 (from.백준알고리즘)
|
||||
|
||||
해당 문제는 시뮬레이션 문제로 단계별로 수행하는 함수를 이용하여 풀 수 있는 문제입니다.
|
||||
|
||||
---
|
||||
|
||||
### 14503\. 로봇 청소기
|
||||
|
||||
로봇 청소기가 주어졌을 때, 청소하는 영역의 개수를 구하는 프로그램을 작성하시오.
|
||||
|
||||
로봇 청소기가 있는 장소는 N×M 크기의 직사각형으로 나타낼 수 있으며, 1×1크기의 정사각형 칸으로 나누어져 있다. 각각의 칸은 벽 또는 빈 칸이다. 청소기는 바라보는 방향이 있으며, 이 방향은 동, 서, 남, 북중 하나이다. 지도의 각 칸은 (r, c)로 나타낼 수 있고, r은 북쪽으로부터 떨어진 칸의 개수, c는 서쪽으로 부터 떨어진 칸의 개수이다.
|
||||
|
||||
로봇 청소기는 다음과 같이 작동한다.
|
||||
|
||||
1. 현재 위치를 청소한다.
|
||||
2. 현재 위치에서 현재 방향을 기준으로 왼쪽방향부터 차례대로 탐색을 진행한다.
|
||||
1. 왼쪽 방향에 아직 청소하지 않은 공간이 존재한다면, 그 방향으로 회전한 다음 한 칸을 전진하고 1번부터 진행한다.
|
||||
2. 왼쪽 방향에 청소할 공간이 없다면, 그 방향으로 회전하고 2번으로 돌아간다.
|
||||
3. 네 방향 모두 청소가 이미 되어있거나 벽인 경우에는, 바라보는 방향을 유지한 채로 한 칸 후진을 하고 2번으로 돌아간다.
|
||||
4. 네 방향 모두 청소가 이미 되어있거나 벽이면서, 뒤쪽 방향이 벽이라 후진도 할 수 없는 경우에는 작동을 멈춘다.
|
||||
|
||||
로봇 청소기는 이미 청소되어있는 칸을 또 청소하지 않으며, 벽을 통과할 수 없다.
|
||||
|
||||
#### 입력(Input)
|
||||
|
||||
첫째 줄에 세로 크기 N과 가로 크기 M이 주어진다. (3 ≤ N, M ≤ 50)
|
||||
|
||||
둘째 줄에 로봇 청소기가 있는 칸의 좌표 (r, c)와 바라보는 방향 d가 주어진다. d가 0인 경우에는 북쪽을, 1인 경우에는 동쪽을, 2인 경우에는 남쪽을, 3인 경우에는 서쪽을 바라보고 있는 것이다.
|
||||
|
||||
셋째 줄부터 N개의 줄에 장소의 상태가 북쪽부터 남쪽 순서대로, 각 줄은 서쪽부터 동쪽 순서대로 주어진다. 빈 칸은 0, 벽은 1로 주어진다. 지도의 첫 행, 마지막 행, 첫 열, 마지막 열에 있는 모든 칸은 벽이다.
|
||||
|
||||
로봇 청소기가 있는 칸의 상태는 항상 빈 칸이다.
|
||||
|
||||
#### 출력(Output)
|
||||
|
||||
첫째 줄에 T초가 지난 후 구사과 방에 남아있는 미세먼지의 양을 출력한다.
|
||||
|
||||
---
|
||||
|
||||
### 1\. 문제 풀이
|
||||
|
||||
이 문제를 풀때에 생각해야 할 것은 두 가지 입니다.
|
||||
|
||||
1. 최초의 자리도 청소
|
||||
2. 바라보고 있는 방향에 따라서 왼쪽의 좌표를 설정하는 것
|
||||
|
||||
최초에 자리를 청소한다고 하고 map에서 현 자리를 청소 한걸로 표시하고 스타트 합니다.
|
||||
|
||||
그리고 바라보고 있는 방향 왼쪽 좌표를 바라보기 때문에 배열에 현재 바라보고 있는 방향을 인덱스로 왼쪽을 보는 값을 고정 시켜줍니다. 저는
|
||||
|
||||
> // 북 - (0,-1), 동 - (-1,0), 남 - (0,1), 서 - (1,0)
|
||||
> static int\[\]\[\] left = { {0, -1, 0, 1}, {-1, 0, 1, 0}, };
|
||||
|
||||
으로 고정시켜서 사용하였습니다.
|
||||
|
||||
- 현재 북쪽을 바라보고 있고, 왼쪽 방향을 탐색하려 합니다.
|
||||
- left\[0\]\[\] 에 있는 값을 현재 위치에서 더해주고, 청소가 가능하면 청소를하고 해당 방향으로 변경
|
||||
- 청소가 불가능하면 해당 방향으로 회전하여 다시 진행
|
||||
- 네 방향 모두 불가한 것을 체크하기 위해 count 변수를 두어 확인해 주고 네 방향 전부 불가능 하면 현재 바라보고 있는 방향에서 뒤로 한 칸 후진 합니다.
|
||||
- 만약 후진도 못하면 종료합니다.
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
|
||||
public class Robot_Vaccumcleaner {
|
||||
// 3 <= N, M <= 50 || 0 - empty, 1 - wall
|
||||
// d : 0 - North, 1 - East, 2 - South, 3 - West
|
||||
// 현재 위치에서 현재 방향을 기준으로 왼쪽방향부터 차례대로 탐색
|
||||
// 로봇 청소기가 있는 칸의 상태는 항상 빈 칸이다.
|
||||
static int N, M, r, c, d;
|
||||
static int clean;
|
||||
static int[][] map;
|
||||
// 바라보고 있는 방향에 따라서 탐색하는 왼쪽의 좌표가 다르다.
|
||||
// 북 - (0,-1), 동 - (-1,0), 남 - (0,1), 서 - (1,0)
|
||||
static int[][] left = {
|
||||
{0, -1, 0, 1},
|
||||
{-1, 0, 1, 0},
|
||||
};
|
||||
|
||||
static void cleanning() {
|
||||
int cnt = 0;
|
||||
while(true) {
|
||||
int nxR = r + left[0][d];
|
||||
int nxC = c + left[1][d];
|
||||
if(nxR < 0 || N <= nxR || nxC < 0 || M <= nxC || map[nxR][nxC] == -1 || map[nxR][nxC] == 1) { // 왼쪽에 청소 할 공간이 없다면, 그 위치로 회전.
|
||||
if(cnt >= 4) { // 네 방향 모두 청소가 되어 있거나 벽인경우 방향 그대로 뒤로 후진
|
||||
switch(d) {
|
||||
case 0: nxR = r + 1; nxC = c; break;
|
||||
case 1: nxR = r; nxC = c - 1; break;
|
||||
case 2: nxR = r - 1; nxC = c; break;
|
||||
case 3: nxR = r; nxC = c + 1; break;
|
||||
}
|
||||
if(map[nxR][nxC] == 1) { // 네 방향 모두 청소가 됭 있고, 뒤가 벽인 경우 종료.
|
||||
break;
|
||||
}
|
||||
r = nxR; c = nxC;
|
||||
cnt = 0;
|
||||
} else {
|
||||
d -= 1;
|
||||
if(d < 0) d = 3;
|
||||
cnt++;
|
||||
}
|
||||
} else if(map[nxR][nxC] == 0) { // 왼쪽 방향에 청소 공간이 존재한다면,
|
||||
d -= 1;
|
||||
if(d < 0) d = 3;
|
||||
map[nxR][nxC] = -1;
|
||||
clean++;
|
||||
cnt = 0;
|
||||
r = nxR; c = nxC;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
M = Integer.parseInt(st.nextToken());
|
||||
map = new int[N][M];
|
||||
st = new StringTokenizer(br.readLine());
|
||||
r = Integer.parseInt(st.nextToken());
|
||||
c = Integer.parseInt(st.nextToken());
|
||||
d = Integer.parseInt(st.nextToken());
|
||||
for (int i = 0; i < N; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
for (int j = 0; j < M; j++) {
|
||||
map[i][j] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
}
|
||||
|
||||
clean = 1; map[r][c] = -1;
|
||||
cleanning();
|
||||
|
||||
System.out.println(clean);
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,230 @@
|
||||
---
|
||||
title: Samsung sorftware Algorithms. 17144.미세먼지 안녕!
|
||||
date: 2022-03-09
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 17144.미세먼지 안녕! - 삼성기출문제 (from.백준알고리즘)
|
||||
---
|
||||
# 17144.미세먼지 안녕! - 삼성기출문제 (from.백준알고리즘)
|
||||
|
||||
해당 문제는 시뮬레이션 문제로 단계별로 수행하는 함수를 이용하여 풀 수 있는 문제입니다.
|
||||
|
||||
---
|
||||
|
||||
### 17144\. 미세먼지 안녕!
|
||||
|
||||
미세먼지를 제거하기 위해 구사과는 공기청정기를 설치하려고 한다. 공기청정기의 성능을 테스트하기 위해 구사과는 집을 크기가 R×C인 격자판으로 나타냈고, 1×1 크기의 칸으로 나눴다. 구사과는 뛰어난 코딩 실력을 이용해 각 칸 (r, c)에 있는 미세먼지의 양을 실시간으로 모니터링하는 시스템을 개발했다. (r, c)는 r행 c열을 의미한다.
|
||||
|
||||

|
||||
|
||||
공기청정기는 항상 1번 열에 설치되어 있고, 크기는 두 행을 차지한다. 공기청정기가 설치되어 있지 않은 칸에는 미세먼지가 있고, (r, c)에 있는 미세먼지의 양은 Ar,c이다.
|
||||
|
||||
1초 동안 아래 적힌 일이 순서대로 일어난다.
|
||||
|
||||
1. 미세먼지가 확산된다. 확산은 미세먼지가 있는 모든 칸에서 동시에 일어난다.
|
||||
- (r, c)에 있는 미세먼지는 인접한 네 방향으로 확산된다.
|
||||
- 인접한 방향에 공기청정기가 있거나, 칸이 없으면 그 방향으로는 확산이 일어나지 않는다.
|
||||
- 확산되는 양은 Ar,c/5이고 소수점은 버린다.
|
||||
- (r, c)에 남은 미세먼지의 양은 Ar,c - (Ar,c/5)×(확산된 방향의 개수) 이다.
|
||||
2. 공기청정기가 작동한다.
|
||||
- 공기청정기에서는 바람이 나온다.
|
||||
- 위쪽 공기청정기의 바람은 반시계방향으로 순환하고, 아래쪽 공기청정기의 바람은 시계방향으로 순환한다.
|
||||
- 바람이 불면 미세먼지가 바람의 방향대로 모두 한 칸씩 이동한다.
|
||||
- 공기청정기에서 부는 바람은 미세먼지가 없는 바람이고, 공기청정기로 들어간 미세먼지는 모두 정화된다.
|
||||
|
||||
다음은 확산의 예시이다.
|
||||
|
||||

|
||||
|
||||
왼쪽과 오른쪽에 칸이 없기 때문에, 두 방향으로만 확산이 일어났다.
|
||||
|
||||

|
||||
|
||||
인접한 네 방향으로 모두 확산이 일어난다.
|
||||
|
||||

|
||||
|
||||
공기청정기가 있는 칸으로는 확산이 일어나지 않는다.
|
||||
|
||||
공기청정기의 바람은 다음과 같은 방향으로 순환한다.
|
||||
|
||||

|
||||
|
||||
방의 정보가 주어졌을 때, T초가 지난 후 구사과의 방에 남아있는 미세먼지의 양을 구해보자.
|
||||
|
||||
#### 입력(Input)
|
||||
|
||||
첫째 줄에 R, C, T (6 ≤ R, C ≤ 50, 1 ≤ T ≤ 1,000) 가 주어진다.
|
||||
|
||||
둘째 줄부터 R개의 줄에 Ar,c (-1 ≤ Ar,c ≤ 1,000)가 주어진다. 공기청정기가 설치된 곳은 Ar,c가 -1이고, 나머지 값은 미세먼지의 양이다. -1은 2번 위아래로 붙어져 있고, 가장 윗 행, 아랫 행과 두 칸이상 떨어져 있다.
|
||||
|
||||
#### 출력(Output)
|
||||
|
||||
첫째 줄에 T초가 지난 후 구사과 방에 남아있는 미세먼지의 양을 출력한다.
|
||||
|
||||
---
|
||||
|
||||
### 1\. 문제 풀이
|
||||
|
||||
이 문제를 풀때에 생각해야할 제일 중요한 핵심은 두 가지 입니다.
|
||||
|
||||
1. 확산에서 각 현 위치의 값만 고려해서 겹치는 칸은 더해진다.
|
||||
2. 공기청정시 돌아가는 배열 돌리기.
|
||||
|
||||
1번은 확산 예시 3번 그림을 보았을때
|
||||
|
||||
- (0, 1)에 30이 세 방향으로 확산되었기 때문에 30 - ((30/5)\*3) = 12라는 남는 부분과 확산되어 오는 두 방향에서의 계산식 11 / 5 = 2, 7 / 5 = 1 즉, 12 + 2 + 1 = 15
|
||||
- (0, 2)에 7이 두 방향으로 확산되었기 때문에 7 - ((7/5)\*2) = 5라는 남는 부분과 확산되어 오는 한 방향에서의 계산식 30/5 = 6 즉, 5 + 6 = 11
|
||||
|
||||
따라서 한 칸씩 이동하면서 계산을 해주면 됩니다.
|
||||
|
||||
2번은 배열돌리기 입니다. 배열은 사각형 모양으로 끝을 만나기 전까지 INDEX를 계속 반복하여 증가/감소를 하다가 끝이라는 경계를 만나면 각 인덱스의 증가/감소 플래그를 바꿔주면 됩니다.
|
||||
|
||||
- 인덱스는 i,j라고 합니다. (여기서 끝은 배열 구분선 직전까지를 의미합니다. 즉, 인덱스의 범위)
|
||||
- 처음 공기청정기의 위치에 따라서 반으로 나누고 i,j의 범위를 정해줍니다. (예시는 아래쪽 기준)
|
||||
- 처음에는 i가 증가하는 방향으로 가다가 끝을 만나면 멈추고 j를 증가시켜 줍니다.
|
||||
- j가 증가하는 방향으로 가다가 끝을 만나면 멈추고 i를 감소시켜 줍니다.
|
||||
- i를 감소시켜주다가 공기청정기를 만나면 종료합니다.
|
||||
|
||||
이렇게 순차적으로 배열돌리기를 하면서 다음에 있는 값을 저장하고, 해당 위치로 이동해 넣어주고를 반복해줍니다.
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
|
||||
public class Bye_Microcum {
|
||||
// (6 <= R,C <= 50, 1<= T <= 1000) (-1 <= Arc <= 1000)
|
||||
// 공기청정기 위치는 -1, -1은 위아래 붙어있고, 가장 윗 행, 아랫 행과 두 칸이상 떨어져 있다.
|
||||
static int R, C, T, result;
|
||||
static int[][] A, B;
|
||||
static int[][] idx = {
|
||||
{-1, 0, 1, 0},
|
||||
{0, -1, 0, 1}
|
||||
};
|
||||
static int upR, upC, downR, downC;
|
||||
|
||||
static void diffusion() {
|
||||
B = new int[R][C];
|
||||
|
||||
for (int i = 0; i < R; i++) {
|
||||
for (int j = 0; j < C; j++) {
|
||||
if(A[i][j] == -1) {
|
||||
B[i][j] = -1;
|
||||
continue;
|
||||
}
|
||||
int cnt = 0;
|
||||
if(A[i][j] != 0) {
|
||||
for (int k = 0; k < 4; k++) {
|
||||
int nxR = i + idx[0][k];
|
||||
int nxC = j + idx[1][k];
|
||||
if(nxR < 0 || nxC < 0 || nxR >= R || nxC >= C || A[nxR][nxC] == -1) {
|
||||
continue;
|
||||
} else {
|
||||
B[nxR][nxC] += A[i][j] / 5;
|
||||
cnt++;
|
||||
}
|
||||
}
|
||||
B[i][j] += A[i][j] - ((A[i][j]/5)*cnt);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 배열 복사
|
||||
for (int i = 0; i < R; i++) {
|
||||
for (int j = 0; j < C; j++) {
|
||||
A[i][j] = B[i][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
static void air_cleanning() {
|
||||
int temp, nextTemp, dir;
|
||||
|
||||
int[][] up = {
|
||||
{0, -1, 0, 1},
|
||||
{1, 0, -1, 0},
|
||||
};
|
||||
int i = upR, j = upC + 1; dir = 0;
|
||||
nextTemp = A[i][j];
|
||||
A[i][j] = 0;
|
||||
while(true) {
|
||||
temp = nextTemp;
|
||||
int nR = i + up[0][dir];
|
||||
int nC = j + up[1][dir];
|
||||
if(nR < 0 || R <= nR || nC < 0 || C <= nC) {
|
||||
dir++;
|
||||
nR = i + up[0][dir];
|
||||
nC = j + up[1][dir];
|
||||
} else if(A[nR][nC] == -1) break;
|
||||
nextTemp = A[nR][nC];
|
||||
A[nR][nC] = temp;
|
||||
i = nR; j = nC;
|
||||
}
|
||||
|
||||
int[][] down = {
|
||||
{0, 1, 0, -1},
|
||||
{1, 0, -1, 0},
|
||||
};
|
||||
i = downR; j = downC + 1; dir = 0;
|
||||
nextTemp = A[i][j];
|
||||
A[i][j] = 0;
|
||||
while(true) {
|
||||
temp = nextTemp;
|
||||
int nR = i + down[0][dir];
|
||||
int nC = j + down[1][dir];
|
||||
if(nR < 0 || R <= nR || nC < 0 || C <= nC) {
|
||||
dir++;
|
||||
nR = i + down[0][dir];
|
||||
nC = j + down[1][dir];
|
||||
} else if(A[nR][nC] == -1) break;
|
||||
nextTemp = A[nR][nC];
|
||||
A[nR][nC] = temp;
|
||||
i = nR; j = nC;
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
R = Integer.parseInt(st.nextToken());
|
||||
C = Integer.parseInt(st.nextToken());
|
||||
T = Integer.parseInt(st.nextToken());
|
||||
|
||||
A = new int[R][C];
|
||||
boolean air_condition = false;
|
||||
for (int i = 0; i < R; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
for (int j = 0; j < C; j++) {
|
||||
A[i][j] = Integer.parseInt(st.nextToken());
|
||||
if(A[i][j] == -1 && !air_condition) {
|
||||
upR = i; upC = j;
|
||||
downR = i + 1; downC = j;
|
||||
air_condition = true;
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
for (int i = 0; i < T; i++) {
|
||||
diffusion();
|
||||
air_cleanning();
|
||||
}
|
||||
|
||||
for (int i = 0; i < R; i++) {
|
||||
for (int j = 0; j < C; j++) {
|
||||
if(A[i][j] == -1) continue;
|
||||
result += A[i][j];
|
||||
}
|
||||
}
|
||||
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,88 @@
|
||||
---
|
||||
title: Baekjoon online judge. 2212.센서
|
||||
date: 2022-03-14
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 2212.센서 - 백준온라인
|
||||
---
|
||||
# 2212.센서 - 백준온라인
|
||||
|
||||
해당 문제는 탐욕(greedy) 문제로 현재 수행 하는것이 최선임을 정의하여 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/2212)
|
||||
|
||||
---
|
||||
|
||||
### 2212\. 센서
|
||||
|
||||
한국도로공사는 고속도로의 유비쿼터스화를 위해 고속도로 위에 N개의 센서를 설치하였다. 문제는 이 센서들이 수집한 자료들을 모으고 분석할 몇 개의 집중국을 세우는 일인데, 예산상의 문제로, 고속도로 위에 최대 K개의 집중국을 세울 수 있다고 한다.
|
||||
|
||||
각 집중국은 센서의 수신 가능 영역을 조절할 수 있다. 집중국의 수신 가능 영역은 고속도로 상에서 연결된 구간으로 나타나게 된다. N개의 센서가 적어도 하나의 집중국과는 통신이 가능해야 하며, 집중국의 유지비 문제로 인해 각 집중국의 수신 가능 영역의 길이의 합을 최소화해야 한다.
|
||||
|
||||
편의를 위해 고속도로는 평면상의 직선이라고 가정하고, 센서들은 이 직선 위의 한 기점인 원점으로부터의 정수 거리의 위치에 놓여 있다고 하자. 따라서, 각 센서의 좌표는 정수 하나로 표현된다. 이 상황에서 각 집중국의 수신 가능영역의 거리의 합의 최솟값을 구하는 프로그램을 작성하시오. 단, 집중국의 수신 가능영역의 길이는 0 이상이며 모든 센서의 좌표가 다를 필요는 없다.
|
||||
|
||||
#### 입력(Input)
|
||||
|
||||
첫째 줄에 센서의 개수 N(1 ≤ N ≤ 10,000), 둘째 줄에 집중국의 개수 K(1 ≤ K ≤ 1000)가 주어진다. 셋째 줄에는 N개의 센서의 좌표가 한 개의 정수로 N개 주어진다. 각 좌표 사이에는 빈 칸이 하나 있으며, 좌표의 절댓값은 1,000,000 이하이다.
|
||||
|
||||
#### 출력(Output)
|
||||
|
||||
첫째 줄에 문제에서 설명한 최대 K개의 집중국의 수신 가능 영역의 길이의 합의 최솟값을 출력한다.
|
||||
|
||||
---
|
||||
|
||||
### 1\. 문제 풀이
|
||||
|
||||
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.Arrays;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class Sensor_2212 {
|
||||
static int[] sensors;
|
||||
static int[] diff;
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
int N = Integer.parseInt(st.nextToken());
|
||||
st = new StringTokenizer(br.readLine());
|
||||
int K = Integer.parseInt(st.nextToken());
|
||||
|
||||
sensors = new int[N];
|
||||
diff = new int[N - 1];
|
||||
st = new StringTokenizer(br.readLine());
|
||||
for(int i = 0; i < N; i++) {
|
||||
sensors[i] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
|
||||
if(K >= N) System.out.println("0");
|
||||
else {
|
||||
Arrays.sort(sensors);
|
||||
|
||||
for(int i = 0; i < N - 1; i++) {
|
||||
diff[i] = sensors[i + 1] - sensors[i];
|
||||
}
|
||||
|
||||
Arrays.sort(diff);
|
||||
|
||||
int answer = 0;
|
||||
|
||||
for(int i = 0; i < N - K; i++) {
|
||||
answer += diff[i];
|
||||
}
|
||||
|
||||
System.out.println(answer);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
@@ -0,0 +1,163 @@
|
||||
---
|
||||
title: Baekjoon online judge. 18185.라면 사기(small)
|
||||
date: 2022-03-16
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 18185.라면 사기(small) - 백준온라인
|
||||
---
|
||||
# 18185.라면 사기(small) - 백준온라인
|
||||
|
||||
해당 문제는 탐욕(greedy) 문제로 현재 수행 하는것이 최선임을 정의하여 푸는 문제입니다.
|
||||
|
||||
그리디도 중요하지만 예외 처리가 중요한 부분이다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/18185)
|
||||
|
||||
---
|
||||
|
||||
## 18185\.라면 사기(small)
|
||||
|
||||
라면매니아 교준이네 집 주변에는 N개의 라면 공장이 있다. 각 공장은 1번부터 N번까지 차례대로 번호가 부여되어 있다. 교준이는 i번 공장에서 정확하게 Ai개의 라면을 구매하고자 한다(1 ≤ i ≤ N).
|
||||
|
||||
교준이는 아래의 세 가지 방법으로 라면을 구매할 수 있다.
|
||||
|
||||
i번 공장에서 라면을 하나 구매한다(1 ≤ i ≤ N). 이 경우 비용은 3원이 든다.
|
||||
i번 공장과 (i+1)번 공장에서 각각 라면을 하나씩 구매한다(1 ≤ i ≤ N-1). 이 경우 비용은 5원이 든다.
|
||||
i번 공장과 (i+1)번 공장, (i+2)번 공장에서 각각 라면을 하나씩 구매한다(1 ≤ i ≤ N-2). 이 경우 비용은 7원이 든다.
|
||||
최소의 비용으로 라면을 구매하고자 할 때, 교준이가 필요한 금액을 출력하는 프로그램을 작성하시오.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫째 줄에 센서의 개수 N(1 ≤ N ≤ 10,000), 둘째 줄에 집중국의 개수 K(1 ≤ K ≤ 1000)가 주어진다. 셋째 줄에는 N개의 센서의 좌표가 한 개의 정수로 N개 주어진다. 각 좌표 사이에는 빈 칸이 하나 있으며, 좌표의 절댓값은 1,000,000 이하이다.
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
첫째 줄에 문제에서 설명한 최대 K개의 집중국의 수신 가능 영역의 길이의 합의 최솟값을 출력한다.
|
||||
|
||||
---
|
||||
|
||||
### 1\. 문제 풀이
|
||||
그리디 알고리즘을 이용하는 문제인데, 구매 가능한 행동이 3가지이다. <br>
|
||||
그리고, i 번째 공장 i + 1 번째 공장, i + 2 번째 공장의 라면 개수에 따라서 구매 방식을 다르게 접근해야 한다. <br>
|
||||
|
||||
하나의 공장에서 3원으로 구매하는것 보다 두 개의 공장에서 5원으로 구매하는것이, <br>
|
||||
세 개의 공장에서 7원으로 구매하는것이 효율적이라는것은 누구나 알 수 있다. <br>
|
||||
|
||||
그래서 처음에는 현 위치 i에서 i + 1 번째와 i + 2 번째 공장과의 살 수 있는 최대한으로 묶어서 구매하는 방식으로 문제를 풀어 봤다.
|
||||
|
||||
- 3개씩 묶어서 구매
|
||||
> 1 2 3 <br>
|
||||
> 최소값인 1개씩 구매하여 <br>
|
||||
> 0 1 2 <br>
|
||||
> 을 만들면, 현 위치에서 구매 한 금액은 최소 값 1 * 7 = 7원 <br>
|
||||
|
||||
- 2개씩 묶어서 구매
|
||||
> 4 2 0 3 <br>
|
||||
> 최소 값인 2개씩 구매하여 <br>
|
||||
> 2 0 0 3 <br>
|
||||
> 0 0 0 3 <br>
|
||||
> 2 * 5 + 2 * 3 = 16원
|
||||
|
||||
|
||||
그러나 위의 방식대로 접근하니 더 효율적으로 구매하지 못하는 예외 경우가 있었다. <br>
|
||||
바로 i + 1 번째가 i + 2 번째보다 큰 경우인데, 아래를 살펴보면
|
||||
|
||||
> 2 3 2 1 <br>
|
||||
> 인근 최소값인 2개씩 구매하여 <br>
|
||||
> 0 1 0 1 <br>
|
||||
> 0 0 0 1 <br>
|
||||
> 0 0 0 0 <br>
|
||||
> (2 * 7) + (1 * 3) + (1 * 3) = 20원 <br>
|
||||
|
||||
위와 같이 20원이 나오지만, 아래와 같이 앞의 2개씩 묶어서 뒤의 수와 일치 시켜주면
|
||||
> 2 3 2 1 <br>
|
||||
> 1 2 2 1 <br>
|
||||
> 0 2 2 1 <br>
|
||||
> 0 1 1 1 <br>
|
||||
> 0 0 0 0 <br>
|
||||
> (1 * 5) + (1 * 3) + (1 * 5) + (1 * 7) = 19원
|
||||
|
||||
19원으로 더 싸게 구매가 가능한 것이다. <br>
|
||||
|
||||
이는 i + 1 번째 값이 i + 2 번째 값보다 클 경우인데, 이 때에는 i 번째의 값과 [i + 1] - [i + 2] 의 값의 최소값 만큼 앞의 두개를 묶어서 사면 다음 구매에 더 싸게 구매가 가능하게 된다.
|
||||
|
||||
따라서 아래의 두 가지 방식으로 분기하여 그리디 방식으로 최대한 이익을 내서 구매를 한다면,
|
||||
|
||||
1. [i + 1] 공장의 라면 > [i + 2] 공장의 라면 <br>
|
||||
- [i], [i + 1] - [i + 2] 중의 최소값으로 선 구매 (2묶음) <br>
|
||||
- [i], [i + 1], [i + 2] 중의 최소값으로 구매 (3묶음) <br>
|
||||
2. [i + 1] 공장의 라면 < [i + 2] 공장의 라면 <br>
|
||||
- [i], [i + 1], [i + 2] 중의 최소값으로 선 구매 (3묶음) <br>
|
||||
- [i], [i + 1] 중의 최소값으로 구매 (2묶음) <br>
|
||||
|
||||
+ [i] 의 남은 개수 구매
|
||||
|
||||
가장 최소의 금액으로 구매 할 수 있는 금액이 나오게 된다.
|
||||
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class Ramyeon_18185 {
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
int N = Integer.parseInt(st.nextToken());
|
||||
int factory[] = new int[N + 2];
|
||||
|
||||
st = new StringTokenizer(br.readLine());
|
||||
for (int i = 0; i < N; i++) {
|
||||
factory[i] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
|
||||
int answer = 0;
|
||||
for(int i = 0; i < N; i++) {
|
||||
if(factory[i] > 0) {
|
||||
// i + 1, i + 2 번 가게의 라면 유무를 확인
|
||||
// 현재 살 수 있는 가장 많은 라면을 산다.
|
||||
int min = 0;
|
||||
|
||||
if(factory[i + 1] > factory[i + 2]) {
|
||||
// i + 1의 수가 i + 2의 수보다 크면,
|
||||
// 맨 앞의 두개를 묶어서 먼저 사고, 세 개를 묶어서 사는게 싸다.
|
||||
// 이 때, [i] > [i+1] - [i+2] 의 값을 비교하여 최소값으로 구매
|
||||
min = Math.min(factory[i], factory[i + 1] - factory[i + 2]);
|
||||
answer += min * 5;
|
||||
factory[i] -= min;
|
||||
factory[i + 1] -= min;
|
||||
|
||||
min = Math.min(factory[i], Math.min(factory[i + 1], factory[i + 2]));
|
||||
answer += min * 7;
|
||||
factory[i] -= min;
|
||||
factory[i + 1] -= min;
|
||||
factory[i + 2] -= min;
|
||||
} else { // 반대는 세개 묶어 사고, 두개 묶어 사는게 싸다.
|
||||
min = Math.min(factory[i], Math.min(factory[i + 1], factory[i + 2]));
|
||||
answer += min * 7;
|
||||
factory[i] -= min;
|
||||
factory[i + 1] -= min;
|
||||
factory[i + 2] -= min;
|
||||
|
||||
min = Math.min(factory[i], factory[i + 1]);
|
||||
answer += min * 5;
|
||||
factory[i] -= min;
|
||||
factory[i + 1] -= min;
|
||||
}
|
||||
answer += factory[i] * 3;
|
||||
factory[i] = 0;
|
||||
}
|
||||
}
|
||||
|
||||
System.out.println(answer);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
@@ -0,0 +1,95 @@
|
||||
---
|
||||
title: Baekjoon online judge. 2885.초콜릿 식사
|
||||
date: 2022-03-18
|
||||
tags: algorithmsolutions, 공부, greedy
|
||||
excerpt: 2885.초콜릿 식사 - 백준온라인
|
||||
---
|
||||
# 2885.초콜릿 식사 - 백준온라인
|
||||
|
||||
해당 문제는 탐욕(greedy) 알고리즘을 사용하여 문제를 해결 했습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/2885)
|
||||
|
||||
---
|
||||
|
||||
## 2885\.초콜릿 식사
|
||||
|
||||
학교 근처 편의점에 새 초콜릿이 들어왔다. 이 초콜릿은 막대 모양이고, 각 막대는 정사각형 N개로 이루어져 있다. 초콜릿의 크기(정사각형의 개수)는 항상 2의 제곱 형태이다. 즉, 1, 2, 4, 8, 16, ...개의 정사각형으로 이루어져 있다.
|
||||
|
||||
상근이는 점심식사로 초콜릿을 먹는다. 이때, 적어도 K개 정사각형을 먹어야 남은 수업을 졸지 않고 버틸 수 있다. 상근이의 친구 선영이도 초콜릿을 좋아한다. 선영이는 초콜릿은 돈을 주고 사기 아깝다고 생각하기 때문에, 상근이가 주는 초콜릿만 먹는다.
|
||||
|
||||
상근이는 막대 초콜릿를 하나 산 다음에, 정확하게 K개 정사각형이 되도록 초콜릿을 쪼갠다. K개는 자신이 먹고 남는 것은 선영이에게 준다.
|
||||
|
||||
막대 초콜릿은 나누기 조금 어렵게 되어 있어서, 항상 가운데로만 쪼개진다. 즉, 정사각형이 D개 있는 막대는 D/2개 막대 두 조각으로 쪼개진다.
|
||||
|
||||
K개 정사각형을 만들기 위해서, 최소 몇 번 초콜릿을 쪼개야 하는지와 사야하는 가장 작은 초콜릿의 크기를 구하는 프로그램을 작성하시오. 상근이는 초콜릿을 하나만 살 수 있다. 꼭 한 조각이 K개일 필요는 없고, 여러 조각에 있는 정사각형을 합쳤을 때 K개이면 된다.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫째 줄에 K가 주어진다. (1 ≤ K ≤ 1,000,000)
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
첫째 줄에는 상근이가 구매해야하는 가장 작은 초콜릿의 크기와 최소 몇 번 쪼개야 하는지를 출력한다.
|
||||
|
||||
---
|
||||
|
||||
### 1\. 문제 풀이
|
||||
그리디 알고리즘을 이용하는 문제를 해결해보았다.
|
||||
|
||||
초콜릿이 나누어지는 경우가 무조건 D = D / 2로 반으로만 나눌 수 있고, 초콜릿의 크기는 2의 제곱 형태이다.
|
||||
|
||||
초콜릿을 반으로 나누면 나누어진 초콜릿 중 반 쪽은 그 상태로 남고, 다른 반 쪽으로 다시 나누기를 시도하여 이 초콜릿의 누적 개수가 K가 되면 되는 문제이다.
|
||||
|
||||
계속 나누다보면 결국에는 2 = 1 + 1이 될 것이니, 필요한 K의 갯수보다 한 제곱 더 큰 초콜릿을 사면 되는 것이다.
|
||||
|
||||
> K = 6 <br>
|
||||
> $$2^2 = 4$$
|
||||
> $$2^3 = 8$$
|
||||
> 이므로 4 < K < 8 <br>
|
||||
> 8의 초콜릿을 구매 <br>
|
||||
|
||||
위의 방식대로 초콜릿을 구매하고, 남은 개수는 다른 반쪽을 나누어가며 채워가면 된다.
|
||||
|
||||
> 8을 나누어 4개 | 4개 <br>
|
||||
> 반쪽인 4개를 K에서 제외하고, 다른 반쪽을 나눈다. <br>
|
||||
> K(6) - 4 = 2 <br>
|
||||
> 4을 나누어 2개 | 2개 <br>
|
||||
> 반쪽인 2개를 K에서 제외하면 정량이 된다. <br>
|
||||
> K(2) - 2 = 0 <br>
|
||||
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
---
|
||||
|
||||
```java
|
||||
import java.util.Scanner;
|
||||
|
||||
public class ChocolateEat_2885 {
|
||||
public static void main(String[] args) {
|
||||
Scanner sc = new Scanner(System.in);
|
||||
int K = sc.nextInt();
|
||||
int D = 0;
|
||||
int i = 0;
|
||||
|
||||
while(D < K) {
|
||||
D = (int)Math.pow(2, i); // 1, 2, 4, 8, 16...
|
||||
i++;
|
||||
}
|
||||
|
||||
int size = D, cnt = 0;
|
||||
while(K > 0) {
|
||||
if(K >= D) {
|
||||
K -= D;
|
||||
} else {
|
||||
D /= 2;
|
||||
cnt++;
|
||||
}
|
||||
}
|
||||
|
||||
System.out.println(size + " " + cnt);
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,271 @@
|
||||
---
|
||||
title: Baekjoon online judge. 8980.택배
|
||||
date: 2022-03-26
|
||||
tags: algorithmsolutions, 공부, greedy
|
||||
excerpt: 8980.택배 - 백준온라인
|
||||
---
|
||||
# 8980.택배 - 백준온라인
|
||||
해당 문제는 그리디 방식으로 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/8980)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|1 초|128 MB|
|
||||
|
||||
직선 도로상에 왼쪽부터 오른쪽으로 1번부터 차례대로 번호가 붙여진 마을들이 있다. 마을에 있는 물건을 배송하기 위한 트럭 한 대가 있고, 트럭이 있는 본부는 1번 마을 왼쪽에 있다. 이 트럭은 본부에서 출발하여 1번 마을부터 마지막 마을까지 오른쪽으로 가면서 마을에 있는 물건을 배송한다.
|
||||
|
||||
각 마을은 배송할 물건들을 박스에 넣어 보내며, 본부에서는 박스를 보내는 마을번호, 박스를 받는 마을번호와 보낼 박스의 개수를 알고 있다. 박스들은 모두 크기가 같다. 트럭에 최대로 실을 수 있는 박스의 개수, 즉 트럭의 용량이 있다. 이 트럭 한대를 이용하여 다음의 조건을 모두 만족하면서 최대한 많은 박스들을 배송하려고 한다.
|
||||
|
||||
- 조건 1: 박스를 트럭에 실으면, 이 박스는 받는 마을에서만 내린다.
|
||||
- 조건 2: 트럭은 지나온 마을로 되돌아가지 않는다.
|
||||
- 조건 3: 박스들 중 일부만 배송할 수도 있다.
|
||||
|
||||
마을의 개수, 트럭의 용량, 박스 정보(보내는 마을번호, 받는 마을번호, 박스 개수)가 주어질 때, 트럭 한 대로 배송할 수 있는 최대 박스 수를 구하는 프로그램을 작성하시오. 단, 받는 마을번호는 보내는 마을번호보다 항상 크다.
|
||||
|
||||
예를 들어, 트럭 용량이 40이고 보내는 박스들이 다음 표와 같다고 하자.
|
||||
|
||||
|보내는 마을|받는 마을|박스 개수|
|
||||
|------|------|----|
|
||||
|1|2|10|
|
||||
|1|3|20|
|
||||
|1|4|30|
|
||||
|2|3|10|
|
||||
|2|4|20|
|
||||
|3|4|20|
|
||||
|
||||
이들 박스에 대하여 다음과 같이 배송하는 방법을 고려해 보자.
|
||||
|
||||
(1) 1번 마을에 도착하면
|
||||
- 다음과 같이 박스들을 트럭에 싣는다. (1번 마을에서 4번 마을로 보내는 박스는 30개 중 10개를 싣는다.)
|
||||
|
||||
|보내는 마을|받는 마을|박스 개수|
|
||||
|------|------|----|
|
||||
|1|2|10|
|
||||
|1|3|20|
|
||||
|1|4|30|
|
||||
|
||||
(2) 2번 마을에 도착하면
|
||||
- 트럭에 실려진 박스들 중 받는 마을번호가 2인 박스 10개를 내려 배송한다. (이때 트럭에 남아있는 박스는 30개가 된다.)
|
||||
- 그리고 다음과 같이 박스들을 싣는다. (이때 트럭에 실려 있는 박스는 40개가 된다.)
|
||||
|
||||
|보내는 마을|받는 마을|박스 개수|
|
||||
|------|------|----|
|
||||
|2|3|10|
|
||||
|
||||
(3) 3번 마을에 도착하면
|
||||
- 트럭에 실려진 박스들 중 받는 마을번호가 3인 박스 30개를 내려 배송한다. (이때 트럭에 남아있는 박스는 10개가 된다.)
|
||||
- 그리고 다음과 같이 박스들을 싣는다. (이때 트럭에 실려 있는 박스는 30개가 된다.)
|
||||
|
||||
|보내는 마을|받는 마을|박스 개수|
|
||||
|------|------|----|
|
||||
|3|4|20|
|
||||
|
||||
(4) 4번 마을에 도착하면
|
||||
- 받는 마을번호가 4인 박스 30개를 내려 배송한다.
|
||||
|
||||
위와 같이 배송하면 배송한 전체 박스는 70개이다. 이는 배송할 수 있는 최대 박스 개수이다.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
입력의 첫 줄은 마을 수 N과 트럭의 용량 C가 빈칸을 사이에 두고 주어진다. N은 2이상 2,000이하 정수이고, C는 1이상 10,000이하 정수이다. 다음 줄에, 보내는 박스 정보의 개수 M이 주어진다. M은 1이상 10,000이하 정수이다. 다음 M개의 각 줄에 박스를 보내는 마을번호, 박스를 받는 마을번호, 보내는 박스 개수(1이상 10,000이하 정수)를 나타내는 양의 정수가 빈칸을 사이에 두고 주어진다. 박스를 받는 마을번호는 보내는 마을번호보다 크다.
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
트럭 한 대로 배송할 수 있는 최대 박스 수를 한 줄에 출력한다.
|
||||
|
||||
---
|
||||
|
||||
## 서브태스크
|
||||
|
||||
|번호|배점|제한|
|
||||
|--|---|---------------|
|
||||
|1|15|보내는 마을번호는 모두 1, N ≤ 20|
|
||||
|2|17|받는 마을번호는 N-1 또는 N, 3 ≤ N ≤ 20|
|
||||
|3|20|N ≤ 5, M ≤ 5, C ≤ 10|
|
||||
|4|23|N ≤ 100, M ≤ 1,000, C ≤ 2,000|
|
||||
|5|25|추가적인 제약조건은 없다.|
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
처음에 그냥 그리디적 가벼운 접근으로 해결하려고 하니 답이 나오지 않았다.
|
||||
주어진 조건에서 택배의 거리로 짧은 순서대로 정렬하고 현 위치에서 싣을 수 있는 가장 많은 택배만큼 싣고 가려고 했었다.
|
||||
|
||||
그러나 그렇게 접근하니 예외처리를 해야하는 부분에서 오류가 발생하였다.
|
||||
|
||||
몇 시간을 헤매이다가 결국에는 힌트를 보고서 문제를 해결 할 수 있었다.
|
||||
|
||||
1. 마을 별로 내리는 짐의 개수 대신에 K 마을에 방문해서 짐을 내린 후, 트럭에 싣고 있는 박스의 개수를 파악한다.
|
||||
2. 보내는 마을과 받는 마을의 거리가 멀수록 보내는 마을로부터 다음 마을들을 순차적으로 방문할 때마다 받는 마을 바로 직전의 마을까지 짐을 계속해서 들고 있어야 한다.
|
||||
+ 그 사이에 더 큰 짐을 싣고 내리는 경우가 있을 수 있기 때문에 보내는 마을과 받는 마을의 거리가 멀면 그만큼 손해를 볼 수 있다.
|
||||
3. **'무조건 1번 마을부터 N번 마을까지 순차적으로 방문한다는 조건'** & **'보내는 마을보다 무조건 받는 마을의 번호가 높다는 조건'** 이 두 조건을 활용하는 것으로 문제를 풀 수 있다.
|
||||
|
||||
그렇다면 보내는 마을이 받는 마을과 거리가 가깝다는 뜻은 받는 마을의 번호를 오름차순으로 정렬했을 때 가장 앞에 있을수록 가깝다는 뜻이 된다.
|
||||
|
||||
그 다음 우선순위로는 보내는 마을을 오름차순으로 정렬하는 것이다.
|
||||
** 두 번째 우선순위는 굳이 안해도 풀 수 있다.
|
||||
|
||||
즉! 아래의 단계로 해결 할 수 있었다.
|
||||
1. 받는 마을 번호를 오름차순으로 정렬
|
||||
2. 각 마을 별로 박스의 개수를 파악할 수 있는 Array 생성
|
||||
3. 앞에서부터 (보내는 마을, 받는 마을, 박스 개수) 를 꺼내서 사용
|
||||
** 참고로, 받는 마을에서 박스 개수는 고려하지 않는다. 도착하면 박스를 내리기 때문에
|
||||
|
||||
2의 추가 내용
|
||||
- 정렬 후
|
||||
|
||||
|보내는 마을|받는 마을|박스 개수|
|
||||
|------|------|----|
|
||||
|1|2|10|
|
||||
|2|3|10|
|
||||
|1|3|20|
|
||||
|3|4|20|
|
||||
|2|4|20|
|
||||
|1|4|30|
|
||||
|
||||
3) 추가 내용
|
||||
- 1번 째 꺼낸 경우
|
||||
|
||||
>
|
||||
트럭의 용량 : 40
|
||||
마을 : 1 // 2 // 3 // 4
|
||||
마을에서의 트럭에 싣은 박스 개수 : 10 // 0 // 0 // 0 ( +10 내림 = 10)
|
||||
|
||||
- 2번 째 꺼낸 경우
|
||||
|
||||
>
|
||||
트럭의 용량 : 40
|
||||
마을 : 1 // 2 // 3 // 4
|
||||
마을에서의 트럭에 싣은 박스 개수 : 10 // 10 // 0 // 0 ( + 10 내림 = 20)
|
||||
|
||||
- 3번 째 꺼낸 경우
|
||||
|
||||
>
|
||||
트럭의 용량 : 40
|
||||
마을 : 1 // 2 // 3 // 4
|
||||
마을에서의 트럭에 싣은 박스 개수 : 30(+20) // 30(+20) // 0 // 0 ( + 20 내림 = 40)
|
||||
|
||||
- 4번 째 꺼낸 경우
|
||||
|
||||
>
|
||||
트럭의 용량 : 40
|
||||
마을 : 1 // 2 // 3 // 4
|
||||
마을에서의 트럭에 싣은 박스 개수 : 30 // 30 // 20(+ 20) // 0 ( + 20 내림 = 60)
|
||||
|
||||
- 5번 째 꺼낸 경우
|
||||
|
||||
>
|
||||
트럭의 용량 : 40
|
||||
마을 : 1 // 2 // 3 // 4
|
||||
마을에서의 트럭에 싣은 박스 개수 : 30 // 40(+10) // 30(+ 10) // 0 ( + 10 내림 = 70)
|
||||
** 트럭의 용량이 40이기 때문에 2번 마을에 박스가 20개나 있음에도 불구하고 10만 싣을 수 있다.
|
||||
** 3번 마을에는 2번에서 10만 싣었으니 당연히 10이 추가된다.
|
||||
|
||||
- 6번 째 꺼낸 경우
|
||||
|
||||
>
|
||||
트럭의 용량 : 40
|
||||
마을 : 1 // 2 // 3 // 4
|
||||
마을에서의 트럭에 싣은 박스 개수 : 30 // 40 // 30 // 0 ( + 0 내림 = 70)
|
||||
|
||||
따라서 최대 옮기는 박스의 개수는 70개가 된다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 소스 코드
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.ArrayList;
|
||||
import java.util.Collections;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class ParcelService_8980 {
|
||||
public int solution(int n, int c, ArrayList<TownBoxes> townboxes) {
|
||||
Collections.sort(townboxes);
|
||||
|
||||
int[] boxes = new int[n + 1];
|
||||
int boxCount = 0;
|
||||
for(TownBoxes town : townboxes) {
|
||||
int start = town.start;
|
||||
int end = town.end;
|
||||
int box = town.boxes;
|
||||
|
||||
int max = 0;
|
||||
boolean isLoad = true;
|
||||
for(int i = start; i < end; i++) {
|
||||
if(boxes[i] >= c) {
|
||||
isLoad = false;
|
||||
break;
|
||||
}
|
||||
max = Math.max(boxes[i], max);
|
||||
}
|
||||
|
||||
if(isLoad) {
|
||||
int dropOff = c - max;
|
||||
if(dropOff > box) {
|
||||
dropOff = box;
|
||||
}
|
||||
boxCount += dropOff;
|
||||
|
||||
for(int i = start; i < end; i++) {
|
||||
boxes[i] += dropOff;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return boxCount;
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
ParcelService_8980 mc = new ParcelService_8980();
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
int N = Integer.parseInt(st.nextToken());
|
||||
int C = Integer.parseInt(st.nextToken());
|
||||
|
||||
st = new StringTokenizer(br.readLine());
|
||||
int M = Integer.parseInt(st.nextToken());
|
||||
ArrayList<TownBoxes> boxes = new ArrayList<>();
|
||||
for (int i = 0; i < M; i++) {
|
||||
st = new StringTokenizer(br.readLine());
|
||||
int start = Integer.parseInt(st.nextToken());
|
||||
int end = Integer.parseInt(st.nextToken());
|
||||
int box = Integer.parseInt(st.nextToken());
|
||||
boxes.add(new TownBoxes(start, end, box));
|
||||
}
|
||||
|
||||
System.out.println(mc.solution(N, C, boxes));
|
||||
}
|
||||
}
|
||||
|
||||
class TownBoxes implements Comparable<TownBoxes> {
|
||||
int start = 0;
|
||||
int end = 0;
|
||||
int boxes = 0;
|
||||
TownBoxes(int start, int end, int boxes) {
|
||||
this.start = start;
|
||||
this.end = end;
|
||||
this.boxes = boxes;
|
||||
}
|
||||
|
||||
@Override
|
||||
public int compareTo(TownBoxes box) {
|
||||
if(this.end == box.end) return this.start - box.start;
|
||||
else return this.end - box.end;
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,78 @@
|
||||
---
|
||||
title: Algorithm 강의 02-06.뒤집은 소수
|
||||
date: 2022-03-27
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 02-06.뒤집은 소수
|
||||
---
|
||||
# 02-06.뒤집은 소수
|
||||
알고리즘 강의를 듣고 푸는 중에 기록할 만한 내용을 기록해 봅니다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
N개의 자연수가 입력되면 각 자연수를 뒤집은 후 그 뒤집은 수가 소수이면 그 소수를 출력하 는 프로그램을 작성하세요. 예를 들어 32를 뒤집으면 23이고, 23은 소수이다. 그러면 23을 출 력한다. 단 910를 뒤집으면 19로 숫자화 해야 한다. 첫 자리부터의 연속된 0은 무시한다.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫 줄에 자연수의 개수 N(3<=N<=100)이 주어지고, 그 다음 줄에 N개의 자연수가 주어진다. 각 자연수의 크기는 100,000를 넘지 않는다.
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
첫 줄에 뒤집은 소수를 출력합니다. 출력순서는 입력된 순서대로 출력합니다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
```java
|
||||
import java.util.ArrayList;
|
||||
import java.util.Scanner;
|
||||
|
||||
class problem_02_06 {
|
||||
public boolean isPrime(int num) {
|
||||
if(num == 1) return false;
|
||||
for(int i = 2; i < num; i++) {
|
||||
if(num % i == 0) return false;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
public ArrayList<Integer> solution(int N, int[] arr) {
|
||||
ArrayList<Integer> list = new ArrayList<>();
|
||||
|
||||
for(int i = 0; i < N; i++) {
|
||||
int tmp = arr[i];
|
||||
int res = 0;
|
||||
while(tmp > 0) {
|
||||
int t = tmp % 10;
|
||||
res = res * 10 + t;
|
||||
tmp = tmp / 10;
|
||||
}
|
||||
|
||||
if(isPrime(res)) list.add(res);
|
||||
}
|
||||
|
||||
return list;
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
problem_02_06 mc = new problem_02_06();
|
||||
Scanner sc = new Scanner(System.in);
|
||||
int N = sc.nextInt();
|
||||
int[] arr = new int[N];
|
||||
for(int i = 0; i < N; i++) {
|
||||
arr[i] = sc.nextInt();
|
||||
}
|
||||
for(int x : mc.solution(N, arr)) {
|
||||
System.out.print(x + " ");
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
@@ -0,0 +1,118 @@
|
||||
---
|
||||
title: Baekjoon online judge. 6198.옥상 정원 꾸미기
|
||||
date: 2022-03-29
|
||||
tags: algorithmsolutions, 공부, stack
|
||||
excerpt: 6198.옥상 정원 꾸미기 - 백준온라인
|
||||
---
|
||||
# 6198.옥상 정원 꾸미기 - 백준온라인
|
||||
해당 문제는 스택(stack) 자료구조를 활용하여 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/6198)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|1 초|128 MB|
|
||||
|
||||
도시에는 N개의 빌딩이 있다.
|
||||
|
||||
빌딩 관리인들은 매우 성실 하기 때문에, 다른 빌딩의 옥상 정원을 벤치마킹 하고 싶어한다.
|
||||
|
||||
i번째 빌딩의 키가 hi이고, 모든 빌딩은 일렬로 서 있고 오른쪽으로만 볼 수 있다.
|
||||
|
||||
i번째 빌딩 관리인이 볼 수 있는 다른 빌딩의 옥상 정원은 i+1, i+2, .... , N이다.
|
||||
|
||||
그런데 자신이 위치한 빌딩보다 높거나 같은 빌딩이 있으면 그 다음에 있는 모든 빌딩의 옥상은 보지 못한다.
|
||||
|
||||
예) N=6, H = {10, 3, 7, 4, 12, 2}인 경우
|
||||
|
||||
```
|
||||
=
|
||||
= =
|
||||
= - =
|
||||
= = = -> 관리인이 보는 방향
|
||||
= - = = =
|
||||
= = = = = =
|
||||
10 3 7 4 12 2 -> 빌딩의 높이
|
||||
[1][2][3][4][5][6] -> 빌딩의 번호
|
||||
```
|
||||
|
||||
- 1번 관리인은 2, 3, 4번 빌딩의 옥상을 확인할 수 있다.
|
||||
- 2번 관리인은 다른 빌딩의 옥상을 확인할 수 없다.
|
||||
- 3번 관리인은 4번 빌딩의 옥상을 확인할 수 있다.
|
||||
- 4번 관리인은 다른 빌딩의 옥상을 확인할 수 없다.
|
||||
- 5번 관리인은 6번 빌딩의 옥상을 확인할 수 있다.
|
||||
- 6번 관리인은 마지막이므로 다른 빌딩의 옥상을 확인할 수 없다.
|
||||
|
||||
따라서, 관리인들이 옥상정원을 확인할 수 있는 총 수는 3 + 0 + 1 + 0 + 1 + 0 = 5이다.
|
||||
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
- 첫 번째 줄에 빌딩의 개수 N이 입력된다.(1 ≤ N ≤ 80,000)
|
||||
- 두 번째 줄 부터 N+1번째 줄까지 각 빌딩의 높이가 hi 입력된다. (1 ≤ hi ≤ 1,000,000,000)
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
- 각 관리인들이 벤치마킹이 가능한 빌딩의 수의 합을 출력한다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
처음에는 입력의 상세를 보지 않고 평소처럼 int형을 사용해서 문제를 풀려고 했었다. 그러니 틀렸습니다가 나오고, 틀린 방향을 못 찾아서 고민했었다. 이 문제는 높이의 범위가 있기 때문에 long 타입을 선언해야 정확한 답을 구할 수 있다.
|
||||
|
||||
문제 해결을 위해서는 Stack을 잘 활용 할 수 있어야 해결 할 수 있었다.
|
||||
이중 배열을 설정해서 뒤의 높이가 현 위치 빌딩보다 높거나 같으면 탈출하는 방식으로 문제를 접근했었는데, 그러니 했었다.
|
||||
|
||||
그래서 Stack의 성질을 이용하여 입력의 앞부터 비교하여 추가하며 최종적으로 각 관리인들이 벤치마킹 가능한 빌딩의 수 합을 구할 수 있었다.
|
||||
|
||||
|
||||
```java
|
||||
import java.io.IOException;
|
||||
import java.util.Scanner;
|
||||
import java.util.Stack;
|
||||
|
||||
public class RooftopGarden_6198 {
|
||||
public long solution(long[] b) {
|
||||
long answer = 0;
|
||||
int bLen = b.length;
|
||||
Stack<Long> st = new Stack<>();
|
||||
|
||||
for(int i = 0; i < bLen; i++) {
|
||||
|
||||
while(!st.isEmpty()) {
|
||||
if(st.peek() <= b[i]) st.pop();
|
||||
else break;
|
||||
}
|
||||
|
||||
answer += st.size();
|
||||
st.add(b[i]);
|
||||
}
|
||||
|
||||
return answer;
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
RooftopGarden_6198 mc = new RooftopGarden_6198();
|
||||
Scanner sc = new Scanner(System.in);
|
||||
int N = sc.nextInt();
|
||||
|
||||
long[] building = new long[N];
|
||||
for(int i = 0; i < N; i++) {
|
||||
building[i] = sc.nextLong();
|
||||
}
|
||||
|
||||
System.out.println(mc.solution(building));
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
@@ -0,0 +1,152 @@
|
||||
---
|
||||
title: Baekjoon online judge. 1717.집합의 표현
|
||||
date: 2022-03-30
|
||||
tags: algorithmsolutions, 공부, union-find
|
||||
excerpt: 1717.집합의 표현 - 백준온라인
|
||||
---
|
||||
# 1717.집합의 표현 - 백준온라인
|
||||
해당 문제는 union, find 라는 알고리즘 기법을 활용하여 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/1717)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|2 초|128 MB|
|
||||
|
||||
초기에 {0}, {1}, {2}, ... {n} 이 각각 n+1개의 집합을 이루고 있다. 여기에 합집합 연산과, 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산을 수행하려고 한다.
|
||||
|
||||
집합을 표현하는 프로그램을 작성하시오.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫째 줄에 n(1 ≤ n ≤ 1,000,000), m(1 ≤ m ≤ 100,000)이 주어진다. m은 입력으로 주어지는 연산의 개수이다. 다음 m개의 줄에는 각각의 연산이 주어진다. 합집합은 0 a b의 형태로 입력이 주어진다. 이는 a가 포함되어 있는 집합과, b가 포함되어 있는 집합을 합친다는 의미이다. 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산은 1 a b의 형태로 입력이 주어진다. 이는 a와 b가 같은 집합에 포함되어 있는지를 확인하는 연산이다. a와 b는 n 이하의 자연수 또는 0이며 같을 수도 있다.
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
1로 시작하는 입력에 대해서 한 줄에 하나씩 YES/NO로 결과를 출력한다. (yes/no 를 출력해도 된다)
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
이 문제는 이전에 SSAFY를 다니면서 알고리즘 수업 시간에 배웠던 union, find 방법을 활용해서 문제를 풀어볼 수 있었다.
|
||||
|
||||
오랜된 기억이라서 처음에는 헤매기도 했지만 정리해둔 내용을 다시 생각해보며 더듬어가면서 풀었다.
|
||||
|
||||
union, find 방법에 대해서 다시 한 번 정리하자면 체크 할 멤버들의 수의 배열에 해당 연관이 있는지 표시를 하고, 같은 그룹인지 아닌지 확인 할 수 있는 방법이다.
|
||||
|
||||
이 문제에서의 조건은 0 입력이 들어오면 find로 찾아서 union으로 묶고, 1 입력이 들어오면 find로 찾아서 표출해 주라고 한다.
|
||||
|
||||
```
|
||||
[0][1][2][3][4][5]
|
||||
-1 -1 -1 -1 -1 -1
|
||||
|
||||
처음에는 그룹이 없다고 하여 위와 같이 세팅을 한다.
|
||||
```
|
||||
|
||||
부모 배열을 선언하고 union, find의 방법을 각각 정의 한다.
|
||||
|
||||
union은 같은 그룹인지 먼저 찾아봐야 하므로 find를 먼저 정의해보자.
|
||||
|
||||
찾고자하는 수의 배열 위치를 확인하여 해당 그룹이 존재하면 재귀의 방법으로 최종 root를 찾는다.
|
||||
|
||||
```
|
||||
[0][1][2][3][4][5]
|
||||
-1 -1 -1 1 -1 3
|
||||
|
||||
find(5);
|
||||
-> 5를 find 하면 해당 부모 배열에서 3을 찾을 수 있다.
|
||||
그러면 3을 다시 find한다.
|
||||
|
||||
find(3)
|
||||
-> 3을 find 하면 부모 배열에서 1을 찾을 수 있다.
|
||||
그러면 1을 다시 find한다.
|
||||
|
||||
find(1)
|
||||
-> 1을 find하면 -1 즉, 최상단 부모라는 뜻이된다.
|
||||
|
||||
그러면 1-3-5 의 트리와 같은 구조로 그룹을 그려 볼 수 있게 된다.
|
||||
```
|
||||
|
||||
위와 같이 find의 방법을 설명했다면 이번에는 union을 알아본다.
|
||||
```
|
||||
[0][1][2][3][4][5]
|
||||
-1 -1 -1 1 2 3
|
||||
|
||||
union(4, 5)가 되면 각각의 4와 5의 최상단을 find로 찾아낸다.
|
||||
find(5) => 1 || find(4) => 2
|
||||
가 되는 것을 볼 수 있다.
|
||||
```
|
||||
|
||||
이 둘은 다른 그룹이기 때문에 합칠 수 있다.
|
||||
각각의 루트를 찾았기 때문에 이제 어느 한 쪽의 루트를 다른쪽의 루트의 자식으로 넣어주기만 하면 된다.
|
||||
1을 2의 자식으로 넣게되면 parents[1] = 2 가 되겠다.
|
||||
|
||||
그러면 결국 union 후의 모습은 논리적으로 아래와 같을 것이다.
|
||||
|
||||
```
|
||||
[0] [1] [2] [3] : depth
|
||||
2 - 1 - 3 - 5
|
||||
- 4
|
||||
```
|
||||
|
||||
이러한 방식을 이용하여 집합을 표현하고 묶어줄 수 있다.
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.Arrays;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class SetRepre_1717 {
|
||||
static int[] parents;
|
||||
private static boolean union(int a, int b) {
|
||||
int aRoot = find(a);
|
||||
int bRoot = find(b);
|
||||
if(aRoot != bRoot) {
|
||||
parents[bRoot] = aRoot;
|
||||
return true;
|
||||
}
|
||||
return false;
|
||||
}
|
||||
private static int find(int a) {
|
||||
if(parents[a] < 0) return a;
|
||||
return parents[a] = find(parents[a]);
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
int n = Integer.parseInt(st.nextToken());
|
||||
int m = Integer.parseInt(st.nextToken());
|
||||
parents = new int[n + 1];
|
||||
Arrays.fill(parents, -1);
|
||||
for(int i = 0; i < m; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
// 합집합은 0 a b의 형태로 입력이 주어진다. 이는 a가 포함되어 있는 집합과, b가 포함되어 있는 집합을 합친다는 의미
|
||||
int condition = Integer.parseInt(st.nextToken());
|
||||
int a = Integer.parseInt(st.nextToken());
|
||||
int b = Integer.parseInt(st.nextToken());
|
||||
if(condition == 0) {
|
||||
union(a, b);
|
||||
} else { // 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산은 1 a b
|
||||
if(find(a) == find(b)) System.out.println("YES");
|
||||
else System.out.println("NO");
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,138 @@
|
||||
---
|
||||
title: Baekjoon online judge. 2302.극장 좌석
|
||||
date: 2022-04-05
|
||||
tags: algorithmsolutions, 공부, DP
|
||||
excerpt: 2302.극장 좌석 - 백준온라인
|
||||
---
|
||||
# 2302.극장 좌석 - 백준온라인
|
||||
해당 문제는 DP 알고리즘 기법을 활용하여 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/2302)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|2 초|128 MB|
|
||||
|
||||
어떤 극장의 좌석은 한 줄로 되어 있으며 왼쪽부터 차례대로 1번부터 N번까지 번호가 매겨져 있다. 공연을 보러 온 사람들은 자기의 입장권에 표시되어 있는 좌석에 앉아야 한다. 예를 들어서, 입장권에 5번이 쓰여 있으면 5번 좌석에 앉아야 한다. 단, 자기의 바로 왼쪽 좌석 또는 바로 오른쪽 좌석으로는 자리를 옮길 수 있다. 예를 들어서, 7번 입장권을 가진 사람은 7번 좌석은 물론이고, 6번 좌석이나 8번 좌석에도 앉을 수 있다. 그러나 5번 좌석이나 9번 좌석에는 앉을 수 없다.
|
||||
|
||||
그런데 이 극장에는 “VIP 회원”들이 있다. 이 사람들은 반드시 자기 좌석에만 앉아야 하며 옆 좌석으로 자리를 옮길 수 없다.
|
||||
|
||||
오늘 공연은 입장권이 매진되어 1번 좌석부터 N번 좌석까지 모든 좌석이 다 팔렸다. VIP 회원들의 좌석 번호들이 주어졌을 때, 사람들이 좌석에 앉는 서로 다른 방법의 가짓수를 구하는 프로그램을 작성하시오.
|
||||
|
||||
예를 들어서, 그림과 같이 좌석이 9개이고, 4번 좌석과 7번 좌석이 VIP석인 경우에 <123456789>는 물론 가능한 배치이다. 또한 <213465789> 와 <132465798> 도 가능한 배치이다. 그러나 <312456789> 와 <123546789> 는 허용되지 않는 배치 방법이다.
|
||||
|
||||

|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫째 줄에는 좌석의 개수 N이 입력된다. N은 1 이상 40 이하이다. 둘째 줄에는 고정석의 개수 M이 입력된다. M은 0 이상 N 이하이다. 다음 M 개의 줄에는 고정석의 번호가 작은 수부터 큰 수의 순서로 한 줄에 하나씩 입력된다.
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
주어진 조건을 만족하면서 사람들이 좌석에 앉을 수 있는 방법의 가짓수를 출력한다. 방법의 가짓수는 2,000,000,000을 넘지 않는다. (2,000,000,000 < 231-1)
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
이 문제를 DP 방식으로 풀기 위해서 점화식을 먼저 세워 보기로 했다.
|
||||
|
||||
```
|
||||
좌석이 1개인 경우
|
||||
-> [1]
|
||||
```
|
||||
|
||||
```
|
||||
좌석이 2개인 경우
|
||||
-> [1][2]
|
||||
-> [2][1]
|
||||
```
|
||||
|
||||
```
|
||||
좌석이 3개인 경우
|
||||
-> [1][2][3]
|
||||
-> [1][3][2]
|
||||
-> [2][1][3]
|
||||
```
|
||||
|
||||
```
|
||||
좌석이 4개인 경우
|
||||
-> [1][2][3][4]
|
||||
-> [1][2][4][3]
|
||||
-> [1][3][2][4]
|
||||
-> [2][1][3][4]
|
||||
-> [2][1][4][3]
|
||||
-> [1][3][2][4]
|
||||
```
|
||||
|
||||
좌석이 5개인 경우부터는 경우의 수가 많아지니 노가다로 쉽게 얻을 수 있는 여기까지만 알아보면,
|
||||
수열의 합이 [1,2,3,5]를 얻을 수 있다.
|
||||
따라서 <code>dp[i] = dp[i - 1] + dp[i - 2];</code> 의 형태로 보인다.
|
||||
|
||||
이렇게 연속한 좌석 수에 따른 경우의 수를 알았으므로 VIP석으로 인해서 구분된 좌석의 연속 수를 저장해서 해당하는 모든 DP 값을 곱해주면 구하고자 하는 모든 경우의 수를 구할 수 있다.
|
||||
|
||||
여기서 5개인 경우의 수를 구할 때, DP를 구하는 방식처럼 쪼개서 생각해보면
|
||||
아래는 **좌석 5개를 4개 1개로 나누어 생각해 본 경우**이다.
|
||||
```markdown
|
||||
[1][2][3][4] [5]
|
||||
DP[5] = DP[4] * DP[1] = 5 * 1 = 5
|
||||
```
|
||||
|
||||
위의 경우처럼 쪼개서 구한 경우의 수와 중복되지 않을 수 있는 경우는 무엇이 있을지 생각해보자.
|
||||
|
||||
마지막 `5`번 좌석이 바로 앞으로 가는 경우를 생각해 볼 수 있다.
|
||||
|
||||
```markdown
|
||||
[1][2][3] [5][4]
|
||||
뒤쪽의 2개의 좌석은 5 4 로 고정이다.
|
||||
5가 맨 마지막에 오는 경우는 앞의 DP[5] = DP[4] * DP[1] 에서 구했다.
|
||||
|
||||
*DP[3] * DP[2]가 아님에 주의!!*
|
||||
```
|
||||
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
|
||||
public class Theater_2302 {
|
||||
public static int seat[];
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
int N = Integer.parseInt(br.readLine());
|
||||
int M = Integer.parseInt(br.readLine());
|
||||
|
||||
seat = new int[N + 1];
|
||||
|
||||
seat[0] = 1;
|
||||
seat[1] = 1;
|
||||
seat[2] = 2;
|
||||
for(int i = 3; i <= N; i++) {
|
||||
seat[i] = seat[i - 1] + seat[i - 2];
|
||||
}
|
||||
|
||||
int result = 1, prev = 0;
|
||||
for(int i = 0; i < M; i++) {
|
||||
int temp = Integer.parseInt(br.readLine());
|
||||
result *= seat[temp - prev - 1];
|
||||
prev = temp;
|
||||
}
|
||||
result *= seat[N - prev];
|
||||
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,197 @@
|
||||
---
|
||||
title: Baekjoon online judge. 20166.문자열 지옥에 빠진 호석
|
||||
date: 2022-04-06
|
||||
tags: algorithmsolutions, 공부, 완전탐색
|
||||
excerpt: 20166.문자열 지옥에 빠진 호석 - 백준온라인
|
||||
---
|
||||
# 20166.문자열 지옥에 빠진 호석 - 백준온라인
|
||||
해당 문제는 제한 조건이 있었기 때문이라도 완전 탐색 활용하여 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/20166)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|1 초|512 MB|
|
||||
|
||||
하루 종일 내리는 비에 세상이 출렁이고 구름이 해를 먹어 밤인지 낮인지 모르는 어느 여름 날
|
||||
|
||||
잠 들기 싫어 버티던 호석이는 무거운 눈꺼풀에 패배했다. 정신을 차려보니 바닥에는 격자 모양의 타일이 가득한 세상이었고, 각 타일마다 알파벳 소문자가 하나씩 써있다더라. 두려움에 가득해 미친듯이 앞만 보고 달려 끝을 찾아 헤맸지만 이 세상은 끝이 없었고, 달리다 지쳐 바닥에 드러누우니 하늘에 이런 문구가 핏빛 구름으로 떠다니고 있었다.
|
||||
|
||||
- 이 세상은 N행 M열의 격자로 생겼으며, 각 칸에 알파벳이 써있고 환형으로 이어진다. 왼쪽 위를 (1, 1), 오른쪽 아래를 (N, M)이라고 하자.
|
||||
- 너는 아무 곳에서나 시작해서 상하좌우나 대각선 방향의 칸으로 한 칸씩 이동할 수 있다. 이 때, 이미 지나 왔던 칸들을 다시 방문하는 것은 허용한다.
|
||||
- 시작하는 격자의 알파벳을 시작으로, 이동할 때마다 각 칸에 써진 알파벳을 이어 붙여서 문자열을 만들 수 있다.
|
||||
- 이 곳의 신인 내가 좋아하는 문자열을 K 개 알려줄 터이니, 각 문자열 마다 너가 만들 수 있는 경우의 수를 잘 대답해야 너의 세계로 돌아갈 것이다.
|
||||
- 경우의 수를 셀 때, 방문 순서가 다르면 다른 경우이다. 즉, (1,1)->(1,2) 로 가는 것과 (1,2)->(1,1) 을 가는 것은 서로 다른 경우이다.
|
||||
|
||||
|
||||
호석이는 하늘을 보고서 "환형이 무엇인지는 알려달라!" 며 소리를 지르니 핏빛 구름이 흩어졌다가 모이며 아래와 같은 말을 그렸다.
|
||||
|
||||
- 너가 1행에서 위로 가면 N 행으로 가게 되며 반대도 가능하다.
|
||||
- 너가 1열에서 왼쪽으로 가면 M 열로 가게 되며 반대도 가능하다.
|
||||
- 대각선 방향에 대해서도 동일한 규칙이 적용된다.
|
||||
- 하늘에 아래와 같은 그림을 구름으로 그려줄 터이니 이해해 돕도록 하여라.
|
||||
- 예를 들어서, 너가 (1, 1)에서 위로 가면 (N, 1)이고, 왼쪽으로 가면 (1, M)이며 왼쪽 위 대각선 방향으로 가면 (N, M)인 것이다.
|
||||
|
||||
|
||||
|
||||
세상을 이루는 격자의 정보와, K 개의 문자열이 주어졌을 때, 호석이가 대답해야 하는 정답을 구해주도록 하자.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫번째 줄에 격자의 크기 N, M과 신이 좋아하는 문자열의 개수 K 가 주어진다.
|
||||
|
||||
다음에 N개의 줄에 걸쳐서 M개의 알파벳 소문자가 공백없이 주어진다. 여기서의 첫 번째 줄은 1행의 정보이며, N 번째 줄은 N행의 정보이다.
|
||||
|
||||
이어서 K개의 줄에 걸쳐서 신이 좋아하는 문자열이 주어진다. 모두 알파벳 소문자로 이루어져 있다.
|
||||
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
K개의 줄에 걸쳐서, 신이 좋아하는 문자열을 만들 수 있는 경우의 수를 순서대로 출력한다.
|
||||
|
||||
### 제한
|
||||
|
||||
- 3 ≤ N, M ≤ 10, N과 M은 자연수이다.
|
||||
- 1 ≤ K ≤ 1,000, K는 자연수이다.
|
||||
- 1 ≤ 신이 좋아하는 문자열의 길이 ≤ 5
|
||||
- 신이 좋아하는 문자열은 중복될 수도 있다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
신이 좋아하는 문자열 길이가 5 이하이고, N과 M, K의 수가 크지 않기 때문에 완전 탐색을 통해서 문제를 풀어볼 수 있을것 같았다.
|
||||
|
||||
우선 상, 하, 좌, 우 의 4방향뿐만 아니라 대각선으로도 가는 8방향으로 갈 수 있다고 나와 있다.
|
||||
심지어 왔던 방향을 돌아가서 문자열을 만들 수 있으니 왔던 방향을 체크해주지 않아도 된다.
|
||||
|
||||
때문에 큐를 이용해서 반복적으로 큐에 넣고, 큐에 들어간 문자가 신이 좋아하는 문자열과 같으면 카운트를 올려주는 방식으로 풀 수 있다고 생각했다.
|
||||
|
||||
클래스를 하나 정의해서 큐에 넣어주고 다시 꺼낼 때 현재의 위치와 이동 가능 방향으로 이동하여 문자열을 만들 수 있도록 정의 한다.
|
||||
```java
|
||||
// 큐에 들어가는 클래스
|
||||
class Words
|
||||
|
||||
int x, y, len;
|
||||
String str;
|
||||
```
|
||||
|
||||
문자열의 길이가 5이기 때문에 길이 5가 넘어가면 더 이상 큐에 넣지 않고, 다시 큐에서 다음 Words를 꺼내는 식으로 조건을 건다.
|
||||
|
||||
```
|
||||
a -> 길이가 5가 넘는지 체크 -> 신이 좋아하는 문자열이 있는지 체크, 있다면 카운팅 -> 8방향으로 보고 뒤에 문자열 추가 -> (큐에 넣기) -> 다시 차례가 와서 꺼내고 (반복)
|
||||
```
|
||||
위와 같은 반복을 통해 전부 다 돌려보도록해서 문제를 풀 수 있었다.
|
||||
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.LinkedList;
|
||||
import java.util.Queue;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class Hellhoseok_20166 {
|
||||
static int N, M, K;
|
||||
static char[][] cloud;
|
||||
static int[][] dir = { // 배열 상, 하, 좌, 우, 좌상, 우상, 좌하, 우하
|
||||
{-1, 1, 0, 0, -1, -1, 1, 1},
|
||||
{0, 0, -1, 1, -1, 1, -1, 1}
|
||||
};
|
||||
static int[] result;
|
||||
|
||||
public static void solution(int x, int y, String[] keywords) {
|
||||
Queue<Words> q = new LinkedList<>();
|
||||
q.add(new Words(x, y, 1, cloud[x][y]+""));
|
||||
|
||||
while(!q.isEmpty()) {
|
||||
Words tmpW = q.poll();
|
||||
|
||||
if(tmpW.len > 5) continue;
|
||||
|
||||
for(int j = 0; j < K; j++) {
|
||||
if(keywords[j].equals(tmpW.str)) {
|
||||
result[j]++;
|
||||
}
|
||||
}
|
||||
|
||||
for(int i = 0; i < 8; i++) {
|
||||
int nx = tmpW.x + dir[0][i];
|
||||
int ny = tmpW.y + dir[1][i];
|
||||
|
||||
if(nx == 0) nx = N;
|
||||
if(ny == 0) ny = M;
|
||||
if(nx > N) nx = 1;
|
||||
if(ny > M) ny = 1;
|
||||
|
||||
q.add(new Words(nx, ny, tmpW.len + 1, tmpW.str + cloud[nx][ny]));
|
||||
}
|
||||
}
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
M = Integer.parseInt(st.nextToken());
|
||||
K = Integer.parseInt(st.nextToken());
|
||||
|
||||
cloud = new char[N + 1][M + 1];
|
||||
result = new int[K];
|
||||
|
||||
String tmp = "";
|
||||
for(int i = 1; i <= N; i++) {
|
||||
tmp = br.readLine();
|
||||
for(int j = 1; j <= M; j++) {
|
||||
cloud[i][j] = tmp.charAt(j - 1);
|
||||
}
|
||||
}
|
||||
|
||||
String[] keywords = new String[K];
|
||||
for(int i = 0; i < K; i++) {
|
||||
tmp = br.readLine();
|
||||
keywords[i] = tmp;
|
||||
|
||||
}
|
||||
|
||||
for(int i = 1; i <= N; i++) {
|
||||
for(int j = 1; j <= M; j++) {
|
||||
solution(i, j, keywords);
|
||||
}
|
||||
}
|
||||
|
||||
StringBuilder sb = new StringBuilder();
|
||||
for(int i = 0; i < K; i++) {
|
||||
sb.append(result[i] + "\n");
|
||||
}
|
||||
|
||||
System.out.println(sb.toString());
|
||||
}
|
||||
}
|
||||
|
||||
class Words {
|
||||
int x;
|
||||
int y;
|
||||
int len;
|
||||
String str;
|
||||
public Words(int x, int y, int len, String str) {
|
||||
this.x = x;
|
||||
this.y = y;
|
||||
this.len = len;
|
||||
this.str = str;
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,231 @@
|
||||
---
|
||||
title: Baekjoon online judge. 15681.트리와 쿼리
|
||||
date: 2022-04-07
|
||||
tags: algorithmsolutions, 공부, 트리, 탐색
|
||||
excerpt: 15681.트리와 쿼리 - 백준온라인
|
||||
---
|
||||
# 15681.트리와 쿼리 - 백준온라인
|
||||
해당 문제는 트리와 탐색 문제로 개인적으로 부족하다고 많이 느끼는 부분이라 뒤에 있는 번호들도 추후 풀어볼 예정입니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/15681)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|1 초|128 MB|
|
||||
|
||||
간선에 가중치와 방향성이 없는 임의의 루트 있는 트리가 주어졌을 때, 아래의 쿼리에 답해보도록 하자.
|
||||
|
||||
- 정점 U를 루트로 하는 서브트리에 속한 정점의 수를 출력한다.
|
||||
|
||||
만약 이 문제를 해결하는 데에 어려움이 있다면, 하단의 힌트에 첨부한 문서를 참고하자.
|
||||
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
트리의 정점의 수 N과 루트의 번호 R, 쿼리의 수 Q가 주어진다. (2 ≤ N ≤ 105, 1 ≤ R ≤ N, 1 ≤ Q ≤ 105)
|
||||
|
||||
이어 N-1줄에 걸쳐, U V의 형태로 트리에 속한 간선의 정보가 주어진다. (1 ≤ U, V ≤ N, U ≠ V)
|
||||
|
||||
이는 U와 V를 양 끝점으로 하는 간선이 트리에 속함을 의미한다.
|
||||
|
||||
이어 Q줄에 걸쳐, 문제에 설명한 U가 하나씩 주어진다. (1 ≤ U ≤ N)
|
||||
|
||||
입력으로 주어지는 트리는 항상 올바른 트리임이 보장된다.
|
||||
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
Q줄에 걸쳐 각 쿼리의 답을 정수 하나로 출력한다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>문제 힌트 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||

|
||||
|
||||
그래프란, 정점들과 정점 둘을 잇는 간선들로 이루어진 집합을 의미한다.
|
||||
|
||||
위는 9개의 정점(원 모양)과, 10개의 간선(실선) 들로 이루어진 그래프이다. 각 원의 내부에 쓰여 있는 숫자는 편의상 정점에 매긴 번호를 의미한다.
|
||||
|
||||
붉은 간선은 차후 설명의 편의상 색칠해 둔 것으로, 우선은 다른 검은 간선과 동일한 것으로 간주하도록 하자.
|
||||
|
||||
간선은 항상 두 정점을 잇게 된다. 이제부터의 설명에서는, 각 정점을 번호로(1번 정점, 2번 정점.. ), 간선을 양 끝점의 정점의 번호로(1-3, 3-2… ) 표기하도록 하자.
|
||||
|
||||
그래프의 간선에는 가중치가 있을 수도 있다. 만일 특별한 언급이 없다면 모든 간선의 가중치가 1인 그래프로 간주할 수 있으며, 가중치가 존재한다면, 예를 들어 1-3 간선의 가중치가 3이라면, 1번 정점에서 3번 정점으로 가기 위해선 길이 3인 간선을 지나야 한다고 표현한다. 위의 그래프는 모든 간선의 길이가 1인 예시라고 보면 된다.
|
||||
|
||||
그래프의 간선에는 방향성이 있을 수도 있다. 예를 들어, 1번과 3번 정점 사이에 놓인 1-3 간선의 경우, 1->3 또는 3->1의 방향성을 가지는 것이 가능하다. 방향성 간선을 갖고 있는 그래프를 ‘유향 그래프’, 위의 그림처럼 방향성이 없는 간선만으로 이루어진 그래프를 ‘무향 그래프’ 라 한다. 간선의 방향성은 그래프에서 탐색을 진행할 때 결과를 달리할 수 있다. 예를 들어, 현재 위의 그래프에서 1번 정점에서 4번 정점까지 가면서, 간선을 최소한 거치는 경로는 1->3->4로, 총 2개의 간선을 거친다. 우리는 이것을 ‘1번 정점과 4번 정점의 최단 경로는 2다’ 라고 표현한다. 하지만 만약 3번 정점과 4번 정점 사이의 간선이 4->3의 방향성을 가진다면, 1번 정점에서 4번 정점으로 가는 최단 경로는 1->3->6->5->4 로, 총 4개의 간선을 지나야 한다. 즉, 최단 경로가 4가 된다.
|
||||
|
||||
그래프에서는 ‘사이클’ 을 정의할 수 있다. 무향 그래프에서의 사이클이란, 어떤 정점에서 출발해 시작점을 제외한 어떤 정점도, 어떤 간선도 두 번 이상 방문하지 않고 시작점으로 돌아올 수 있는 경로를 의미한다. 예를 들어, 위의 그림에서는 3-6-5-4-3 사이클과, 6-7-9 사이클이 존재한다. 1-3-1은 1-3 간선을 두 번 지났으므로 사이클이 될 수 없으며, 1-3-6-5-4-3은 시작점으로 돌아오지 않는 경로이므로 사이클이 아니다.
|
||||
|
||||
만일 그래프에 단 하나의 사이클도 없다면, 해당 그래프는 ‘트리’ 라고 부른다. 이는 그래프가 마치 하나의 정점에서 출발해 피어난 나무 모양과도 같음에 붙여진 이름으로, 예를 들어 위의 그림에서 빨간 간선 두 개를 제거한다면 위의 그래프는 트리가 된다. 예를 들어, 상단에 주어진 그래프에서 빨간 간선 두 개를 제거한 뒤 만들어진 트리의 모습은 아래와 같다.
|
||||
|
||||

|
||||
|
||||
일반적으로 그래프에서는 정점의 위치나 간선의 모양 등에 대한 조건은 전혀 고려하지 않으며, 오직 연결성만을 고려하므로, 간선의 집합이 변하지 않는다는 가정 하에 그래프를 얼마든지 다시 그릴 수가 있다. 위의 트리에서 5번 정점을 잡고 위로 들어올리는 예시를 생각해 보자. 아래쪽에 중력이 작용한다고 생각하고 5번 정점을 위쪽으로 들어올리게 되면 트리의 모양은 아래와 같이 변할 것이다.
|
||||
|
||||

|
||||
|
||||
간선의 집합에 변함이 없는 한, 그래프는 얼마든지 원하는 대로 다시 그릴 수가 있다. 예를 들어, 위의 트리를 거울에 비추어 좌우를 바꿀 경우에도 동일한 트리가 된다.
|
||||
|
||||
트리에는 루트(root)가 있을 수도 없을 수도 있지만, 편의를 위해서라면 아무 정점이나 루트로 선택할 수 있다. 5번 정점을 루트로 하였다고 생각한 뒤 위의 트리를 다시 보도록 하자.
|
||||
|
||||
트리는 항상 루트를 기준으로 다시 그릴 수 있기 때문에, 루트가 고정되지 않는 한 어떤 정점이 ‘위에’ 있는지 판정할 수는 없다. 하지만 루트가 고정된다면, 우리는 정점 간에 ‘부모’ 와 ‘자식’ 의 관계를 정의할 수가 있다. 예를 들어, 위의 트리에서는 4번 정점의 부모는 5번 정점이며, 3번 정점은 4번 정점의 자식이 된다. 5번 정점의 부모는 없으며, 4, 6번 정점을 두 자식으로 갖게 될 것이다.
|
||||
|
||||
트리에는 몇 가지 중요한 성질이 있는데, 그 중 두 가지만 추려보자면 아래와 같다.
|
||||
|
||||
- 임의의 두 정점 U와 V에 대해, U에서 V로 가는 최단경로는 유일하다.
|
||||
- 아무 정점이나 잡고 부모와의 연결을 끊었을 때, 해당 정점과 그 자식들, 그 자식들의 자식들… 로 이루어진 부분그래프는 트리가 된다.
|
||||
|
||||
둘 모두 직관적이며 자명한 사실이므로 증명은 생략한다. 두 번째 성질에서, 끊어진 부분그래프로 만들어진 트리를 ‘서브트리’ 라고 부른다.
|
||||
|
||||
만약 트리에 대한 문제 하나가 출제되었다고 가정해보자. 입력이 위처럼 루트와 그 자식들로 이루어진다면 좋지만, 루트가 없는 일반 트리의 형태(두 번째 그림)의 형태로 입력이 주어질 수도 있다. 예를 들어, 정점의 개수와 간선의 목록만이 주어진다면, 어떻게 트리를 구성할 수 있을까?
|
||||
|
||||
예를 들어, 위의 트리에 대해 정점의 개수와 간선의 목록이 아래와 같이 입력된다고 하자.
|
||||
|
||||
```
|
||||
9
|
||||
1 3
|
||||
4 3
|
||||
5 4
|
||||
5 6
|
||||
6 7
|
||||
2 3
|
||||
9 6
|
||||
6 8
|
||||
```
|
||||
|
||||
첫 줄의 9는 정점의 개수이며, 나머지 8쌍의 두 정수는 간선의 양 끝점 번호를 의미한다. 트리에서의 간선의 개수는 항상 정점의 수 - 1이라는 것은 익히 알려진 사실이며, 증명 또한 어렵지 않으므로 설명을 생략한다.
|
||||
|
||||
위와 같은 데이터를 트리로 구성하기 위해서는, 우선 루트 하나를 임의로 정의하는 것이 편하다. 5번 정점을 루트로 정해보도록 하자.
|
||||
|
||||
트리에는 부모와 자식 관계가 있으므로, 각 정점별로 부모가 누구인지, 자식들의 목록은 어떻게 되는지를 저장해 두면 요긴하게 쓰일 것이다. 이를 아래와 같이 구현할 수 있다.
|
||||
|
||||
```python
|
||||
def makeTree(currentNode, parent) :
|
||||
for(Node in connect[currentNode]) :
|
||||
if Node != parent:
|
||||
add Node to currentNode’s child
|
||||
set Node’s parent to currentNode
|
||||
makeTree(Node, currentNode)
|
||||
```
|
||||
currentNode는 현재 탐색 중인 정점이며, parent는 해당 정점의 부모 정점이다.
|
||||
|
||||
트리에서는 (눈치챘을 수도 있지만) 어떤 정점의 부모는 하나이거나 없다. 따라서, 어떤 정점에 대해 연결된 모든 정점은 최대 한 개의 정점을 제외하면 모두 해당 정점의 자식들이 될 것이다. 이에 따라, 부모 정점의 정보를 가져가면서, 부모 정점이 아니면서 자신과 연결되어 있는 모든 정점을 자신의 자식으로, 자신의 자식이 될 정점들의 부모 정점을 자신으로 연결한 뒤 재귀적으로 자식 정점들에게 트리 구성을 요청하는 형태의 함수이다.
|
||||
|
||||
위와 같이 정의한 뒤엔, 메인 함수에서 한 차례 makeTree(5, -1) 을 호출할 경우 5번 정점을 루트로 하는 트리를 구성할 수 있다. -1은 부모가 없음을 의미한다.
|
||||
|
||||
그렇다면, 일반적인 형태의 트리에서 루트가 주어진 뒤 여러 질의가 주어지는 상황을 생각해 보자. 예를 들어, 5번 정점을 루트로 하는 트리에 대해, ‘정점 U를 루트로 하는 서브트리의 정점의 수는 얼마인가?’ 라는 질의가 다수 주어진다고 해 보자. U를 루트로 하는 서브트리란, 위에도 언급하였지만 정점 U와 그 부모의 연결을 끊고 정점 U를 기준으로 그 자식들, 자식들의 자식들… 로 만든 트리를 말한다. 예를 들어, 5번 정점이 루트일 때 4번 정점을 루트로 하는 서브트리에서의 정점의 수는 4개이며, 8번 정점을 루트로 하는 서브트리에서의 정점의 수는 1개가 된다.
|
||||
|
||||
물론 직접 연결을 끊은 뒤 다시 정점의 수를 세는 방법도 가능하겠지만, 트리의 정점 수가 많고, 질의 또한 많다면 프로그램이 제한시간 내에 수행될 수 없을 확률이 높다. 아마 미리 모든 정점을 각각 루트로 하는 서브트리에서의 정점의 수를 빠르게 구해 둘 방법이 있다면 좋을 것이다.
|
||||
|
||||
이를 구현하기 위해, 트리를 구성하던 코드의 동작 과정을 살펴보도록 하자. 루트에서 출발하여, 자식 정점들에 대해 한 번씩 트리 구성을 요청하게 된다. 여기에서 알 수 있는 사실은, 자식 정점들에 대한 makeTree가 호출된 뒤엔, 해당 자식 정점을 서브트리로 하는 트리가 구성이 완료된다는 것이다. 이와 같은 원리로 모든 정점에 대해 해당 정점을 루트로 하는 서브트리에 속한 정점의 수를 계산하는 함수를 만들어보도록 하자.
|
||||
|
||||
```python
|
||||
def countSubtreeNodes(currentNode) :
|
||||
size[currentNode] = 1 // 자신도 자신을 루트로 하는 서브트리에 포함되므로 0이 아닌 1에서 시작한다.
|
||||
for Node in currentNode’s child:
|
||||
countSubtreeNode(Node)
|
||||
size[currentNode] += size[Node]
|
||||
```
|
||||
|
||||
자식 정점들에 대해 모두 서브트리에 속한 정점의 수를 계산하게 만든 뒤 각각의 정점 수를 더해 자신을 루트로 하는 서브트리에 속한 정점의 수를 만들게 된다. 이제 메인 함수 내에서 makeTree(5, -1)과 countSubtreeNodes(5) 를 차례대로 한 번씩 호출할 경우, 5번을 루트로 하는 트리에서 모든 정점에 대해 각 정점을 루트로 하는 서브트리에 속한 정점의 수를 계산해둘 수가 있다. 이를 이용하면, 모든 질의 U에 대해 size[U] 를 출력하기만 하면 되므로, 정점이 10만 개, 질의가 10만 개인 데이터에서도 충분히 빠른 시간 내에 모든 질의를 처리할 수가 있게 될 것이다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
이 문제는 각 루트마다 그래프를 각 독립적으로 보고, 하위 노드들의 개수를 따로 표기하여 최초 탐색 한 번만으로 각 노드의 간선의 개수를 구할 수 있었다.
|
||||
|
||||
`ArrayList<Integer>`를 가진 배열을 통해 각 노드들을 추가하며 무방향, 무가중치 그래프 구조를 만들 수 있다.
|
||||
|
||||
```
|
||||
[0][1][2][3][4][5] ...
|
||||
1 3 0 5 4
|
||||
0
|
||||
```
|
||||
|
||||
그리고 루트 R이 정해졌으므로 이것을 들어올린다고 생각하면 트리가 된다.
|
||||
이 때, 이진 트리가 아님에는 주의하자.
|
||||
|
||||
매 쿼리마다 독립된 트리를 돌면 시간초과가 날 수 있다는 것을 알 수 있다.
|
||||
( 2 ≤ N ≤ 10^5 , 1 ≤ R ≤ N, 1 ≤ Q ≤ 10^5 )
|
||||
때문에 나도 처음에 생각없이 매 번 돌면서 확인하도록 만들어서 시간 초과가 났었다.
|
||||
|
||||
List 배열과 동일하게 integer 배열을 만들어서 각 하위 노드들의 개수를 저장해둠으로써 이를 해결하였다.
|
||||
|
||||
이전에 방문한 노드는 재 방문하지 않도록하여 하위 노드의 개수를 상위 노드의 개수에 추가해주면 각 노드의 하위 노드 개수를 파악할 수 있다. 즉, 덕분에 매 쿼리마다 트리를 탐색할 필요없이 배열의 쿼리 인덱스만 호출하면 하위 노드의 개수 값을 알 수 있다.
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.ArrayList;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class TreenQuery_15681 {
|
||||
static int N, R, Q;
|
||||
static int[] arrq, cnt;
|
||||
static ArrayList<Integer>[] tree;
|
||||
|
||||
public static void search(int x, int prevNode) {
|
||||
cnt[x] = 1; // 현 루트 또한 간선의 개수로 포함
|
||||
|
||||
for(int a : tree[x]) {
|
||||
if(a == prevNode) continue; // 이전에 방문한 노드는 넘어간다.
|
||||
search(a, x);
|
||||
cnt[x] += cnt[a]; // 하위 노드의 간선 갯수도 더해준다.
|
||||
}
|
||||
}
|
||||
|
||||
public static void solution() {
|
||||
search(R, -1);
|
||||
|
||||
StringBuilder sb = new StringBuilder();
|
||||
for(int i : arrq) {
|
||||
sb.append(cnt[i] + "\n");
|
||||
}
|
||||
System.out.println(sb.toString());
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
R = Integer.parseInt(st.nextToken());
|
||||
Q = Integer.parseInt(st.nextToken());
|
||||
|
||||
cnt = new int[N + 1];
|
||||
arrq = new int[Q];
|
||||
|
||||
tree = new ArrayList[N + 1];
|
||||
for(int i = 1; i <= N; i++) tree[i] = new ArrayList<>();
|
||||
|
||||
for(int i = 1; i < N; i++) { // 가중치 없는 무방향 그래프
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
int U = Integer.parseInt(st.nextToken());
|
||||
int V = Integer.parseInt(st.nextToken());
|
||||
tree[U].add(V);
|
||||
tree[V].add(U);
|
||||
}
|
||||
|
||||
for(int i = 0; i < Q; i++) {
|
||||
arrq[i] = Integer.parseInt(br.readLine());
|
||||
}
|
||||
solution();
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,117 @@
|
||||
---
|
||||
title: Baekjoon online judge. 1174.줄어드는 수
|
||||
date: 2022-04-08
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 1174.줄어드는 수 - 백준온라인
|
||||
---
|
||||
# 1174.줄어드는 수 - 백준온라인
|
||||
해당 문제는 백트래킹 방식으로 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/1174)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|2 초|128 MB|
|
||||
|
||||
음이 아닌 정수를 십진법으로 표기했을 때, 왼쪽에서부터 자리수가 감소할 때, 그 수를 줄어드는 수라고 한다. 예를 들어, 321와 950은 줄어드는 수이고, 322와 958은 아니다.
|
||||
|
||||
N번째로 작은 줄어드는 수를 출력하는 프로그램을 작성하시오. 만약 그러한 수가 없을 때는 -1을 출력한다. 가장 작은 줄어드는 수가 1번째 작은 줄어드는 수이다.
|
||||
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
N이 주어진다. N은 1,000,000보다 작거나 같은 자연수이다.
|
||||
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
첫째 줄에 N번째 작은 줄어드는 수를 출력한다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
이 문제는 백트래킹을 활용하여 풀어보았다.
|
||||
|
||||
오늘은 포스트를 작성 할 수 없어서 추후 업데이트 하겠다.
|
||||
|
||||
### 백트래킹 방식
|
||||
|
||||
|
||||
### 비트마스킹 방식
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
또한 비트마스킹으로도 풀이가 가능하기 때문에 함께 소스코드를 작성해 본다.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.ArrayList;
|
||||
import java.util.Collections;
|
||||
|
||||
public class Decreasenum_1174 {
|
||||
public static int[] num = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
|
||||
public static ArrayList<Long> al = new ArrayList<Long>();
|
||||
public static void solutionByBitmask(int n) {
|
||||
ArrayList<Long> list = new ArrayList<Long>();
|
||||
// 2^10의 모든 경우의수를 만든다.
|
||||
for(int i = 1; i < (1<<10); i++) {
|
||||
long sum = 0;
|
||||
// 10 자리만큼 탐색
|
||||
for(int j = 0; j < 10; j++) {
|
||||
// i가 0^2, 1^2, 2^2, .. , j^2 보다 크다면
|
||||
// i에 해당하는 비트가 각각 어느위치에 비트를 가지고 있는지 체크
|
||||
// if문을 만족한다면 해당 자릿수가 만족한다는 것이므로 sum*10 + num[j]를 추가.
|
||||
if( (i & (1 << j)) > 0 ) {
|
||||
sum = sum * 10 + num[j];
|
||||
}
|
||||
}
|
||||
list.add(sum);
|
||||
}
|
||||
|
||||
Collections.sort(list);
|
||||
if(n > list.size()) {
|
||||
System.out.println("-1");
|
||||
return;
|
||||
}
|
||||
System.out.println(list.get(n - 1));
|
||||
}
|
||||
|
||||
public static void solutionByRecursive(long sum, int idx) {
|
||||
if(!al.contains(sum)) {
|
||||
al.add(sum);
|
||||
}
|
||||
if(idx >= 10) {
|
||||
return;
|
||||
}
|
||||
solutionByRecursive( (sum * 10) + num[idx], idx + 1);
|
||||
solutionByRecursive(sum, idx + 1);
|
||||
}
|
||||
public static void main(String[] args) throws NumberFormatException, IOException {
|
||||
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
|
||||
int N = Integer.parseInt(reader.readLine());
|
||||
|
||||
int result = 0;
|
||||
if(result == 0) {
|
||||
solutionByBitmask(N);
|
||||
} else {
|
||||
solutionByRecursive(0, 0);
|
||||
al.sort(null);
|
||||
if(N > 1023)
|
||||
System.out.println("-1");
|
||||
else
|
||||
System.out.println(al.get(N - 1));
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,219 @@
|
||||
---
|
||||
title: Samsung sorftware Algorithms. 21610.마법사 상어와 비바라기
|
||||
date: 2022-04-12
|
||||
tags: algorithmsolutions, 공부, 탐색
|
||||
excerpt: 21610.마법사 상어와 비바라기 - 삼성기출문제 (from.백준알고리즘)
|
||||
---
|
||||
# 21610.마법사 상어와 비바라기 - 삼성기출문제 (from.백준알고리즘)
|
||||
|
||||
해당 문제는 시뮬레이션 문제로 단계별로 수행하는 함수를 이용하여 풀 수 있는 문제입니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/21610)
|
||||
|
||||
---
|
||||
|
||||
## 1. 문제
|
||||
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
### 21610\. 마법사 상어와 비바라기
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|1 초 (추가 시간 없음)|1024 MB|
|
||||
|
||||
마법사 상어는 파이어볼, 토네이도, 파이어스톰, 물복사버그 마법을 할 수 있다. 오늘 새로 배운 마법은 비바라기이다. 비바라기를 시전하면 하늘에 비구름을 만들 수 있다. 오늘은 비바라기를 크기가 N×N인 격자에서 연습하려고 한다. 격자의 각 칸에는 바구니가 하나 있고, 바구니는 칸 전체를 차지한다. 바구니에 저장할 수 있는 물의 양에는 제한이 없다. (r, c)는 격자의 r행 c열에 있는 바구니를 의미하고, A[r][c]는 (r, c)에 있는 바구니에 저장되어 있는 물의 양을 의미한다.
|
||||
|
||||
격자의 가장 왼쪽 윗 칸은 (1, 1)이고, 가장 오른쪽 아랫 칸은 (N, N)이다. 마법사 상어는 연습을 위해 1번 행과 N번 행을 연결했고, 1번 열과 N번 열도 연결했다. 즉, N번 행의 아래에는 1번 행이, 1번 행의 위에는 N번 행이 있고, 1번 열의 왼쪽에는 N번 열이, N번 열의 오른쪽에는 1번 열이 있다.
|
||||
|
||||
비바라기를 시전하면 (N, 1), (N, 2), (N-1, 1), (N-1, 2)에 비구름이 생긴다. 구름은 칸 전체를 차지한다. 이제 구름에 이동을 M번 명령하려고 한다. i번째 이동 명령은 방향 d<sub>i</sub>과 거리 s<sub>i</sub>로 이루어져 있다. 방향은 총 8개의 방향이 있으며, 8개의 정수로 표현한다. 1부터 순서대로 ←, ↖, ↑, ↗, →, ↘, ↓, ↙ 이다. 이동을 명령하면 다음이 순서대로 진행된다.
|
||||
|
||||
1. 모든 구름이 d<sub>i</sub> 방향으로 s<sub>i</sub>칸 이동한다.
|
||||
2. 각 구름에서 비가 내려 구름이 있는 칸의 바구니에 저장된 물의 양이 1 증가한다.
|
||||
3. 구름이 모두 사라진다.
|
||||
4. 2에서 물이 증가한 칸 (r, c)에 물복사버그 마법을 시전한다. 물복사버그 마법을 사용하면, 대각선 방향으로 거리가 1인 칸에 물이 있는 바구니의 수만큼 (r, c)에 있는 바구니의 물이 양이 증가한다.
|
||||
- 이때는 이동과 다르게 경계를 넘어가는 칸은 대각선 방향으로 거리가 1인 칸이 아니다.
|
||||
- 예를 들어, (N, 2)에서 인접한 대각선 칸은 (N-1, 1), (N-1, 3)이고, (N, N)에서 인접한 대각선 칸은 (N-1, N-1)뿐이다.
|
||||
5. 바구니에 저장된 물의 양이 2 이상인 모든 칸에 구름이 생기고, 물의 양이 2 줄어든다. 이때 구름이 생기는 칸은 3에서 구름이 사라진 칸이 아니어야 한다.
|
||||
|
||||
M번의 이동이 모두 끝난 후 바구니에 들어있는 물의 양의 합을 구해보자.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫째 줄에 N, M이 주어진다.
|
||||
|
||||
둘째 줄부터 N개의 줄에는 N개의 정수가 주어진다. r번째 행의 c번째 정수는 A[r][c]를 의미한다.
|
||||
|
||||
다음 M개의 줄에는 이동의 정보 d<sub>i</sub>, s<sub>i</sub>가 순서대로 한 줄에 하나씩 주어진다.
|
||||
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
첫째 줄에 M번의 이동이 모두 끝난 후 바구니에 들어있는 물의 양의 합을 출력한다.
|
||||
|
||||
### 제한
|
||||
|
||||
- 2 ≤ N ≤ 50
|
||||
- 1 ≤ M ≤ 100
|
||||
- 0 ≤ A[r][c] ≤ 100
|
||||
- 1 ≤ d<sub>i</sub> ≤ 8
|
||||
- 1 ≤ s<sub>i</sub> ≤ 50
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
이 문제는 시뮬레이션 문제로, 나와있는 조건을 그대로 구현하기만 하면 된다.
|
||||
|
||||
먼저 구름의 위치를 가지고 있는 Queue를 만들어서 현재 위치 값을 가지고 있는 Cloud 객체를 만들고 큐에 넣는다.
|
||||
|
||||
그리고 이 구름을 이동시키는데, 여기서 중요한것은 양 옆에서 넘어갈 수 있도록 만들었다는것이다. 1에서 줄어들면 N으로 가는 방식을 2중, 3중 더 넘더라도 위치를 정확하게 찍어줘야 한다는것이다.
|
||||
때문에 이동하는 s<sub>i</sub>를 N의 나머지 부분으로 바꾸어서 이동하게 했다. 그리고 이동한 구름의 위치에 비가 내려 양동이의 양을 1 증가시킨다.
|
||||
이 때 중요한것은 이렇게 증가된 곳을 체크해주고 이후에 새로 구름이 생성될 때, 비가 내린 곳은 생성되지 않도록 한다.
|
||||
|
||||
그리고 물 복사 마법이라고 (r,c) 부분의 대각선 4부분을 체크해서 물이 있으면 그 물의 수만큼 (r,c)에 위치한 양동이의 물이 증가된다.
|
||||
이 액트는 격자의 범위를 넘어가면 카운트에서 제외시킨다.
|
||||
이 때 주의해야 할 부분이 기존 격자에서 체크해서 증가시키면 1이었던 양동이가 2가되어서 다른 양동이에 영향을 줄 수 있기 때문에 격자를 복사해서 해당 위치의 양동이만 증가될 수 있도록 해야 한다.
|
||||
|
||||
이것을 코드로 표현하겠습니다.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.LinkedList;
|
||||
import java.util.Queue;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class MagicianShark_Windblows_21610 {
|
||||
static int N, M;
|
||||
static int[][] map;
|
||||
static boolean[][] rain;
|
||||
static int[][] dir = { // 0은 빈칸, 좌, 좌상, 상, 우상, 우, 우하, 하, 좌하
|
||||
{0, 0, -1, -1, -1, 0, 1, 1, 1},
|
||||
{0, -1, -1, 0, 1, 1, 1, 0, -1}
|
||||
};
|
||||
static int[][] checkBucket = {
|
||||
{-1, -1, 1, 1},
|
||||
{-1, 1, -1, 1}
|
||||
};
|
||||
static int[][] command;
|
||||
static Queue<Cloud> cloud;
|
||||
public static void moveCloudnRain(int d, int s) {
|
||||
int size = cloud.size();
|
||||
|
||||
rain = new boolean[N + 1][N + 1];
|
||||
while(size > 0) {
|
||||
Cloud tmp = cloud.poll();
|
||||
int nr = tmp.r + (dir[0][d] * (s % N));
|
||||
int nc = tmp.c + (dir[1][d] * (s % N));
|
||||
|
||||
// 이어붙인 공간 넘어가기
|
||||
if(nr <= 0) nr = N + nr;
|
||||
if(nc <= 0) nc = N + nc;
|
||||
if(nr > N) nr = nr - N;
|
||||
if(nc > N) nc = nc - N;
|
||||
|
||||
cloud.add(new Cloud(nr, nc));
|
||||
map[nr][nc]++;
|
||||
rain[nr][nc] = true;
|
||||
size--;
|
||||
}
|
||||
}
|
||||
public static void copywater() {
|
||||
int[][] copyMap = new int[N + 1][N + 1];
|
||||
for(int i = 1; i <= N; i++) {
|
||||
for(int j = 1; j <= N; j++) {
|
||||
copyMap[i][j] = map[i][j];
|
||||
}
|
||||
}
|
||||
|
||||
while(!cloud.isEmpty()) {
|
||||
Cloud tmp = cloud.poll();
|
||||
rain[tmp.r][tmp.c] = true;
|
||||
|
||||
// 물 복사 마법
|
||||
int cnt = 0;
|
||||
for(int i = 0; i < 4; i++) {
|
||||
int nr = tmp.r + checkBucket[0][i];
|
||||
int nc = tmp.c + checkBucket[1][i];
|
||||
if(nr <= 0 || nc <= 0 || nr > N || nc > N) continue;
|
||||
if(copyMap[nr][nc] > 0) cnt++;
|
||||
}
|
||||
map[tmp.r][tmp.c] += cnt;
|
||||
}
|
||||
}
|
||||
public static void makeCloud() {
|
||||
for(int i = 1; i <= N; i++) {
|
||||
for(int j = 1; j <= N; j++) {
|
||||
if(!rain[i][j] && map[i][j] >= 2) {
|
||||
cloud.add(new Cloud(i, j));
|
||||
map[i][j] -= 2;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
public static void solution() {
|
||||
for(int i = 0; i < M; i++) {
|
||||
moveCloudnRain(command[i][0], command[i][1]);
|
||||
copywater();
|
||||
makeCloud();
|
||||
}
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
M = Integer.parseInt(st.nextToken());
|
||||
|
||||
map = new int[N + 1][N + 1];
|
||||
command = new int[M][2];
|
||||
|
||||
cloud = new LinkedList<Cloud>();
|
||||
|
||||
cloud.add(new Cloud(N, 1));
|
||||
cloud.add(new Cloud(N, 2));
|
||||
cloud.add(new Cloud(N - 1, 1));
|
||||
cloud.add(new Cloud(N - 1, 2));
|
||||
|
||||
for(int i = 1; i <= N; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
for(int j = 1; j <= N; j++) {
|
||||
map[i][j] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
}
|
||||
|
||||
for(int i = 0; i < M; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
command[i][0] = Integer.parseInt(st.nextToken());
|
||||
command[i][1] = Integer.parseInt(st.nextToken());
|
||||
}
|
||||
|
||||
solution();
|
||||
|
||||
int result = 0;
|
||||
for(int i = 1; i <= N; i++) {
|
||||
for(int j = 1; j <= N; j++) {
|
||||
result += map[i][j];
|
||||
}
|
||||
}
|
||||
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
|
||||
class Cloud {
|
||||
int r, c; // 위치 정보 초기 (N, 1), (N, 2), (N-1, 1), (N-1, 2)
|
||||
public Cloud(int r, int c) {
|
||||
this.r = r;
|
||||
this.c = c;
|
||||
}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,162 @@
|
||||
---
|
||||
title: Baekjoon online judge. 20182.골목 대장 호석 - 효율성1
|
||||
date: 2022-04-13
|
||||
tags: algorithmsolutions, 공부
|
||||
excerpt: 20182.골목 대장 호석 - 효율성1 - 백준온라인
|
||||
---
|
||||
# 20182.골목 대장 호석 - 효율성1 - 백준온라인
|
||||
해당 문제는 다익스트라 방식으로 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://www.acmicpc.net/problem/20182)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||
|시간 제한|메모리 제한|
|
||||
|------|---|
|
||||
|3 초|512 MB|
|
||||
|
||||
소싯적 호석이는 골목 대장의 삶을 살았다. 호석이가 살던 마을은 N 개의 교차로와 M 개의 골목이 있었다. 교차로의 번호는 1번부터 N 번까지로 표현한다. 골목은 서로 다른 두 교차로를 양방향으로 이어주며 임의의 두 교차로를 잇는 골목은 최대 한 개만 존재한다. 분신술을 쓰는 호석이는 모든 골목에 자신의 분신을 두었고, 골목마다 통과하는 사람에게 수금할 것이다. 수금하는 요금은 골목마다 다를 수 있다.
|
||||
|
||||
당신은 A 번 교차로에서 B 번 교차로까지 C 원을 가지고 가려고 한다. 호석이의 횡포를 보며 짜증은 나지만, 분신술을 이겨낼 방법이 없어서 돈을 내고 가려고 한다. 하지만 이왕 지나갈 거면, 최소한의 수치심을 받고 싶다. 당신이 받는 수치심은 경로 상에서 가장 많이 낸 돈에 비례하기 때문에, 결국 갈 수 있는 다양한 방법들 중에서 최소한의 수치심을 받으려고 한다. 즉, 한 골목에서 내야 하는 최대 요금을 최소화하는 것이다.
|
||||
|
||||

|
||||
|
||||
예를 들어, 위의 그림과 같이 5개의 교차로와 5개의 골목이 있으며, 당신이 1번 교차로에서 3번 교차로로 가고 싶은 상황이라고 하자. 만약 10원을 들고 출발한다면 2가지 경로로 갈 수 있다. 1번 -> 2번 -> 3번 교차로로 이동하게 되면 총 10원이 필요하고 이 과정에서 최대 수금액을 5원이었고, 1번 -> 4번 -> 5번 -> 3번 교차로로 이동하게 되면 총 8원이 필요하며 최대 수금액은 6원이 된다. 최소한의 수치심을 얻는 경로는 최대 수금액이 5인 경로이다. 하지만 만약 8원밖에 없다면, 전자의 경로는 갈 수 없기 때문에 최대 수금액이 6원인 경로로 가야 하는 것이 최선이다.
|
||||
|
||||
당신은 앞선 예제를 통해서, 수치심을 줄이고 싶을 수록 같거나 더 많은 돈이 필요하고, 수치심을 더 받는 것을 감수하면 같거나 더 적은 돈이 필요하게 된다는 것을 알게 되었다. 마을의 지도와 골목마다 존재하는 호석이가 수금하는 금액을 안다면, 당신이 한 골목에서 내야하는 최대 요금의 최솟값을 계산하자. 만약 지금 가진 돈으로는 절대로 목표 지점을 갈 수 없다면 -1 을 출력하라.
|
||||
|
||||
### 입력(Input)
|
||||
|
||||
첫 줄에 교차로 개수 N, 골목 개수 M, 시작 교차로 번호 A, 도착 교차로 번호 B, 가진 돈 C 가 공백으로 구분되어 주어진다. 이어서 M 개의 줄에 걸쳐서 각 골목이 잇는 교차로 2개의 번호와, 골목의 수금액이 공백으로 구분되어 주어진다. 같은 교차로를 잇는 골목은 최대 한 번만 주어지며, 골목은 양방향이다.
|
||||
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
호석이가 지키고 있는 골목들을 통해서 시작 교차로에서 도착 교차로까지 C 원 이하로 가는 경로들 중에, 지나는 골목의 요금의 최댓값의 최솟값을 출력하라. 만약 갈 수 없다면 -1을 출력한다.
|
||||
|
||||
### 제한
|
||||
|
||||
- 1 ≤ N ≤ 100,000
|
||||
- 1 ≤ M ≤ 500,000
|
||||
- 1 ≤ C ≤ 2,000,000
|
||||
- 1 ≤ 골목 별 수금액 ≤ 20
|
||||
- 1 ≤ A, B ≤ N, A ≠ B
|
||||
- 골목이 잇는 교차로의 번호는 서로 다르다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
이 문제는 다익스트라를 활용하여 풀어보았다.
|
||||
|
||||
오늘은 포스트를 작성 할 수 없어서 추후 업데이트 하겠다.
|
||||
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.ArrayList;
|
||||
import java.util.Arrays;
|
||||
import java.util.Comparator;
|
||||
import java.util.List;
|
||||
import java.util.PriorityQueue;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class AlleyBossHoseok_20182 {
|
||||
static int N, M, A, B, C;
|
||||
static List<List<Pay>> map;
|
||||
static int min[];
|
||||
static int solution() {
|
||||
int answer = 0;
|
||||
|
||||
PriorityQueue<Pay> pq = new PriorityQueue<>(new Comparator<Pay>(){
|
||||
@Override
|
||||
public int compare(Pay o1, Pay o2) {
|
||||
if(o1.p == o2.p) return o1.n - o2.n;
|
||||
else return o1.p - o2.p;
|
||||
}
|
||||
});
|
||||
|
||||
boolean[] visited = new boolean[N + 1];
|
||||
|
||||
pq.add(new Pay(A, 0, Integer.MIN_VALUE));
|
||||
|
||||
while(!pq.isEmpty()) {
|
||||
Pay cur = pq.poll();
|
||||
if(visited[cur.n] || cur.n == B) continue;
|
||||
|
||||
visited[cur.n] = true;
|
||||
|
||||
for(Pay next : map.get(cur.n)) {
|
||||
int totalPay = cur.p + next.n;
|
||||
if(visited[next.n] || totalPay > C) continue;
|
||||
|
||||
int curMax = cur.max;
|
||||
if(curMax < next.p) {
|
||||
curMax = next.p;
|
||||
}
|
||||
if(min[next.n] > curMax) min[next.n] = curMax;
|
||||
pq.add(new Pay(next.n, totalPay, curMax));
|
||||
}
|
||||
}
|
||||
|
||||
answer = min[B] != Integer.MAX_VALUE ? min[B] : -1;
|
||||
return answer;
|
||||
}
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
N = Integer.parseInt(st.nextToken());
|
||||
M = Integer.parseInt(st.nextToken());
|
||||
A = Integer.parseInt(st.nextToken());
|
||||
B = Integer.parseInt(st.nextToken());
|
||||
C = Integer.parseInt(st.nextToken());
|
||||
|
||||
map = new ArrayList<>();
|
||||
min = new int[N + 1];
|
||||
Arrays.fill(min, Integer.MIN_VALUE);
|
||||
|
||||
for(int i = 0; i <= N; i++) map.add(new ArrayList<>());
|
||||
for(int i = 0; i < M; i++) {
|
||||
if(!st.hasMoreTokens()) st = new StringTokenizer(br.readLine());
|
||||
int one = Integer.parseInt(st.nextToken());
|
||||
int two = Integer.parseInt(st.nextToken());
|
||||
int cost = Integer.parseInt(st.nextToken());
|
||||
|
||||
map.get(one).add(new Pay(two, cost));
|
||||
map.get(two).add(new Pay(one, cost));
|
||||
}
|
||||
|
||||
System.out.println(solution());
|
||||
}
|
||||
}
|
||||
|
||||
class Pay {
|
||||
int n;
|
||||
int p;
|
||||
int max;
|
||||
|
||||
public Pay(int n, int p) {
|
||||
this.n = n;
|
||||
this.p = p;
|
||||
}
|
||||
|
||||
public Pay(int n, int p, int max) {
|
||||
this.n = n;
|
||||
this.p = p;
|
||||
this.max = max;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
@@ -0,0 +1,163 @@
|
||||
---
|
||||
title: Programmers. 1835.단체사진 찍기
|
||||
date: 2022-04-18
|
||||
tags: algorithmsolutions, 공부, 순열
|
||||
excerpt: 1835.단체사진 찍기 - 프로그래머스
|
||||
---
|
||||
# 1835.단체사진 찍기 - 프로그래머스
|
||||
해당 문제는 순열로 카카오 친구들의 순서를 나열하고 조건을 걸어 풀어보았습니다.
|
||||
|
||||
링크 :
|
||||
[](https://programmers.co.kr/learn/courses/30/lessons/1835)
|
||||
|
||||
---
|
||||
## 1. 문제
|
||||
<details>
|
||||
<summary>문제 보기</summary>
|
||||
<div markdown="1">
|
||||
|
||||

|
||||
|
||||
가을을 맞아 카카오프렌즈는 단체로 소풍을 떠났다. 즐거운 시간을 보내고 마지막에 단체사진을 찍기 위해 카메라 앞에 일렬로 나란히 섰다. 그런데 각자가 원하는 배치가 모두 달라 어떤 순서로 설지 정하는데 시간이 오래 걸렸다. 네오는 프로도와 나란히 서기를 원했고, 튜브가 뿜은 불을 맞은 적이 있던 라이언은 튜브에게서 적어도 세 칸 이상 떨어져서 서기를 원했다. 사진을 찍고 나서 돌아오는 길에, 무지는 모두가 원하는 조건을 만족하면서도 다르게 서는 방법이 있지 않았을까 생각해보게 되었다. 각 프렌즈가 원하는 조건을 입력으로 받았을 때 모든 조건을 만족할 수 있도록 서는 경우의 수를 계산하는 프로그램을 작성해보자.
|
||||
|
||||
|
||||
### 입력형식
|
||||
|
||||
입력은 조건의 개수를 나타내는 정수 n과 n개의 원소로 구성된 문자열 배열 data로 주어진다. data의 원소는 각 프렌즈가 원하는 조건이 N~F=0과 같은 형태의 문자열로 구성되어 있다. 제한조건은 아래와 같다.
|
||||
|
||||
- 1 <= n <= 100
|
||||
- data의 원소는 다섯 글자로 구성된 문자열이다. 각 원소의 조건은 다음과 같다.
|
||||
- 첫 번째 글자와 세 번째 글자는 다음 8개 중 하나이다. {A, C, F, J, M, N, R, T} 각각 어피치, 콘, 프로도, 제이지, 무지, 네오, 라이언, 튜브를 의미한다. 첫 번째 글자는 조건을 제시한 프렌즈, 세 번째 글자는 상대방이다. 첫 번째 글자와 세 번째 글자는 항상 다르다.
|
||||
- 두 번째 글자는 항상 ~이다.
|
||||
- 네 번째 글자는 다음 3개 중 하나이다. {=, <, >} 각각 같음, 미만, 초과를 의미한다.
|
||||
- 다섯 번째 글자는 0 이상 6 이하의 정수의 문자형이며, 조건에 제시되는 간격을 의미한다. 이때 간격은 두 프렌즈 사이에 있는 다른 프렌즈의 수이다.
|
||||
|
||||
|
||||
### 출력(Output)
|
||||
|
||||
모든 조건을 만족하는 경우의 수를 리턴한다.
|
||||
|
||||
### 예제입출력
|
||||
|
||||
| n | data | answer |
|
||||
| -- | ---- | ------ |
|
||||
| 2 | ["N~F=0", "R~T>2"] | 3648 |
|
||||
| 2 | ["M~C<2", "C~M>1"] | 0 |
|
||||
|
||||
### 예제에대한 설명
|
||||
|
||||
첫 번째 예제는 문제에 설명된 바와 같이, 네오는 프로도와의 간격이 0이기를 원하고 라이언은 튜브와의 간격이 2보다 크기를 원하는 상황이다.
|
||||
|
||||
두 번째 예제는 무지가 콘과의 간격이 2보다 작기를 원하고, 반대로 콘은 무지와의 간격이 1보다 크기를 원하는 상황이다. 이는 동시에 만족할 수 없는 조건이므로 경우의 수는 0이다.
|
||||
|
||||
</div>
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
## 2. 문제 풀이
|
||||
|
||||
카카오 친구들의 일렬로 나열되는 순열의 경우를 우선적으로 구해보았다.
|
||||
|
||||
순열 방식을 이용해서 우선적으로 카카오 친구들의 순서를 나열한다.
|
||||
|
||||
<sub>n</sub>P<sub>r</sub>을 아래와 같은 방식으로 정의할 수 있다.
|
||||
|
||||
```java
|
||||
public void permutation(char[] arr, int depth, int n, int r) {
|
||||
if(depth == r) {
|
||||
print(arr);
|
||||
return;
|
||||
}
|
||||
|
||||
for(int i = depth; i < n; i++) {
|
||||
swap(arr, depth, i);
|
||||
permutation(arr, depth + 1, n, r);
|
||||
swap(arr, depth, i);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
이렇게 모든 카카오친구들의 순열을 구했다면, 입력된 data 배열의 방식대로 조건에 따라서 카운팅을 할 것인지 그냥 return 할 것인지를 구해준다.
|
||||
|
||||
이때, 주의하여야 할 것은 두 친구 사이의 조건을 나타낸 것 이므로 사이 숫자는 `+1`을 시켜주어서 비교해야 한다.
|
||||
|
||||
|
||||
그럼 이것을 활용하여 코드로 표현해보자.
|
||||
|
||||
```java
|
||||
import java.io.BufferedReader;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStreamReader;
|
||||
import java.util.StringTokenizer;
|
||||
|
||||
public class GroupPhoto_level2 {
|
||||
// 어피치, 콘, 프로도, 제이지, 무지, 네오, 라이언, 튜브
|
||||
static char[] kakaoFriends = {'A', 'C', 'F', 'J', 'M', 'N', 'R', 'T'};
|
||||
static int totalcnt;
|
||||
|
||||
public static int findFriend(char[] kakao, char pick) {
|
||||
for(int i = 0; i < kakao.length; i++) {
|
||||
if(kakao[i] == pick) return i;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
|
||||
public static void checkOrder(char[] kakao, String[] data) {
|
||||
int len = data.length;
|
||||
for(int i = 0; i < len; i++) {
|
||||
char[] tmp = data[i].toCharArray();
|
||||
int first = findFriend(kakao, tmp[0]);
|
||||
int second = findFriend(kakao, tmp[2]);
|
||||
int gap = tmp[4] - '0';
|
||||
if(tmp[3] == '=') {
|
||||
if(Math.abs(first - second) != gap + 1) return;
|
||||
} else if(tmp[3] == '<') {
|
||||
if(Math.abs(first - second) >= gap + 1) return;
|
||||
} else if(tmp[3] == '>') {
|
||||
if(Math.abs(first - second) <= gap + 1) return;
|
||||
}
|
||||
}
|
||||
|
||||
totalcnt++;
|
||||
}
|
||||
|
||||
public static void swap(char[] data, int depth, int i) {
|
||||
char tmp = data[depth];
|
||||
data[depth] = data[i];
|
||||
data[i] = tmp;
|
||||
}
|
||||
|
||||
public static void permutation(char[] arr, int depth, int n, int r, String[] data) {
|
||||
if(depth == r) {
|
||||
checkOrder(arr, data);
|
||||
return;
|
||||
}
|
||||
|
||||
for(int i = depth; i < n; i++) {
|
||||
swap(arr, depth, i);
|
||||
permutation(arr, depth + 1, n, r, data);
|
||||
swap(arr, depth, i);
|
||||
}
|
||||
}
|
||||
public static int solution(int n, String[] data) {
|
||||
totalcnt = 0;
|
||||
permutation(kakaoFriends, 0, 8, 8, data);
|
||||
return totalcnt;
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
|
||||
StringTokenizer st = new StringTokenizer(br.readLine());
|
||||
|
||||
int N = Integer.parseInt(st.nextToken());
|
||||
String[] data = new String[N];
|
||||
st = new StringTokenizer(br.readLine());
|
||||
for(int i = 0; i < N; i++) {
|
||||
data[i] = st.nextToken();
|
||||
}
|
||||
|
||||
System.out.println(solution(N, data));
|
||||
}
|
||||
}
|
||||
```
|
||||
70
src/content/blog/study/aws/2024-05-15-start-aws.md
Normal file
70
src/content/blog/study/aws/2024-05-15-start-aws.md
Normal file
@@ -0,0 +1,70 @@
|
||||
---
|
||||
title: AWS 공부 내용 정리
|
||||
date: 2024-05-15
|
||||
tags: aws, 공부
|
||||
excerpt: AWS 공부를 시작하면서
|
||||
---
|
||||
# AWS Certified Developer - Associate 시험 응시
|
||||
|
||||
회사에서 AWS를 사용하게 되면서 AWS-SDK for cpp를 다루게 되었고, 자연스럽게 AWS에 대한 관심이 생겼다.
|
||||
|
||||
때문에 올해가 가기 전에 AWS 자격증 공부를 한번 해보고 싶다는 생각을 했었다.
|
||||
|
||||
그런데 같은 생각을 가진 동료들이 있었고, 이번 기회에 같이 응시를 해보려고 한다.
|
||||
|
||||
때문에 이 글은 그런 공부와 관련된 내용을 기록하는 것이다.
|
||||
|
||||
시험 응시일은 24년 06월 21일 (금)! 화이팅해보자!!
|
||||
|
||||
---
|
||||
|
||||
# Udemy 강의 수료 목표!
|
||||
|
||||
## Stephane Maarek | Ultimate AWS Certified Developer Associate 2024 NEW DVA-C02
|
||||
공부는 기간을 1달로 Udemy 강의를 빠르게 본 뒤에 바로 덤프 문제풀이로 들어가는 것이 최초 전략이다.
|
||||
|
||||
강의는 가장 유명한 [Stephane Maarek의 Ultimate AWS Certified Developer Associate 2024 NEW DVA-C02](https://www.udemy.com/course/aws-certified-developer-associate-dva-c01/) 로 선택하였고, 강의 길이가 460회가 넘다보니 핸즈온은 생략하고 개념 중심으로 들을 생각이다.
|
||||
|
||||
강의의 절반을 차지하는 기본 개념들은 단독 문제로 거의 출제되지 않는다는 말이 있기에 2부에 해당하는 Serverless 이전의 기본 개념들(EC2, S3, DB, Route53 등)은 거의 개념만 볼 계획이고, DynamoDB, Lambda, CI/CD 중심으로 공부를 진행하려고 한다.
|
||||
|
||||
덤프는 [examtopics](https://www.examtopics.com/exams/amazon/) 를 추천하길래 그 위주로 문제를 풀어볼 생각이고, 실제로 discussion을 통해 정답에 대한 사람들의 의견도 볼 수 있어서 정확하게 파악하기 좋을 것 같다.
|
||||
|
||||
---
|
||||
|
||||
## 강의 섹션 정리
|
||||
- Section 1 : Course Introduction - AWS Certified Developer Associate
|
||||
- Section 2 : Code & Slides Download
|
||||
- Section 3 : Getting started with AWS
|
||||
- Section 4 : IAM & AWS CLI
|
||||
- Section 5 : EC2 Fundamentals
|
||||
- Section 6 : EC2 Instance Storage
|
||||
- Section 7 : AWS Fundamentals: ELB + ASG
|
||||
- Section 8 : AWS Fundamentals: RDS + Aurora + ElastiCache
|
||||
- Section 9 : Route 53
|
||||
- Section 10 : VPC Fundamentals
|
||||
- Section 11 : Amazon S3 Introduction
|
||||
- Section 12 : AWS CLI, SDK, IAM Roles & Policies
|
||||
- Section 13 : Advanced Amazon S3
|
||||
- Section 14 : Amazon S3 Security
|
||||
- Section 15 : CloudFront
|
||||
- Section 16 : ECS, ECR & Fargate - Docker in AWS
|
||||
- Section 17 : AWS Elastic Beanstalk
|
||||
- Section 18 : AWS CloudFormation
|
||||
- Section 19 : AWS Integration & Messaging: SQS, SNS & Kinesis
|
||||
- Section 20 : AWS Monitoring & Audit: CouldWatch, X-Ray and CloudTrail
|
||||
- Section 21 : AWS Serverless: Lambda
|
||||
- Section 22 : AWS Serverless: DynamoDB
|
||||
- Section 23 : AWS Serverless: API Gateway
|
||||
- Section 24 : AWS CICD: CodeCommit, CodePipeline, CodeBuild, CodeDeploy
|
||||
- Section 25 : AWS Serverless: SAM - Serverless Application Model
|
||||
- Section 26 : Could Development Kit (CDK)
|
||||
- Section 27 : Cognito: Cognito User Pools, Cognito Identity Pools & Cognito Sync
|
||||
- Section 28 : Other Serverless: Step Functions & AppSync
|
||||
- Section 29 : Advanced Identity
|
||||
- Section 30 : AWS Security & Encryption: KMS, Encryption SDK, SSM Parameter Store, IAM & STS
|
||||
- Section 31 : AWS Other Serverless
|
||||
- Section 32 : AWS Final Cleanup
|
||||
- Section 33 : Preparing for the Exam - AWS Certified Developer Associate
|
||||
- Section 34 : Congratulations - AWS Certified Developer Associate
|
||||
|
||||
징그럽게 많다.. 화이팅!
|
||||
207
src/content/blog/study/aws/2024-05-15-start-aws2.md
Normal file
207
src/content/blog/study/aws/2024-05-15-start-aws2.md
Normal file
@@ -0,0 +1,207 @@
|
||||
---
|
||||
title: AWS 공부 내용 정리
|
||||
date: 2024-05-15
|
||||
tags: aws, 공부
|
||||
excerpt: AWS 강의를 시작
|
||||
---
|
||||
# AWS 강의 시작
|
||||
|
||||
시작부터 시험에 맞춰진 강의라는 느낌을 받았다.
|
||||
|
||||
섹션 1 ~ 11 까지 기초 강의로 되어 있고, 3, 4 & 5는 스킵해도 된다고 되어 있어서 당황스럽긴 한데..
|
||||
|
||||
한번보고 안 볼꺼면 어떻게 보라고 강의 순서까지 정리해두네 😃
|
||||
|
||||
#### Please watch the following lectures:
|
||||
|
||||
- Section 7 - AWS Fundamentals: ELB + ASG
|
||||
- Auto Scaling Groups - Instance Refresh
|
||||
- Section 8 - AWS Fundamentals: RDS + Aurora + ElastiCache
|
||||
- ElastiCache Strategies
|
||||
- Amazon MemoryDB for Redis
|
||||
- Section 9 - Route 53
|
||||
- Routing Policy - Traffic Flow & Geoproximity Hands On
|
||||
- Section 10 - VPC Fundamentals
|
||||
- VPC Fundamentals - Section Introduction
|
||||
- VPC, Subnets, IGW and NAT
|
||||
- NACL, SG, VPC Flow Logs
|
||||
- VPC Peering, Endpoints, VPN, DX
|
||||
- VPC Cheat Sheet & Closing Comments
|
||||
- Three Tier Architecture
|
||||
- Section 12 - AWS CLI, SDK, IAM Roles & Policies
|
||||
- AWS EC2 Instance Metadata
|
||||
- AWS EC2 Instance Metadata - Hands On
|
||||
- AWS CLI Profiles
|
||||
- AWS CLI with MFA
|
||||
- AWS SDK Overview
|
||||
- Exponential Backoff & Service Limit Increase
|
||||
- AWS Credentials Provider & Chain
|
||||
- AWS Signature v4 Signing
|
||||
- Section 15 - CloudFront
|
||||
- CloudFront - Caching & Caching Policies
|
||||
- CloudFront - Cache Behaviors
|
||||
- CloudFront - Caching & Caching Invalidations - Hands On
|
||||
- CloudFront - Signed URL / Cookies
|
||||
- CloudFront - Signed URL - Key Groups + Hands On
|
||||
- CloudFront - Advanced Concepts
|
||||
- CloudFront - Real Time Logs
|
||||
- Section 16 - ECS, ECR & Fargate - Docker in AWS
|
||||
- Amazon ECS - Rolling Updates
|
||||
- Amazon ECS Task Definitions - Deep Dive
|
||||
- Amazon ECS Task Definitions - Hands On
|
||||
- Amazon ECS - Task Placements
|
||||
- Amazon ECR - Hands On
|
||||
- And everything from Section 17 onwards
|
||||
|
||||
이것만 들어도 되는건지는 모르겠다.
|
||||
|
||||
---
|
||||
|
||||
## AWS 가입
|
||||
|
||||
이전에 aws 찍먹해보겠다고 가입했었는데, 90일 지나서 비활성화가 되어 버렸네;;
|
||||
|
||||
찾아보니 account+tag@mail.com 이런식으로 태그를 달면 원래 이메일 계정으로 인식해서 코드를 보내주길래 다시 가입을 했다.
|
||||
|
||||
시작부터 당황스러웠지만 어쩔 수 없지.
|
||||
|
||||
관련해서 강의에서도 정리를 해뒀는데 이건 못봤네 😂
|
||||
|
||||
아무튼 생성 완!!
|
||||
|
||||
---
|
||||
|
||||
## AWS 역사와 Regions
|
||||
|
||||
이건 빠르게 보고 지나가자
|
||||
|
||||
---
|
||||
|
||||
## AWS Console
|
||||
|
||||
Aws Console에 대한 내용을 다루는데 하나씩 보면서 친숙해지는 방법이 좋을것 같다.
|
||||
|
||||
이전에도 EC2와 같은 서비스를 이용해본적 있는데, 꽤 많이 한글 최적화도 된거 같고 콘솔이 친숙화가 진행된거 같다.
|
||||
|
||||
---
|
||||
|
||||
## IAM
|
||||
|
||||
IAM 이란?
|
||||
IAM = Identity and Access Management, Global service
|
||||
로 ID와 엑세스 관리의 약자이다.
|
||||
|
||||
IAM에서는 사용자를 생성하고 그룹에 할당할 수 있다.
|
||||
|
||||
유저(Users)는 조직에서의 사람을 뜻하며 그룹으로 될 수 있다.
|
||||
|
||||
그룹(Groups)는 오직 유저를 포함하고 있고 다른 그룹은 포함할 수 없다.(중요)
|
||||
|
||||
어떤 유저는 그룹에 속해있지 않아도 된다.
|
||||
|
||||
또한, 각 그룹 사이에 그룹을 생성할 수 있다.
|
||||
|
||||
### 왜 사용자와 그룹을 생성할까?
|
||||
|
||||
AWS를 사용하기 위한 Permissions 때문이다.
|
||||
|
||||
유저와 그룹은 정책이라고 불리는 JSON 문서를 기반으로 한다.
|
||||
|
||||
이러한 정책은 유저들의 사용 권한을 결정한다.
|
||||
AWS에서는 최소한의 원칙을 적용할 수 있다. 유저가 필요한것 보다 더 많은 권한을 주지 않는다.
|
||||
|
||||
#### Tags
|
||||
|
||||
Tags는 AWS 어디에서나 사용 가능한 선택 사항이다. 메타데이터를 여러 리소스에 남길 수 있다는 장점이 있다.
|
||||
|
||||
#### AWS Account
|
||||
|
||||
AWS Account 에는 사용자 계정이 들어 있고, 로그인 url가 있다.
|
||||
해당 url는 alias(별칭)을 생성해서 간단하게 접근 가능하다. (단, unique 해야 한다.)
|
||||
|
||||
#### IAM 유저 로그인
|
||||
|
||||
해당 로그인 url를 통해서 관련 계정으로 들어갈 수 있고, IAM 유저 로그인 상에 alias를 통해서 접근이 가능해진다.
|
||||
항상 콘솔 로그인에서 루트계정과 IAM계정의 접근이 이해가 안갔었는데, 이 부분을 확실하게 이해할 수 있었던것 같다.
|
||||
|
||||
### IAM Policies
|
||||
|
||||
그룹에 IAM Policies를 적용하게 되면 그 그룹 안에 있는 모든 유저에게 접근되고 상속되게 된다.
|
||||
|
||||
inline policy 라는 방식으로 한 유저에게만 직접적으로 생성 가능하다.
|
||||
|
||||
### IAM Structure
|
||||
|
||||
- Version : 정책 언어 버전, 일반적으로 날짜로 되어 있는 경우가 많다.
|
||||
- ID : 정책을 확인하는 방법인데 선택사항이다.
|
||||
- Statement : 하나 이상의 구문을 작성해야 한다.
|
||||
- Sid : 구문의 식별자로 선택사항이다.
|
||||
- Effect : 해당 구문을 허용할지 거부할지에 대한 내용이다. (Allow/Deny)
|
||||
- Principal : 어떤 계정, 사용자, 혹은 역할이 이 정책에 적용될지를 결정한다.
|
||||
- Action : API 호출 목록이다.
|
||||
- Resource : 작업을 적용할 리소스 목록이다.
|
||||
- Condition : 이 정책을 적용하기 위한 조건, 선택 사항이다.
|
||||
~~~
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
"ID": "S3-Account-Permissions",
|
||||
"Statement": [
|
||||
{
|
||||
"Sid": "1",
|
||||
"Effect": "Allow",
|
||||
"Principal": {
|
||||
"AWS": ["arn:aws:iam::123456789012:root"]
|
||||
},
|
||||
"Action": [
|
||||
"s3:GetObject",
|
||||
"s3:PutObject"
|
||||
],
|
||||
"Resource": ["arn:aws:s3:::mybucket/*"]
|
||||
},
|
||||
{
|
||||
"Effect": "Allow",
|
||||
"Action": "ec2:Describe*",
|
||||
"Resource": "*"
|
||||
},
|
||||
{
|
||||
"Effect": "Allow",
|
||||
"Action": "elasticloadbalancing:Describe*",
|
||||
"Resource": "*"
|
||||
},
|
||||
{
|
||||
"Effect": "Allow",
|
||||
"Action": [
|
||||
"cloudwatch:ListMetrics",
|
||||
"cloudwatch:GetMetricStatistics",
|
||||
"cloudwatch:Describe*"
|
||||
],
|
||||
"Resource": "*"
|
||||
}
|
||||
]
|
||||
}
|
||||
~~~
|
||||
|
||||
### IAM - Password Policy
|
||||
|
||||
AWS에는 패스워드 정책이 다양하다.
|
||||
- 최소한의 길이 설정
|
||||
- 특별한 문자 요구
|
||||
- 스스로 패스워드 변경 허용
|
||||
- password expiration 설정하여 90일 후에 변경을 요구
|
||||
- 재사용 방지
|
||||
|
||||
### MFA
|
||||
|
||||
MFA - Multi Factor Authentication
|
||||
Root 계정과 IAM 유저를 보호하기 위해 사용한다.
|
||||
|
||||
MFA = password you know + security device you own
|
||||
|
||||
MFA devices options in AWS
|
||||
- Virtual MFA device
|
||||
- Google Authenticator
|
||||
- Authy
|
||||
- Universal 2nd Factor (U2F) Security Key
|
||||
- 3rd party
|
||||
- Hardware Key Fob MFA Device
|
||||
- Hardware Key Fob MFA Device for AWS GovCloud (US)
|
||||
76
src/content/blog/study/cs/2022-12-13-byteOrdering.md
Normal file
76
src/content/blog/study/cs/2022-12-13-byteOrdering.md
Normal file
@@ -0,0 +1,76 @@
|
||||
---
|
||||
title: 바이트오더링 정리
|
||||
date: 2022-12-13
|
||||
tags: cs, 공부
|
||||
excerpt: 바이트오더링(Byte Ordering)
|
||||
---
|
||||
## 바이트 오더링 이란?
|
||||
|
||||
바이트 오더링(Byte Ordering)은 데이터가 바이트(Byte) 단위로 메모리에 저장되는 순서를 말한다. <br />
|
||||
|
||||
크게 **Big-Endian** 방식과 **Little-Endian** 방식이 존재하며 각 CPU 벤더에 의존적인 특징을 가지고 있다. <br />
|
||||
|
||||
2 바이트 이상의 크기를 가진 자료형을 저장할 때부터 차이가 난다. <br />
|
||||
|
||||
```
|
||||
BYTE b = 0x12;
|
||||
|
||||
WORD w = 0x1234;
|
||||
|
||||
DWORD dw = 0x12345678;
|
||||
|
||||
char str[] = "abcde";
|
||||
|
||||
```
|
||||
|
||||
| Type | Name | Size | Big-Endian | Little-Endian |
|
||||
| --- | --- | --- | ----- | ----- |
|
||||
| BYTE | b | 1 | [12] | [12] |
|
||||
| WORD | w | 2 | [12][34] | [34][12] |
|
||||
| DWORD | dw | 4 | [12][34][56][78] | [78][56][34][12] |
|
||||
| char[] | str | 6 | [61][62][63][64][65][00] | [61][62][63][64][65][00] |
|
||||
|
||||
## Big-Endian 방식
|
||||
|
||||
> 상위 바이트의 값이 메모리에 먼저 표시되는 방법 (번지수가 작은 위치)
|
||||
|
||||
사용되는 계열 : 대형 UNIX 서버에 사용되는 RISC 계열의 CPU
|
||||
|
||||
|
||||
|
||||
네트워크 데이터 통신에서는 네트워크 바이트 순서(Network Byte Order, 즉 Big-Endian)를 따르도록 데이터의 바이트 순서를 변경해야 한다. <br />
|
||||
(TCP/IP, XNS, SNA 규약은 16비트와 32비트 정수에서 Big-Endian 방식을 사용함) <br />
|
||||
|
||||
따라서 시스템이 Little-Endian 방식을 사용할 경우 네트워크를 통해 데이터를 전송하기 전에 Big-Endian 방식으로 데이터를 변경해서 보내야만 하고 받을 때는 Little-Endian 시스템은 전송되어 오는 데이터를 역순으로 조합해야 함.
|
||||
|
||||
## Little-Endian 방식
|
||||
|
||||
> 하위 바이트의 값이 메모리상에 먼저 표시되는 방법 (번지수가 작은 위치)
|
||||
|
||||
사용되는 계열 : Intel 계열의 CPU
|
||||
|
||||
|
||||
|
||||
## 두 Endian 방식의 장단점
|
||||
|
||||
Big-Endian 방식은 소프트웨어의 디버그를 편하게 해 주는 경향이 있다. <br />
|
||||
사람이 숫자를 읽고 쓰는 방법과 같기 때문에 디버깅 과정에서 메모리의 값을 보기 편하다. <br />
|
||||
|
||||
예를 들어 0x59654148 은 빅 엔디언으로 59 65 41 48 로 표현한다. <br />
|
||||
|
||||
반대로 Little-Endian 방식 은 메모리에 저장된 값의 하위 바이트들만 사용할 때 별도의 계산이 필요 없다는 장점이 있다. <br />
|
||||
|
||||
예를 들어 32비트 숫자인 0x2A 는 Little-Endian 방식으로 표현하면 2A 00 00 00 이 되는데 이 표현에서 앞의 두 바이트 또는 한 바이트만 떼어 내면 하위 16 비트 또는 8 비트를 바로 얻을 수 있다. <br />
|
||||
|
||||
반면 32bit Big-Endian 방식 환경에서는 하위 16 비트나 8 비트 값을 얻기 위해서는 변수 주소에 2바이트 또는 3바이트를 더해야 한다. <br />
|
||||
|
||||
보통 변수의 첫 바이트를 그 변수의 주소로 삼기 때문에 이런 성질은 종종 프로그래밍을 편하게 하는 반면 Little-Endian 방식 환경의 프로그래머가 Big-Endian 방식 환경에서 종종 실수를 일으키는 한 이유이기도 하다. <br />
|
||||
|
||||
또한, 가산기가 덧셈을 하는 과정은 LSB 로부터 시작하여 자리 올림을 계산해야 하므로 첫 번째 바이트가 LSB 인 Little-Endian 방식에서는 가산기 설계가 조금 더 단순해진다. <br />
|
||||
|
||||
Big-Endian 방식에서는 가산기가 덧셈을 할때 마지막 바이트로부터 시작하여 첫 번째 바이트까지 역방향으로 진행해야 한다. <br />
|
||||
|
||||
그러나 오늘날의 프로세서는 여러개의 바이트를 동시에 읽어들여 동시에 덧셈을 수행하는 구조를 갖고 있어 두 Endian 방식 사이에 사실상 차이가 없다. <br />
|
||||
|
||||
[참고 사이트] :
|
||||
https://ko.wikipedia.org/wiki/%EC%97%94%EB%94%94%EC%96%B8
|
||||
289
src/content/blog/study/cs/2022-12-13-multiProcess.md
Normal file
289
src/content/blog/study/cs/2022-12-13-multiProcess.md
Normal file
@@ -0,0 +1,289 @@
|
||||
---
|
||||
title: Multi Process & Thread 정리
|
||||
date: 2022-12-13
|
||||
tags: cs, 공부
|
||||
excerpt: Multi Process & Thread
|
||||
---
|
||||
# Multi Process & Thread
|
||||
CS 지식에서 제일 많이 물어보는 부분이 Multi Process와 Thread가 아닐까 한다.
|
||||
|
||||
학부생 시절부터 정리했던 부분이지만 다시 한 번 더 정리하고 정의하고자 한다.
|
||||
|
||||
## Process 란?
|
||||
> Process란 하나 혹은 그 이상의 Thread로 실행되는 컴퓨터 프로그램의 instance이다. <br />
|
||||
> Process는 Program Code와 Activity를 포함한다. <br />
|
||||
> - Wikipedia
|
||||
|
||||
> 프로세스는 가상 메모리 공간, 코드, 데이터, 시스템 자원의 집합이다. <br />
|
||||
> - Microsoft
|
||||
|
||||
프로세스는 운영체제가 프로그램을 실행하기 위해 필요한 가장 작은 단위의 쓰레드, 메모리, 소스코드들의 집합이며 프로그램 동작 그 자체를 의미한다. <br />
|
||||
운영체제는 프로세스를 작업의 단위로 보고 자원들을 프로세스들에 적절하게 배분한다. <br />
|
||||
|
||||
쉽게 말하자면 프로세스란 실행중인 프로그램이라고 볼 수도 있다.
|
||||
|
||||
### Process의 상태 (States)
|
||||
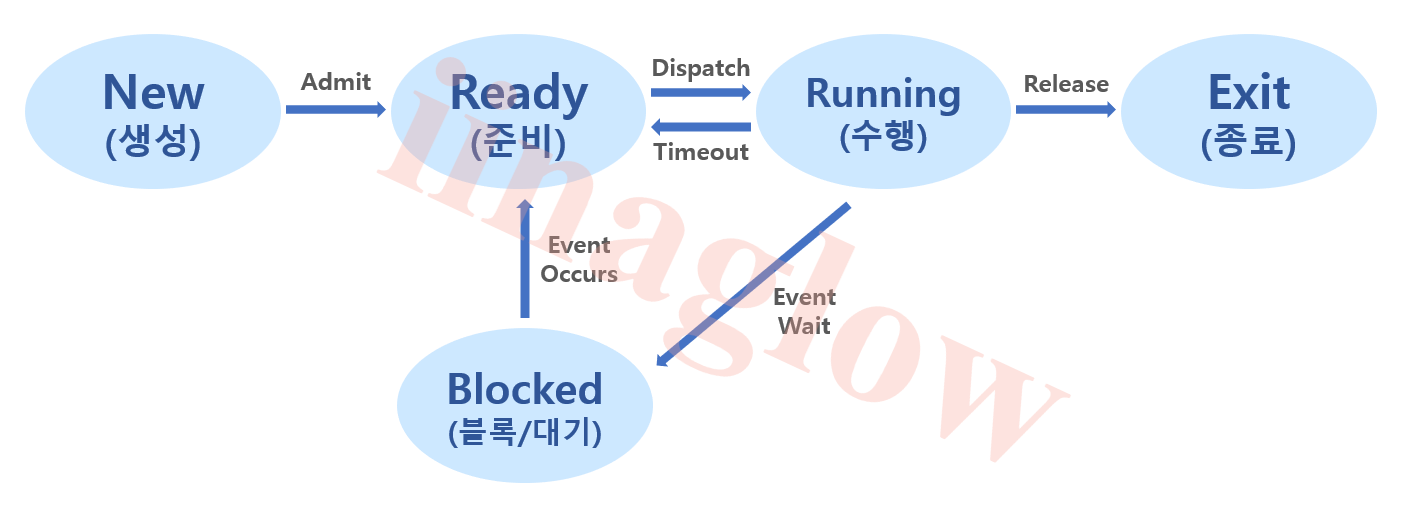
|
||||
[출처](https://iingang.github.io/posts/OS-process/)
|
||||
|
||||
위 그림을 프로세스의 5 가지 상태(Five States)라고 한다. <br />
|
||||
9 가지 상태로 상세히 표현하는 방식도 있지만 이 글에서는 5 가지 상태를 다룰 것이다. <br />
|
||||
|
||||
- New : 프로세스가 생성 되었지만, 운영체제에 의해 수행 가능한 프로세스 풀로의 진입이 허용되지 않은 상태
|
||||
- Ready : 자원이 할당되면 수행할 준비가 되어 있는 상태
|
||||
- Running : 현재 수행 중인 프로세스
|
||||
- Blocked : 입출력 연산(I/O)와 같은 작업 중 완료가 될 때까지 수행될 수 없는 프로세스
|
||||
- Exit(Terminated) : 프로세스 수행이 중지되거나, 어떤 이유로 중단되었기 때문에 프로세스 풀에서 방출된 프로세스, 종료된 상태
|
||||
|
||||
#### Process 상태 변화 요인
|
||||
##### New -> Ready(Admitted)
|
||||
New 상태에서 OS의 승인을 받아서 프로세스가 생성이 되면, 해당 프로세스의 PCB가 OS커넗의 Ready Queue에 올라온다. <br />
|
||||
##### Ready -> Running(Scheduler dispatch)
|
||||
Ready Queue에 있는 프로세스들 중에서 스케줄링 알고리즘에 의해서 선택된 프로세스가 CPU를 할당 받는다. <br />
|
||||
##### Running -> Blocked(Wait)
|
||||
현재 CPU의 명령을 받아서 명령어를 수행중인 프로세스가 I/O와 같은 특정 작업을 해야하는 경우 CPU를 반납하고 해당 장치 큐에 들어가게 된다. <br />
|
||||
##### Blocked -> Ready(I/O Completion or interrupt)
|
||||
작업을 위해 장치 큐에 있던 프로세스가 디스크 컨트롤러에 의해 서비스를 받아 일을 하고, <br />
|
||||
디스크 컨트롤러가 인터럽트를 발생하여 프로세스가 한 일을(로컬 버퍼에 저장된 데이터) 메모리에 올려놓고 프로세스는 다시 Ready Queue에 들어가게 된다. <br />
|
||||
##### Running -> Exit
|
||||
프로세스 실행이 완료되어 자원을 반납한 상태 <br />
|
||||
|
||||
### Process 메모리
|
||||
운영체제는 프로세스 마다 고유의 가상 메모리 공간을 제공한다. 이러한 메모리 공간은 Data, Text, Stack/Heap Section으로 나뉜다. <br />
|
||||
|
||||

|
||||
[출처](https://velog.io/@curiosity806/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EB%9E%80)
|
||||
|
||||
- Stack :
|
||||
- 매개변수, 지역변수, return 주소 등과 같은 데이터를 저장하는 영역이다.
|
||||
- 컴파일러에 의해 Run Time 도중 크기가 결정되며, 함수가 호출&종료 되는 시점에서 생성&제거 된다.
|
||||
- Heap :
|
||||
- new, delete, malloc, free 등을 호출하여 데이터를 저장, 관리하는 영역
|
||||
- Run Time에 크기가 결정
|
||||
- Data Section :
|
||||
- 사전에 선언된 데이터가 저장되는 영역이다. (global, staic, variables, etc)
|
||||
- Compile Time에 크기가 결정된다.
|
||||
- 내부에서 DATA & BBS 영역으로 구분된다.
|
||||
- DATA : 초기화된 전역변수가 저장되는 영역이다. (Initialized data section)
|
||||
- BBS : 초기화되지 않은 전역변수가 저장되는 영역이다. (Uninitialized data section)
|
||||
- Instruction(Text Section) :
|
||||
- 컴파일된 기계어가 저장되는 영역이다.
|
||||
- Compile Time에 크기가 결정된다.
|
||||
|
||||
### PCB(Process Controll Block)
|
||||
Process 마다 현재 상태를 하나의 데이터 구조에 저장하여 관리하는데, 이를 Process Controll Block이라고 한다. <br />
|
||||
PCB는 다른 프로세스들이 쉽게 접근할 수 없고, Kernel 영역에 저장된다. <br />
|
||||
|
||||
운영체제가 프로세스를 관리하기 위해 필요한 정보를 담고 있는 자료구조이며, <br />
|
||||
주요 역할은 수행 프로세스를 인터럽트한 후 나중에 그 인터럽트가 발생되지 않은 것처럼 프로세스 수행을 재개하도록 충분한 정보를 유지하는 것이다. <br />
|
||||
|
||||
PCB는 프로세스 식별자, 프로세서(CPU) 상태 정보, 프로세스 제어 정보를 담고 있다. <br />
|
||||

|
||||
|
||||
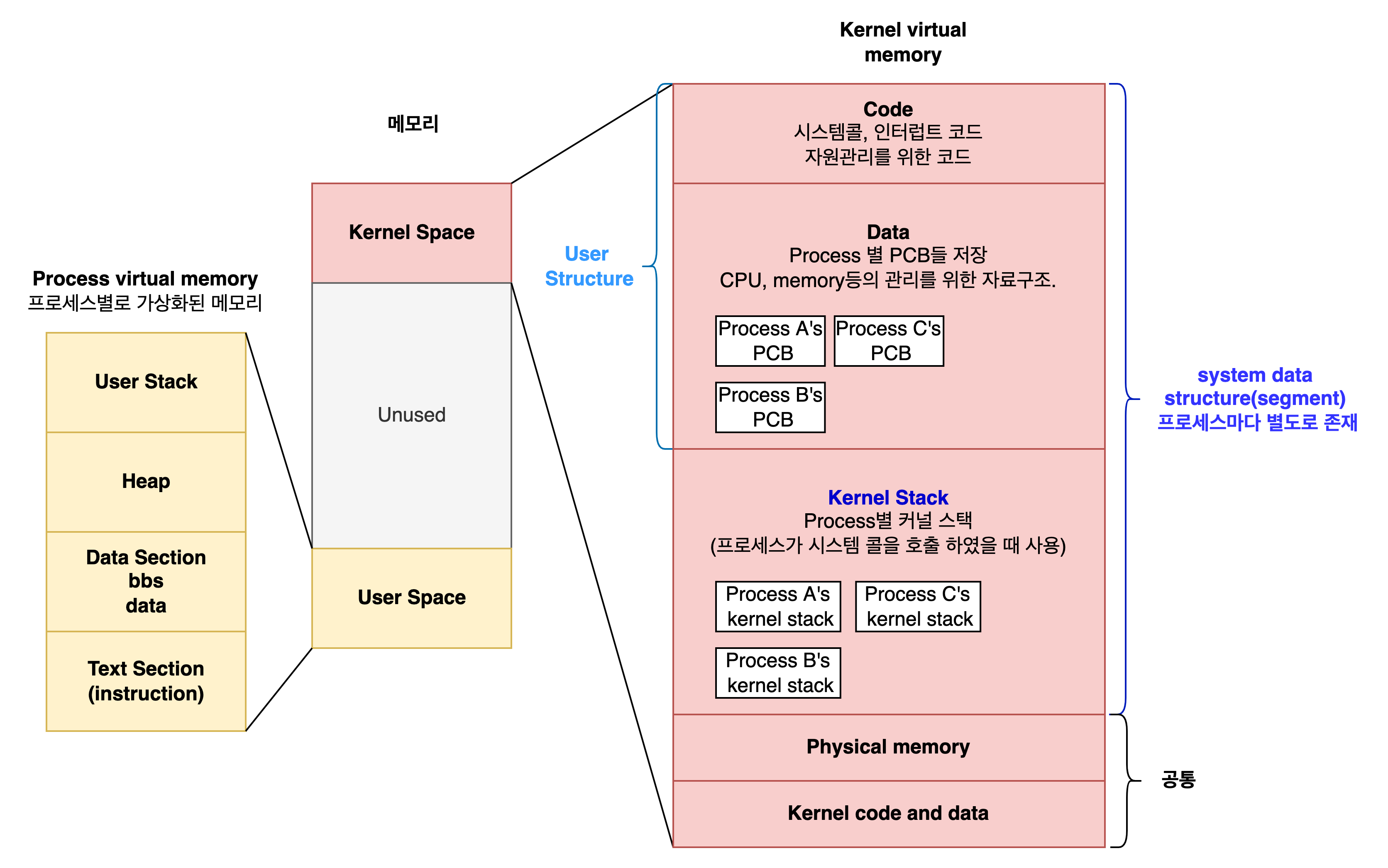
|
||||
|
||||
[출처](https://yoongrammer.tistory.com/52)
|
||||
|
||||
- 포인터 : 프로세스의 현재 위치를 저장하는 포인터 정보
|
||||
- 프로세스 상태 : 프로세스의 각 상태를 저장
|
||||
- 프로세스 번호 : 모든 프로세스에는 프로세스 식별자를 저장하는 프로세스 ID 또는 PID라는 고유한 ID가 할당
|
||||
- 프로그램 카운터 : 프로세스를 위해 실행될 다음 명령어의 주소를 포함하는 카운터를 저장
|
||||
- 레지스터 : 누산기, 베이스, 레지스터 및 범용레지스터를 포함하는 CPU 레지스터에 있는 정보
|
||||
- 메모리 제한 : 운영체제에서 사용하는 메모리 관리 시스템에 대한 정보
|
||||
- 페이지 테이블 : 페이징 프로세스의 메모리 주소를 관리할 때 프로세스의 페이지 정보를 저장하고 있는 테이블
|
||||
- 세그먼트 테이블 : 프로세스를 논리적으로 잘라 메모리에 배치하는 방식을 세그멘테이션이라고 한다. 세그먼트 테이블은 이 세그먼트들의 실제 물리적 메모리 주소의 정보를 담고 있다.
|
||||
- 열린 파일 목록 : 프로세스를 위해 열린 파일 목록
|
||||
- Accountin 정보 : Process를 실행한 유저 정보
|
||||
- I/O 상태 정보 : Process에 할당된 물리적 장치 및 프로세스가 읽고 있는 파일에 관한 정보
|
||||
|
||||
### Process 생성
|
||||
프로세스 생성은 부모 프로세스가 연산을 통해 자식 프로세스를 만들어낸다. 생성된 자식 프로세스 또한 새로운 자식 프로세스를 만들 수 있으며, 이를 구별하기 위해 모든 프로세스는 각자 고유의 PID를 가지고 있다. <br />
|
||||
이렇게 생성된 프로세스 간의 관계는 하나의 큰 트리구조가 된다. <br />
|
||||
|
||||
생성된 자식 프로세스는 각자 고유의 PID, 메모리, CPU 등 새 PCB가 할당되며 고유의 자원을 획득하게 된다. <br />
|
||||
이로 인하여 부모 프로세스의 자원 접근에 제한이 생기며 특수한 방법을 통해 공유할 수 있게 된다. <br />
|
||||
|
||||
프로세스를 생성한 후 부모 프로세스는 다음과 같이 2가지 행동을 할 수 있다.
|
||||
|
||||
> 자식 프로세스가 끝날 때까지 기다린다 ( -> waiting queue ) <br />
|
||||
> 자식 프로세스와 함께 동작 (멀티 프로세싱 환경) <br />
|
||||
|
||||
|
||||
> 자식 프로세스는 다음 중 하나의 프로세스가 된다. <br />
|
||||
> - 부모 프로세스와 동일한 새로운 프로세스 : 이 경우 부모 프로세스의 프로그램, 데이터가 완전 복사
|
||||
> - 새로운 프로그램 실행 : 새로운 프로그램을 메모리에 load 하고 이를 실행
|
||||
|
||||
#### fork()
|
||||
Linux/UNIX 환경에서 새로운 프로세스를 만드는 시스템 콜 함수
|
||||
|
||||
생성된 자식 프로세스는 부모 프로세스의 데이터와 프로그램이 완전 복사가 되어 똑같은 프로그램을 수행하는 프로세스가 된다. <br />
|
||||
멀티 프로세싱을 통해 부모, 자식 프로세스는 함께 동작한다. <br />
|
||||
fork() 함수는 부모 프로세스에서 자식의 PID를 반환하고, 자식 프로세스에서는 0을 반환하여 구분할 수 있도록 해준다. <br />
|
||||

|
||||
|
||||
#### exec()
|
||||
Linux/UNIX 환경에서 프로세스를 새로운 프로그램을 실행하는 프로세스로 대체하는 시스템 콜 함수
|
||||
|
||||
fork()와 다르게 자식 자식 프로세스를 생성하는 것이 아닌 현재 프로세스의 프로그램 코드를 새로운 프로그램 코드로 바꿔준다. <br />
|
||||
이로 인하여 프로그램 코드, 메모리, 파일 등 프로세스 자원이 새로 바뀌게 된다. <br />
|
||||
exec() 함수는 현재 프로세스가 완전히 새로운 프로그램을 실행하는 프로세스로 대체되므로 반환 값이 없다. <br />
|
||||

|
||||
|
||||
보통 동작하는 방식은 fork()를 통해 자식 프로세스를 생성하고 자식 프로세스에서 exec()를 통해 새로운 프로그램을 돌리게 된다. <br />
|
||||
이때 부로 프로세스가 자식 프로세스가 끝나기를 기다려야 한다면 wait() 시스템 콜 함수를 이용하여 기다릴 수 있다. <br />
|
||||
|
||||
### Multi Process
|
||||
두개 이상, 다수의 프로세서(CPU)가 협력적으로 하나 이상의 작업(Task)을 동시에 처리하는 것이다. (병렬처리) <br />
|
||||
**각 프로세스 간 메모리 구분이 필요하거나 독립된 주소 공간을 가져야 할 경우** 사용한다. <br />
|
||||
|
||||
#### 장점
|
||||
- 독립된 구조로 안전성이 높은 장점이 있다.
|
||||
- 프로세스 중 하나에 문제가 생겨도 다른 프로세스에 영향을 주지 않아, 작업속도가 느려지는 손해정도는 생기지만 정지되거나 하는 문제는 발생하지 않는다.
|
||||
- 여러개의 프로세스가 처리되어야 할 때 동일한 데이터를 사용하고, 이러한 데이터를 하나의 디스크에 두고 모든 프로세서(CPU)가 이를 공유하면 비용적으로 저렴하다.
|
||||
|
||||
#### 문제점
|
||||
- 독립된 메모리 영역이기 때문에 작업량이 많을수록( Context Switching이 자주 일어나서 주소 공간의 공유가 잦을 경우) 오버헤드가 발생하여 성능저하가 발생 할 수 있다.
|
||||
- Context Switching 과정에서 캐시 메모리 초기화 등 무거운 작업이 진행되고 시간이 소모되는 등 오버헤드가 발생한다.
|
||||
|
||||
#### Context Switching
|
||||
CPU는 한번에 하나의 프로세스만 실행 가능하다. <br />
|
||||
때문에 CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 데 이 과정을 Context Switching라 한다. <br />
|
||||
구체적으로, 동작 중인 프로세스가 대기를 하면서 해당 프로세스의 상태(Context)를 보관하고, 대기하고 있던 다음 순서의 프로세스가 동작하면서 이전에 보관했던 프로세스의 상태를 복구하는 작업을 말한다. <br />
|
||||
|
||||
|
||||
### Process간 통신 방식 (IPC : Inter Process Communication)
|
||||
프로세스 간 통신이란 프로세스가 서로 데이터를 주고받는 방법, 경로 등을 의미한다. <br />
|
||||
커널의 디자인에 따라 마이크로 커널, 나노 커널 등 통신이 많이 일어나는 디자인의 경우 IPC 방식이 성능을 크게 좌지우지할 수 있다. <br />
|
||||
|
||||
#### Shared memory
|
||||
운영체제의 도움을 받아 일부 영역의 메모리를 여러 프로세스가 동시에 접근할 수 있도록 권한을 받는다. <br />
|
||||
프로세스는 공유 메모리를 읽고 쓰면서 프로세스 간 통신을 하게 된다. <br />
|
||||
같은 메모리를 사용하는 환경에서 작동하므로 메모리에 접근하여 값을 변경하면 그 즉시 변경된 값이 반영되어 다른 프로세스들이 접근 시 변경된 값을 얻을 수 있다. <br />
|
||||
처음 메모리에 여러 프로세스가 접근 권한을 부여하는 작업에서만 커널 작업이 필요하고 이후엔 커널 동작이 필요 없다. <br />
|
||||
|
||||
##### 동작 과정
|
||||
공유 메모리를 사용할 프로세스들 중 하나의 프로세스가 자신이 부여받은 메모리 영역 중 일부분을 선택 <br />
|
||||
다른 프로세스 들은 공유할 메모리의 주소를 받아 이를 자신의 메모리 영역에 붙인다. <br />
|
||||
운영체제가 해당 프로세스들 간의 메모리 접근 제한을 풀어준다. <br />
|
||||
이후 프로세스들은 공유 메모리를 통해 통신 <br />
|
||||
* 운영체제는 더 이상 관여할 필요 없으며 프로세스가 종료 시 메모리를 반환하면 공유 메모리 또한 같이 반환하게 된다. <br />
|
||||
|
||||
#### Message Passing
|
||||
데이터가 하나의 메시지가 되어 프로세스 간 통신을 하게 된다. <br />
|
||||
충돌 위험이 없기 때문에 소량의 데이터 전송에 유리 <br />
|
||||
명령만을 주고받는 분산 시스템, 마이크로/나노 커널 방식에 유리 <br />
|
||||
공유 메모리 방식과 다르게 같은 환경에 있지 않아도 인터넷을 통해서 메시지를 주고받을 수 있다. (소켓) <br />
|
||||
생산자-소비자 모델의 공유 메모리 방식을 이용하면 동기화 작업이 필요 없지만 메시지 전달 방식은 동기화 작업이 필요한 경우가 많습니다. 비동기, 동기 방식에 따라 결정한다. <br />
|
||||
|
||||
##### Send, Receive 2가지 명령에 의해 동작
|
||||
- Direct communication : send, receive 동작이 특정 프로세스를 지정하며 메시지를 직접 주고 받는다.
|
||||
- Indirect communication : 프로세스들 가운데 하나의 시스템, 네트워크 등을 두고 메시지를 중재하며 동작한다. 직접 전달 방식보다 더 유연하게 동작할 수 있으며 중재 시스템의 구현에 따라 보안성, 성능 등 다양한 처리가 가능해진다.
|
||||
|
||||
##### 동기, 비동기
|
||||
메시지 전달 방식은 동기화 작업이 필요한데, 동기방식과 비동기 방식이 있다. <br />
|
||||
|
||||
> 동기(Blocking, Synchronous) <br />
|
||||
> 동기 Send : 메시지를 보내고 나면 받는 프로세스에게 메시지가 도착할 때까지 다른 작업을 할 수 없다. <br />
|
||||
> 동기 Receive : 메시지를 받기 전까지 해당 프로세스는 다른 작업을 하지 않고 멈춰 있어야 한다. <br />
|
||||
|
||||
|
||||
> 비동기(Nonblocking, Asynchronous) <br />
|
||||
> 비동기 Send : 메시지를 보내고 프로세스는 멈추지 않고 다음 작업을 진행한다. <br />
|
||||
> 비동기 Receive : 메시지를 받으면 해당 메시지가 유효한 내용인지 검사를 하고 처리 <br />
|
||||
|
||||
##### 버퍼 형태
|
||||
- Unbounded buffer : 메모리 버퍼의 크기에 제한이 없으며 소비자 프로세스는 새 자원이 만들어질 때까지 기다려야 하며 생산자 프로세스는 항상 새로운 자원을 만들 수 있다. 이때 생산자 역할의 프로세스는 공유한 메모리 자원의 크기를 지정하여 이를 함께 소비자 프로세스에 알려주어야 한다.
|
||||
- Bounded buffer : 메모리 버퍼 크기에 제한이 있으며 소비자 프로세스는 버퍼가 빈 상황이면 새로운 자원이 채워질 때까지 기다리며 생산자 프로세스는 버퍼가 꽉 차 있으면 공간이 남을 때까지 기다려야 한다.
|
||||
|
||||
#### File 사용
|
||||
텍스트 파일txt(혹은 다른 포멧의 파일)을 통해 데이터를 주고 받는 것도 IPC 기법 중 하나이다. <br />
|
||||
|
||||
물론 이 방식은 문제가 많다. 이 방식은 실시간으로 직접 원하는 프로세스에 데이터 전달하는게 어렵기 때문이다. <br />
|
||||
디스크에서 데이터 파일을 읽고, 프로세스에 적재load되는 과정에서 컨텍스트 스위칭Context-switching, 인터럽트Interrupt 등 여러 일을 처리해야 하기 때문이다. <br />
|
||||
|
||||
#### 파이프(Pipe)
|
||||
단방향 통신, 즉 부모 프로세스 → 자식 프로세스에게 일방적으로 통신하는 기법으로, fork()를 통해 자식 프로세스를 만들고 나서 부모의 데이터를 자식에게 보낸다.
|
||||
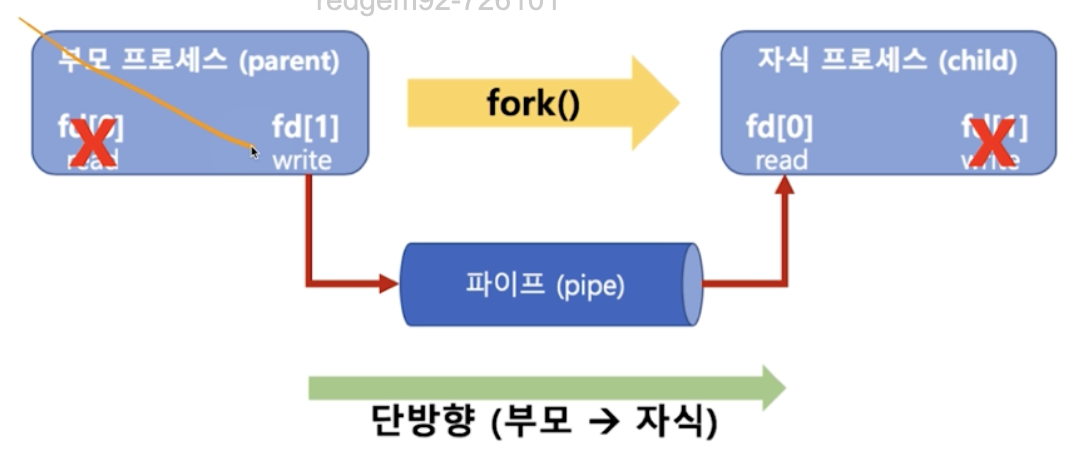
|
||||
|
||||
#### 소켓(Socket)
|
||||
많이 쓰이는 기법이자, 본래 목적이 IPC로 활용하기 위한 것은 아니지만, 충분히 활용이 가능하다. <br />
|
||||
|
||||
본래 소켓은 네트워크 통신을 위한 기술이다. 기본적으로 클라이언트와 서버 등 두 개의 다른 컴퓨터 간의 네트워크 기반 통신을 위한 기술로, 네트워크 디바이스를 사용할 수 있는 시스템 콜이기도 하다. <br />
|
||||
소켓은 이렇게 클라이언트와 서버 뿐만 아니라, 하나의 컴퓨터 안에서 두 개의 프로세스 간의 통신 기법으로 활용하는 경우도 더러 있다. <br />
|
||||
|
||||
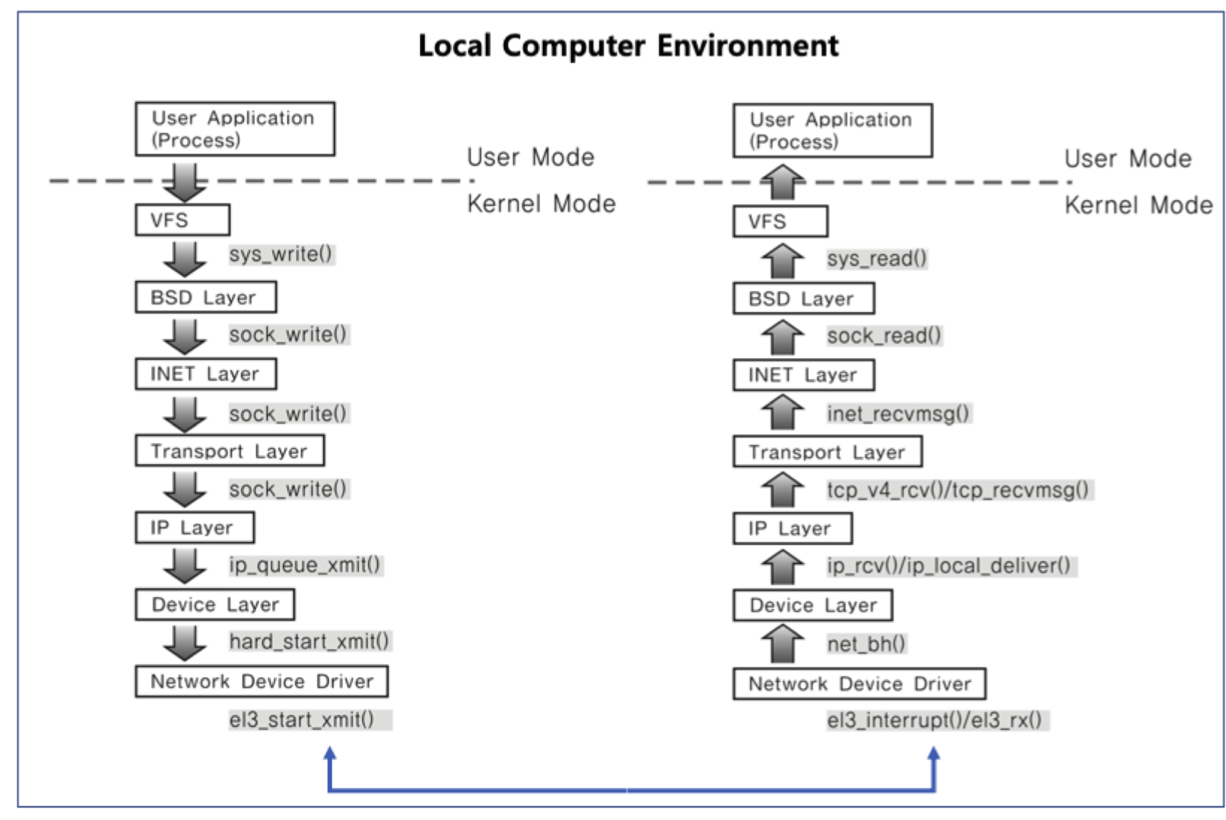
|
||||
|
||||
소켓을 사용하면 로컬 컴퓨터간의 통신 시 이렇게 계층을 타고 내려가면서 송신을 하고, 아래 계층부터 위로 올라가서 대상 프로세스가 수신을 하는 방식을 취하게 된다. <br />
|
||||
|
||||
---
|
||||
|
||||
## Thread 란?
|
||||
사실 프로세스가 단일의 실행 쓰레드를 실행하는 프로그램이다. 진짜로 일하는 것은 쓰레드라고 보면 된다.
|
||||
|
||||
|
||||
### Multi Thread
|
||||
하나의 프로세스에 여러 스레드로 자원을 공유하며 작업을 나누어 수행하는 것이다. <br />
|
||||

|
||||
|
||||
#### 장점
|
||||
- 시스템 자원소모 감소 (자원의 효율성 증대)
|
||||
- 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어 자원을 효율적으로 관리할 수 있다.
|
||||
- 시스템 처리율 향상 (처리비용 감소)
|
||||
- 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어든다.
|
||||
- 스레드 사이 작업량이 작아 Context Switching이 빠르다. (캐시 메모리를 비울 필요가 없다.)
|
||||
- 간단한 통신 방법으로 프로그램 응답시간 단축
|
||||
- 스레드는 프로세스 내 스택영역을 제외한 메모리 영역을 공유하기에 통신 비용이 적다.
|
||||
- 힙 영역을 공유하므로 데이터를 주고 받을 수 있다.
|
||||
|
||||
#### 문제점
|
||||
- 자원을 공유하기에 동기화 문제가 발생할 수 있다. (병목현상, 데드락 등)
|
||||
- 주의 깊은 설계가 필요하고 디버깅이 어렵다. (불필요 부분까지 동기화하면, 대기시간으로 인해 성능저하 발생)
|
||||
- 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받는다.
|
||||
- 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
|
||||
|
||||
---
|
||||
|
||||
## Process와 Thread의 차이
|
||||
- 프로세스는 현재 실행되고 있는 프로그램으로 메모리에 올라와서 독립적인 메모리 공간을 가진다.
|
||||
- 쓰레드는 프로세스 내에서 실행되는 흐름으로 프로세스 자원을 공유한다.
|
||||
|
||||
### 멀티 스레드 vs 멀티 프로세스
|
||||
- 멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고 Context Switching이 빠른 장점이 있지만, 동기화 문제와 하나의 스레드 장애로 전체 스레드가 종료 될 위험을 갖고 있다.
|
||||
- 멀티 프로세스는 하나의 프로세스가 죽더라도 다른 프로세스에 영향을 주지 않아 안정성이 높지만, 멀티 스레드보다 많은 메모리공간과 CPU 시간을 차지하는 단점이 있다.
|
||||
- 두 방법은 동시에 여러 작업을 수행하는 점에서 동일하지만, 각각의 장단이 있으므로 적용하는 시스템에 따라 적합한 동작 방식을 선택하고 적용해야 한다.
|
||||
|
||||
### 왜 멀티 스레드로 나눠가며 할까?
|
||||
- 운영체제가 시스템 자원을 효율적으로 관리하기 위해 스레드를 사용한다.
|
||||
- 멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
|
||||
- 또한, 프로세스 간의 통신보다 스레드 간의 통신 비용이 적으므로 작업들 간 통신의 부담이 줄어든다. (처리비용 감소. 프로세스는 독립구조이기 때문)
|
||||
|
||||
#### 그렇다면 무조건 멀티 스레드가 좋은가?
|
||||
스레드를 활용하면 자원의 효율성이 증가하기도 하지만, 스레드 간의 자원 공유는 전역 변수를 이용하므로 동기화 문제가 발생 할 수 있으므로 프로그래머의 주의가 필요하다. <br />
|
||||
|
||||
---
|
||||
|
||||
## 좀비 & 고아 프로세스
|
||||
### 좀비 프로세스
|
||||
자식 프로세스가 부모 프로세스보다 먼저 죽는 경우 부모 프로세스가 종료 상태를 회수하기 위해 커널이 자식 프로세스의 최소한의 정보(PID, 종료 상태 등, 리눅스의 경우 커널에서 사용하는 구조체)를 남겨 둔다. <br />
|
||||
부모 프로세스는 wait 함수를 호출하여 이 상태를 회수하면 남은 모든 정보가 제거되어 자식 프로세스는 완전히 소멸하게 된다. <br />
|
||||
|
||||
위와 같은 진행상황에서 부모 프로세스가 wait 함수를 호출하지 않아 최소한의 정보가 메모리에 남아 있는 경우를 좀비 프로세스라고 한다. <br />
|
||||
좀비 프로세스는 최소한의 정보만을 가지고 있어 큰 성능 저하를 야기하지 않지만, 운영체제는 한정된 PID를 가지고 있으므로 좀비 프로세스가 PID를 차지하며 다른 프로세스 실행을 방해하게 된다. <br />
|
||||
따라서 부모 프로세스는 좀비 프로세스 생성을 방지하기 위해 wait 함수를 호출하여 상태를 회수하여야 한다. <br />
|
||||
|
||||
> 커널 입장에서 좀비 프로세스는 성능 저하를 일으킨다고 볼 수 있다. <br />
|
||||
> 프로세스 스케줄링에 있어서 queue에 걸려있는 프로세스의 양이 증가하고 커널 구조체를 유지하기 위한 비용 또한 무시할 수 없다. <br />
|
||||
|
||||
좀비 프로세스를 다음과 같은 방법으로 관리할 수 있다. <br />
|
||||
- wait : 간단하게 부모 프로세스에서 wait 함수를 호출하여 좀비 프로세스를 없앨 수 있다.
|
||||
- signal, wait : wait 함수는 블록 모드로 동작하는 함수이므로 부모 프로세스는 wait함수를 호출한 즉시 동작을 멈추게 된다. 이를 방지하기 위해 시그널 도구를 활용하여 자식 프로세스가 종료될 경우 발생하는 SIGCHLD 시그널에 해당하는 핸들러를 만들고 해당 핸들러에서 wait 함수를 호출하면 된다.
|
||||
|
||||
|
||||
### 고아 프로세스(Orphan)
|
||||
부모 프로세스가 자식 프로세스보다 먼저 종료되는 경우 부모 프로세스가 없는 자식 프로세스를 말한다. <br />
|
||||
운영체제는 이러한 고아 프로세스를 허용하지 않으며 부모 프로세스가 먼저 종료되면 자식 프로세스의 새로운 부모 프로세스로 init(PID = 1)가 설정된다. <br />
|
||||
|
||||
init 프로세스는 자식 프로세스가 종료될 때까지 기다린 후 wait 함수를 호출하여 고아 프로세스의 종료 상태를 회수하여 좀비 프로세스가 되는 것을 방지한다. <br />
|
||||
고아 프로세스는 프로세스 자신이 시스템의 자원을 낭비할 수 있고, 시스템이 프로세스가 종료될 때까지 추적을 해야 하기 때문에 성능 저하의 원인이 된다. <br />
|
||||
|
||||
고아 프로세스는 init 프로세스가 관리를 해 주지만 성능 저하를 방지하기 위해 부모 프로세스가 종료되기 전에 모든 자식 프로세스를 wait 해 주는 것이 좋다. <br />
|
||||
51
src/content/blog/study/cs/2022-12-13-tcp-protocol.md
Normal file
51
src/content/blog/study/cs/2022-12-13-tcp-protocol.md
Normal file
@@ -0,0 +1,51 @@
|
||||
---
|
||||
title: TCP/IP
|
||||
date: 2022-12-13
|
||||
tags: cs, 공부
|
||||
excerpt: TCP(Transmission Control Protocol) / IP(Internet Protocol)
|
||||
---
|
||||
# TCP(Transmission Control Protocol) / IP(Internet Protocol)
|
||||
TCP 프로토콜을 자주 사용하면서도 CS 지식으로 연결되는 부분이 있기 때문에 정리하고자 한다. <br />
|
||||
|
||||
TCP/IP 를 사용하면서 해당 지식을 정확하게 알지 못하는 것은 어불성설이다. <br />
|
||||
따라서 상세히 알아보고 정리하고자 한다. <br />
|
||||
|
||||
## TCP/IP 란?
|
||||
전송 제어 프로토콜의 약자로, 인터넷 프로토콜 스위프트(IP)의 핵심 프로토콜 중 하나로, IP와 함께 TCP/IP라는 명칭으로 불린다. <br />
|
||||
|
||||
TCP/IP 를 사용하겠다는 것은 **IP** 주소 체계를 따르고 IP Routing을 이용해 목적지에 도달하며 **TCP** 의 특성을 활용해 송신자와 수신자의 논리적 연결을 생성하고 신뢰성을 유지할 수 있도록 하겠다는 의미이다. 즉, TCP/IP를 말한다는 것은 송신자가 수신자에게 IP 주소를 사용하여 데이터를 전달하고 그 데이터가 제대로 도달했는지, 너무 빠르진 않았는지, 받았다는 응답이 오는지에 대한 이야기를 하는 것이다. <br />
|
||||
|
||||
> Transport Layer(4 Layer)
|
||||
>> 송신자와 수신자의 논리적 연결을 담당하는 부분으로, 신뢰성 있는 연결을 유지할 수 있도록 도와줍니다.
|
||||
>> 즉 Endpoint(사용자) 간의 연결을 생성하고 데이터를 얼마나 보냈는지, 얼마나 받았는지, 제대로 받았는지 등을 확인합니다.
|
||||
>> TCP와 UDP가 대표적입니다.
|
||||
|
||||
> Network Layer(3 Layer)
|
||||
>> IP(Internet Protocol)이 활용되는 부분으로, 한 Endpoint가 다른 Endpoint로 가고자 하는 경우 경로와 목적지를 찾아줍니다.
|
||||
>> 이를 Routing이라고 하며 대역이 다른 IP들이 목적지를 향해 제대로 찾아갈 수 있도록 돕는 역할을 합니다,
|
||||
|
||||
> 출처 : OSI 7 Layer 쉽게 이해하기
|
||||
> [네트워크 엔지니어 환영의 AWS 기술블로그]
|
||||
|
||||
인터넷에서 무언가를 다운로드할 때 중간에 끊기거나 빠지는 부분 없이 완벽하게 받을 수 있는 이유도 TCP의 이러한 특성 덕분이다.
|
||||
그렇게 때문에 위에서 언급한 것처럼 HTTP, HTTPS, FTP, SMTP 등과 같이 데이터를 안정적으로 모두 보내는 것을 중요시하는 프로토콜들의 기반이 된다. <br />
|
||||
TCP를 기반으로 하는 프로토콜들은 TCP의 `3-way handshake`를 거친 후, 각자 프로토콜(Layer 7)에 기반한 교환 과정을 거친다는 의미이다. <br />
|
||||
|
||||
|
||||
|
||||
위 이미지는 TCP 기반의 프로토콜인 HTTPS의 `SSL handshake`를 도식화한 것이다. <br />
|
||||
TCP는 4 Layer이고 HTTPS는 7 Layer 이다. <br />
|
||||
|
||||
파란색 부분은 TCP의 `3-way handshake`이고, 노란색 부분은 HTTPS의 `SSL handshake`이다. <br />
|
||||
HTTPS는 TCP 기반이기 때문에 SSL handshake에 앞서 3-way handshake를 하는 것을 볼 수 있다. <br />
|
||||
|
||||
## TCP 개요
|
||||
TCP는 OSI 7 Layer 중에 4 계층에 해당한다. IP가 그저 목적지를 제대로 찾아가는 것에 중점을 둔다면, TCP는 통신하고자 하는 양쪽 단말(Endpoint)이 통신할 준비가 되었는지, 데이터가 제대로 전송되었는지, 데이터가 가는 도중 변질되지는 않았는지, 수신자가 얼마나 받았고 빠진 부분은 없었는 등을 점검한다. <br />
|
||||
이런 정보는 TCP Header에 담겨 있으며 SYN, ACK, FIN, RST, Source Port, Destination Port, Sequence Number, Window Size, Checksum 등과 같은 신뢰성 보장과 흐름 제어, 혼잡 제어에 관여할 수 있는 요소들을 포함하고 있다. <br />
|
||||
또한 IP Header와 TCP Header를 제외한 TCP가 실을 수 있는 데이터의 크기를 `세그먼트(Segment)`라고 부른다. <br />
|
||||
|
||||

|
||||
|
||||
<center>`TCP Header의 구조(출처: Wikipedia)`</center>
|
||||
|
||||
TCP는 IP의 정보들뿐만 아니라 Port를 이용하여 연결한다. 한 쪽 단말(Endpoint)에 도착한 데이터가 어느 입구(Port)로 들어가야 하는지 알아야 연결을 시도할 수 있기 때문이다. <br />
|
||||
17
src/content/blog/study/java/2022-04-03-java-start.md
Normal file
17
src/content/blog/study/java/2022-04-03-java-start.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
title: JAVA에 정리 스타트
|
||||
date: 2022-04-03
|
||||
tags: java, 공부
|
||||
excerpt: JAVA에 대한 정리와 공부
|
||||
---
|
||||
# JAVA에 대해서
|
||||
- JAVA에 대한 기본 정리와 공부 내용
|
||||
|
||||
### 작성되는 글
|
||||
이 디렉토리에는 자바에 대해서 공부하고 내용을 정리하면서 내가 이해한 내용을 작성하는 저장소이다.
|
||||
|
||||
자바는 내가 학부 생활을 시작하면서 지금까지 꾸준히 사용하고 있는 언어이다. 객체지향이라는 개념을 배우면서부터 자바의 매력에 빠졌고, 이것을 배우면서 공모전에도 나갈 수 있을 정도로 실력을 키워보기도하고 SPRING을 배우면서 자바의 다른 매력에 대해서도 공부해본 경험이 있다.
|
||||
|
||||
또한, 알고리즘을 자바로 하면서 지금까지 공부했던 내용을 잊기 전에 다시 한 번 정리해보자고 생각이 들어서 이 카테고리를 만들었다.
|
||||
|
||||
정리하면서 잊고 있었던 내용이나 부족했던 지식에 대해서 깨닫고 배우며 꽉 채울 수 있었으면 한다.
|
||||
66
src/content/blog/study/java/2022-04-04-java-memory.md
Normal file
66
src/content/blog/study/java/2022-04-04-java-memory.md
Normal file
@@ -0,0 +1,66 @@
|
||||
---
|
||||
title: JAVA의 메모리에 대해서
|
||||
date: 2022-04-04
|
||||
tags: java, 공부
|
||||
excerpt: JAVA의 메모리 구조에 대한 정리
|
||||
---
|
||||
# JAVA의 메모리? JAVA의 메모리 구조에 대한 이해
|
||||
- JAVA의 메모리 구조에 대해서 이해해보는 시간을 가져본다.
|
||||
|
||||
## JVM이란?
|
||||
JAVA의 메모리 구조에 대해서 설명하기 전에 JVM이 무엇인지 알아야 한다.
|
||||
JVM은 Java Virtual Machine의 약자로, 자바 가상 머신이라고 불린다.
|
||||
자바의 운영체제 사이에서 중개자 역할을 수행하며, 자바가 운영체제에 구애 받지 않고 프로그램을 실행할 수 있도록 도와주는 역할을 수행한다.
|
||||
또한, GC(Garbage Collector)를 사용한 메모리 관리도 자동으로 수행하며 다른 하드웨어와 다르게 레지스터 기반이 아닌 스택 기반으로 동작한다.
|
||||
|
||||
![image]()
|
||||
|
||||
먼저, 자바 컴파일러에 의해 자바 소스 파일은 바이트 코드로 변환된다. 그리고 이러한 바이트 코드를 JVM에서 읽어 들인 다음에 이것을 복잡한 과정을 거쳐서 어떤 운영체제든간에 프로그램을 실행할 수 있도록 만든다.
|
||||
|
||||
만약 자바 소스 파일은 리눅스에서 만들어졌고, 윈도우에서 이 파일을 실행하고 싶다면 윈도우용 JVM을 설치하기만 하면 되는 것이다! 여기서 JVM은 운영체제에 종송적이라는 특징을 알 수 있다.
|
||||
|
||||
---
|
||||
## JVM 메모리 구조
|
||||
이제 JVM이 무엇인지, 자바 프로그램의 실행 단계에 대해서 간략하게 알아보았으니 JVM의 구체적인 수행 과정에 대해서 정확히 어떤 구조를 가지고 있고 어떻게 동작을 하는지 알아보자.
|
||||
|
||||
아래는 자바 프로그램의 실행 단계로, JVM은 크게 4가지의 구조로 나누어 볼 수 있다.
|
||||
- Garbage Collector
|
||||
- Execution Engine
|
||||
- Class Loader
|
||||
- Runtime Data Area
|
||||
|
||||
![image]()
|
||||
|
||||
다시 한 번 언급하자면, 자바 소스 파일은 자바 컴파일러에 의해서 바이트 코드 형태인 클래스 파일이 된다. 그리고 이 클래스 파일은 클래스 로더가 읽어들이면서 JVM이 수행된다.
|
||||
|
||||
### Garbage Collector
|
||||
Garbage Collector(GC)는 힙(heap) 메모리 영역에 생성된 객체들 중에서 참조되지 않은 객체들을 탐색후 제거하는 역할을 한다. 이때, GC가 역할을 하는 시간은 언제인지 정확히 알 수 없다.
|
||||
|
||||
### Execution Engine
|
||||
클래스 로더를 통해 JVM 내의 Runtime Data Area에 배치된 바이트 코드들을 명령어 단위로 읽어서 실행한다. 최초 JVM이 나왔을 당시에는 인터프리터 방식이라고 하는데 속도가 느리다는 단점이 있었기 때문에 JIT 컴파일러 방식을 통해 이 점이 보완되었다.
|
||||
JIT는 바이트 코드를 어셈블러 같은 네이티브 코드로 바꿈으로써 실행이 빠르지만 역시 변환하는데 비용이 발생했다. 이 같은 이유로 JVM은 모든 코드를 JIT 컴파일러 방식으로 실행하지 않고, 인터프리터 방식을 사용하다가 일정한 기준이 넘어가면 JIT 컴파일러 방식으로 실행한다.
|
||||
|
||||
### Class Loader
|
||||
JVM 내로 클래스 파일을 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈이다. 런타임 시에 동적으로 클래스를 로드한다.
|
||||
|
||||
### Runtime Data Area
|
||||
JVM의 메모리 영역으로 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역이다.
|
||||
이 영역은 크게 아래와 같이 나눌 수 있다.
|
||||
- Method Area
|
||||
- 모든 쓰레드가 공유하는 메모리 영역. 메소드 영역은 클래스, 인터페이스, 메소드, 필드, Static 변수 등의 바이트 코드를 보관한다.
|
||||
- Heap Area
|
||||
- 모든 쓰레드가 공유하며, new 키워드로 생성된 객체와 배열이 생성되는 영역이다.
|
||||
- 또한, 메소드 영역에 로드된 클래스만 생성이 가능하고 Garbage Collector가 참조되지 않는 메모리를 확인하고 제거하는 영역이다.
|
||||
- Stack Area
|
||||
- 메서드 호출 시마다 각각의 스택 프레임(그 메서드만을 위한 공간)을 생성한다.
|
||||
- 메서드 안에서 사용되는 값들을 저장하고, 호출된 메서드의 매개변수, 지역변수, 리턴 값 및 연산 시 일어나는 값들을 임시로 저장한다.
|
||||
- 메서드의 수행이 끝나면 프레임별로 삭제한다.
|
||||
- PC Register
|
||||
- 쓰레드가 시작될 때 생성되며, 생성될 때마다 생성되는 공간으로 쓰레드마다 하나씩 존재한다.
|
||||
- 쓰레드가 어떤 부분을 무슨 명령으로 실행해야할 지에 대한 기록을 하는 부분으로 현재 수행중인 JVM 명령의 주소를 갖는다.
|
||||
- Native Method Stack
|
||||
- 자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역이다.
|
||||
|
||||
|
||||
---
|
||||
|
||||
339
src/content/blog/study/markdown/2022-04-05-markdown-emoji.md
Normal file
339
src/content/blog/study/markdown/2022-04-05-markdown-emoji.md
Normal file
@@ -0,0 +1,339 @@
|
||||
---
|
||||
title: Markdown 이모지
|
||||
date: 2022-04-05
|
||||
tags: markdown, 공부
|
||||
excerpt: Markdown 이모지
|
||||
---
|
||||
# Emoji 이모티콘
|
||||
- 마크다운을 이용해 이모티콘을 표현 가능하다.
|
||||
- 깃허브도 문제없이 적용 가능하다.
|
||||
- 마크다운 문법에 :: 사이에 **이모티콘명**을 넣으면 자동으로 인식된다. :rocket:
|
||||
|
||||
```markdown
|
||||
GitHub supports emoji!
|
||||
|
||||
# :+1:
|
||||
|
||||
## :sparkles:
|
||||
|
||||
* :camel:
|
||||
|
||||
1. :tada:
|
||||
|
||||
:rocket: :metal:
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 마크다운 이모지 종류
|
||||
## [People]
|
||||
|
||||
| 1 | 2 | 3 |
|
||||
| :---: | :---: | :---: |
|
||||
| :bowtie: <code>:bowtie:</code> | 😄 <code>:smile:</code> | 😆 <code>:laughing:</code> |
|
||||
| 😊 <code>:blush:</code> | 😃 <code>:smiley:</code> | ☺️ <code>:relaxed:</code> |
|
||||
| 😏 <code>:smirk:</code> | 😍 <code>:heart_eyes:</code> | 😘 <code>:kissing_heart:</code> |
|
||||
| 😚 <code>:kissing_closed_eyes:</code> | 😳 <code>:flushed:</code> | 😌 <code>:relieved:</code> |
|
||||
| 😆 <code>:satisfied:</code> | 😁 <code>:grin:</code> | 😉 <code>:wink:</code> |
|
||||
| 😜 <code>:stuck_out_tongue_winking_eye:</code> | 😝 <code>:stuck_out_tongue_closed_eyes:</code> | 😀 <code>:grinning:</code> |
|
||||
| 😗 <code>:kissing:</code> | 😙 <code>:kissing_smiling_eyes:</code> | 😛 <code>:stuck_out_tongue:</code> |
|
||||
| 😴 <code>:sleeping:</code> | 😟 <code>:worried:</code> | 😦 <code>:frowning:</code> |
|
||||
| 😧 <code>:anguished:</code> | 😮 <code>:open_mouth:</code> | 😬 <code>:grimacing:</code> |
|
||||
| 😕 <code>:confused:</code> | 😯 <code>:hushed:</code> | 😑 <code>:expressionless:</code> |
|
||||
| 😒 <code>:unamused:</code> | 😅 <code>:sweat_smile:</code> | 😓 <code>:sweat:</code> |
|
||||
| 😥 <code>:disappointed_relieved:</code> | 😩 <code>:weary:</code> | 😔 <code>:pensive:</code> |
|
||||
| 😞 <code>:disappointed:</code> | 😖 <code>:confounded:</code> | 😨 <code>:fearful:</code> |
|
||||
| 😰 <code>:cold_sweat:</code> | 😣 <code>:persevere:</code> | 😢 <code>:cry:</code> |
|
||||
| 😭 <code>:sob:</code> | 😂 <code>:joy:</code> | 😲 <code>:astonished:</code> |
|
||||
| 😱 <code>:scream:</code> | :neckbeard: <code>:neckbeard:</code> | 😫 <code>:tired_face:</code> |
|
||||
| 😠 <code>:angry:</code> | 😡 <code>:rage:</code> | 😤 <code>:triumph:</code> |
|
||||
| 😪 <code>:sleepy:</code> | 😋 <code>:yum:</code> | 😷 <code>:mask:</code> |
|
||||
| 😎 <code>:sunglasses:</code> | 😵 <code>:dizzy_face:</code> | 👿 <code>:imp:</code> |
|
||||
| 😈 <code>:smiling_imp:</code> | 😐 <code>:neutral_face:</code> | 😶 <code>:no_mouth:</code> |
|
||||
| 😇 <code>:innocent:</code> | 👽 <code>:alien:</code> | 💛 <code>:yellow_heart:</code> |
|
||||
| 💙 <code>:blue_heart:</code> | 💜 <code>:purple_heart:</code> | ❤️ <code>:heart:</code> |
|
||||
| 💚 <code>:green_heart:</code> | 💔 <code>:broken_heart:</code> | 💓 <code>:heartbeat:</code> |
|
||||
| 💗 <code>:heartpulse:</code> | 💕 <code>:two_hearts:</code> | 💞 <code>:revolving_hearts:</code> |
|
||||
| 💘 <code>:cupid:</code> | 💖 <code>:sparkling_heart:</code> | ✨ <code>:sparkles:</code> |
|
||||
| ⭐️ <code>:star:</code> | 🌟 <code>:star2:</code> | 💫 <code>:dizzy:</code> |
|
||||
| 💥 <code>:boom:</code> | 💥 <code>:collision:</code> | 💢 <code>:anger:</code> |
|
||||
| ❗️ <code>:exclamation:</code> | ❓ <code>:question:</code> | ❕ <code>:grey_exclamation:</code> |
|
||||
| ❔ <code>:grey_question:</code> | 💤 <code>:zzz:</code> | 💨 <code>:dash:</code> |
|
||||
| 💦 <code>:sweat_drops:</code> | 🎶 <code>:notes:</code> | 🎵 <code>:musical_note:</code> |
|
||||
| 🔥 <code>:fire:</code> | 💩 <code>:hankey:</code> | 💩 <code>:poop:</code> |
|
||||
| 💩 <code>:shit:</code> | 👍 <code>:+1:</code> | 👍 <code>:thumbsup:</code> |
|
||||
| 👎 <code>:-1:</code> | 👎 <code>:thumbsdown:</code> | 👌 <code>:ok_hand:</code> |
|
||||
| 👊 <code>:punch:</code> | 👊 <code>:facepunch:</code> | ✊ <code>:fist:</code> |
|
||||
| ✌️ <code>:v:</code> | 👋 <code>:wave:</code> | ✋ <code>:hand:</code> |
|
||||
| ✋ <code>:raised_hand:</code> | 👐 <code>:open_hands:</code> | ☝️ <code>:point_up:</code> |
|
||||
| 👇 <code>:point_down:</code> | 👈 <code>:point_left:</code> | 👉 <code>:point_right:</code> |
|
||||
| 🙌 <code>:raised_hands:</code> | 🙏 <code>:pray:</code> | 👆 <code>:point_up_2:</code> |
|
||||
| 👏 <code>:clap:</code> | 💪 <code>:muscle:</code> | 🤘 <code>:metal:</code> |
|
||||
| 🖕 <code>:fu:</code> | 🚶 <code>:walking:</code> | 🏃 <code>:runner:</code> |
|
||||
| 🏃 <code>:running:</code> | 👫 <code>:couple:</code> | 👪 <code>:family:</code> |
|
||||
| 👬 <code>:two_men_holding_hands:</code> | 👭 <code>:two_women_holding_hands:</code> | 💃 <code>:dancer:</code> |
|
||||
| 👯 <code>:dancers:</code> | 🙆 <code>:ok_woman:</code> | 🙅 <code>:no_good:</code> |
|
||||
| 💁 <code>:information_desk_person:</code> | 🙋 <code>:raising_hand:</code> | 👰 <code>:bride_with_veil:</code> |
|
||||
| 🙎 <code>:person_with_pouting_face:</code> | 🙍 <code>:person_frowning:</code> | 🙇 <code>:bow:</code> |
|
||||
| :couplekiss: <code>:couplekiss:</code> | 💑 <code>:couple_with_heart:</code> | 💆 <code>:massage:</code> |
|
||||
| 💇 <code>:haircut:</code> | 💅 <code>:nail_care:</code> | 👦 <code>:boy:</code> |
|
||||
| 👧 <code>:girl:</code> | 👩 <code>:woman:</code> | 👨 <code>:man:</code> |
|
||||
| 👶 <code>:baby:</code> | 👵 <code>:older_woman:</code> | 👴 <code>:older_man:</code> |
|
||||
| 👱 <code>:person_with_blond_hair:</code> | 👲 <code>:man_with_gua_pi_mao:</code> | 👳 <code>:man_with_turban:</code> |
|
||||
| 👷 <code>:construction_worker:</code> | 👮 <code>:cop:</code> | 👼 <code>:angel:</code> |
|
||||
| 👸 <code>:princess:</code> | 😺 <code>:smiley_cat:</code> | 😸 <code>:smile_cat:</code> |
|
||||
| 😻 <code>:heart_eyes_cat:</code> | 😽 <code>:kissing_cat:</code> | 😼 <code>:smirk_cat:</code> |
|
||||
| 🙀 <code>:scream_cat:</code> | 😿 <code>:crying_cat_face:</code> | 😹 <code>:joy_cat:</code> |
|
||||
| 😾 <code>:pouting_cat:</code> | 👹 <code>:japanese_ogre:</code> | 👺 <code>:japanese_goblin:</code> |
|
||||
| 🙈 <code>:see_no_evil:</code> | 🙉 <code>:hear_no_evil:</code> | 🙊 <code>:speak_no_evil:</code> |
|
||||
| 💂 <code>:guardsman:</code> | 💀 <code>:skull:</code> | 🐾 <code>:feet:</code> |
|
||||
| 👄 <code>:lips:</code> | 💋 <code>:kiss:</code> | 💧 <code>:droplet:</code> |
|
||||
| 👂 <code>:ear:</code> | 👀 <code>:eyes:</code> | 👃 <code>:nose:</code> |
|
||||
| 👅 <code>:tongue:</code> | 💌 <code>:love_letter:</code> | 👤 <code>:bust_in_silhouette:</code> |
|
||||
| 👥 <code>:busts_in_silhouette:</code> | 💬 <code>:speech_balloon:</code> | 💭 <code>:thought_balloon:</code> |
|
||||
| :feelsgood: <code>:feelsgood:</code> | :finnadie: <code>:finnadie:</code> | :goberserk: <code>:goberserk:</code> |
|
||||
| :godmode: <code>:godmode:</code> | :hurtrealbad: <code>:hurtrealbad:</code> | :rage1: <code>:rage1:</code> |
|
||||
| :rage2: <code>:rage2:</code> | :rage3: <code>:rage3:</code> | :rage4: <code>:rage4:</code> |
|
||||
| :suspect: <code>:suspect:</code> | :trollface: <code>:trollface:</code> |
|
||||
|
||||
|
||||
## [Nature]
|
||||
☀️ :sunny: ☔️ :umbrella: ☁️ :cloud:
|
||||
❄️ :snowflake: ⛄️ :snowman: ⚡️ :zap:
|
||||
🌀 :cyclone: 🌁 :foggy: 🌊 :ocean:
|
||||
🐱 :cat: 🐶 :dog: 🐭 :mouse:
|
||||
🐹 :hamster: 🐰 :rabbit: 🐺 :wolf:
|
||||
🐸 :frog: 🐯 :tiger: 🐨 :koala:
|
||||
🐻 :bear: 🐷 :pig: 🐽 :pig_nose:
|
||||
🐮 :cow: 🐗 :boar: 🐵 :monkey_face:
|
||||
🐒 :monkey: 🐴 :horse: 🐎 :racehorse:
|
||||
🐫 :camel: 🐑 :sheep: 🐘 :elephant:
|
||||
🐼 :panda_face: 🐍 :snake: 🐦 :bird:
|
||||
🐤 :baby_chick: 🐥 :hatched_chick: 🐣 :hatching_chick:
|
||||
🐔 :chicken: 🐧 :penguin: 🐢 :turtle:
|
||||
🐛 :bug: 🐝 :honeybee: 🐜 :ant:
|
||||
🐞 :beetle: 🐌 :snail: 🐙 :octopus:
|
||||
🐠 :tropical_fish: 🐟 :fish: 🐳 :whale:
|
||||
🐋 :whale2: 🐬 :dolphin: 🐄 :cow2:
|
||||
🐏 :ram: 🐀 :rat: 🐃 :water_buffalo:
|
||||
🐅 :tiger2: 🐇 :rabbit2: 🐉 :dragon:
|
||||
🐐 :goat: 🐓 :rooster: 🐕 :dog2:
|
||||
🐖 :pig2: 🐁 :mouse2: 🐂 :ox:
|
||||
🐲 :dragon_face: 🐡 :blowfish: 🐊 :crocodile:
|
||||
🐪 :dromedary_camel: 🐆 :leopard: 🐈 :cat2:
|
||||
🐩 :poodle: 🐾 :paw_prints: 💐 :bouquet:
|
||||
🌸 :cherry_blossom: 🌷 :tulip: 🍀 :four_leaf_clover:
|
||||
🌹 :rose: 🌻 :sunflower: 🌺 :hibiscus:
|
||||
🍁 :maple_leaf: 🍃 :leaves: 🍂 :fallen_leaf:
|
||||
🌿 :herb: 🍄 :mushroom: 🌵 :cactus:
|
||||
🌴 :palm_tree: 🌲 :evergreen_tree: 🌳 :deciduous_tree:
|
||||
🌰 :chestnut: 🌱 :seedling: 🌼 :blossom:
|
||||
🌾 :ear_of_rice: 🐚 :shell: 🌐 :globe_with_meridians:
|
||||
🌞 :sun_with_face: 🌝 :full_moon_with_face: 🌚 :new_moon_with_face:
|
||||
🌑 :new_moon: 🌒 :waxing_crescent_moon: 🌓 :first_quarter_moon:
|
||||
🌔 :waxing_gibbous_moon: 🌕 :full_moon: 🌖 :waning_gibbous_moon:
|
||||
🌗 :last_quarter_moon: 🌘 :waning_crescent_moon: 🌜 :last_quarter_moon_with_face:
|
||||
🌛 :first_quarter_moon_with_face: 🌔 :moon: 🌍 :earth_africa:
|
||||
🌎 :earth_americas: 🌏 :earth_asia: 🌋 :volcano:
|
||||
🌌 :milky_way: ⛅️ :partly_sunny: :octocat: :octocat:
|
||||
:shipit: :squirrel:
|
||||
|
||||
|
||||
## [Objects]
|
||||
🎍 :bamboo: 💝 :gift_heart: 🎎 :dolls:
|
||||
🎒 :school_satchel: 🎓 :mortar_board: 🎏 :flags:
|
||||
🎆 :fireworks: 🎇 :sparkler: 🎐 :wind_chime:
|
||||
🎑 :rice_scene: 🎃 :jack_o_lantern: 👻 :ghost:
|
||||
🎅 :santa: 🎄 :christmas_tree: 🎁 :gift:
|
||||
🔔 :bell: 🔕 :no_bell: 🎋 :tanabata_tree:
|
||||
🎉 :tada: 🎊 :confetti_ball: 🎈 :balloon:
|
||||
🔮 :crystal_ball: 💿 :cd: 📀 :dvd:
|
||||
💾 :floppy_disk: 📷 :camera: 📹 :video_camera:
|
||||
🎥 :movie_camera: 💻 :computer: 📺 :tv:
|
||||
📱 :iphone: ☎️ :phone: ☎️ :telephone:
|
||||
📞 :telephone_receiver: 📟 :pager: 📠 :fax:
|
||||
💽 :minidisc: 📼 :vhs: 🔉 :sound:
|
||||
🔈 :speaker: 🔇 :mute: 📢 :loudspeaker:
|
||||
📣 :mega: ⌛️ :hourglass: ⏳ :hourglass_flowing_sand:
|
||||
⏰ :alarm_clock: ⌚️ :watch: 📻 :radio:
|
||||
📡 :satellite: ➿ :loop: 🔍 :mag:
|
||||
🔎 :mag_right: 🔓 :unlock: 🔒 :lock:
|
||||
🔏 :lock_with_ink_pen: 🔐 :closed_lock_with_key: 🔑 :key:
|
||||
💡 :bulb: 🔦 :flashlight: 🔆 :high_brightness:
|
||||
🔅 :low_brightness: 🔌 :electric_plug: 🔋 :battery:
|
||||
📲 :calling: ✉️ :email: 📫 :mailbox:
|
||||
📮 :postbox: 🛀 :bath: 🛁 :bathtub:
|
||||
🚿 :shower: 🚽 :toilet: 🔧 :wrench:
|
||||
🔩 :nut_and_bolt: 🔨 :hammer: 💺 :seat:
|
||||
💰 :moneybag: 💴 :yen: 💵 :dollar:
|
||||
💷 :pound: 💶 :euro: 💳 :credit_card:
|
||||
💸 :money_with_wings: 📧 :e-mail: 📥 :inbox_tray:
|
||||
📤 :outbox_tray: ✉️ :envelope: 📨 :incoming_envelope:
|
||||
📯 :postal_horn: 📪 :mailbox_closed: 📬 :mailbox_with_mail:
|
||||
📭 :mailbox_with_no_mail: 🚪 :door: 🚬 :smoking:
|
||||
💣 :bomb: 🔫 :gun: 🔪 :hocho:
|
||||
💊 :pill: 💉 :syringe: 📄 :page_facing_up:
|
||||
📃 :page_with_curl: 📑 :bookmark_tabs: 📊 :bar_chart:
|
||||
📈 :chart_with_upwards_trend: 📉 :chart_with_downwards_trend: 📜 :scroll:
|
||||
📋 :clipboard: 📆 :calendar: 📅 :date:
|
||||
📇 :card_index: 📁 :file_folder: 📂 :open_file_folder:
|
||||
✂️ :scissors: 📌 :pushpin: 📎 :paperclip:
|
||||
✒️ :black_nib: ✏️ :pencil2: 📏 :straight_ruler:
|
||||
📐 :triangular_ruler: 📕 :closed_book: 📗 :green_book:
|
||||
📘 :blue_book: 📙 :orange_book: 📓 :notebook:
|
||||
📔 :notebook_with_decorative_cover: 📒 :ledger: 📚 :books:
|
||||
🔖 :bookmark: 📛 :name_badge: 🔬 :microscope:
|
||||
🔭 :telescope: 📰 :newspaper: 🏈 :football:
|
||||
🏀 :basketball: ⚽️ :soccer: ⚾️ :baseball:
|
||||
🎾 :tennis: 🎱 :8ball: 🏉 :rugby_football:
|
||||
🎳 :bowling: ⛳️ :golf: 🚵 :mountain_bicyclist:
|
||||
🚴 :bicyclist: 🏇 :horse_racing: 🏂 :snowboarder:
|
||||
🏊 :swimmer: 🏄 :surfer: 🎿 :ski:
|
||||
♠️ :spades: ♥️ :hearts: ♣️ :clubs:
|
||||
♦️ :diamonds: 💎 :gem: 💍 :ring:
|
||||
🏆 :trophy: 🎼 :musical_score: 🎹 :musical_keyboard:
|
||||
🎻 :violin: 👾 :space_invader: 🎮 :video_game:
|
||||
🃏 :black_joker: 🎴 :flower_playing_cards: 🎲 :game_die:
|
||||
🎯 :dart: 🀄️ :mahjong: 🎬 :clapper:
|
||||
📝 :memo: 📝 :pencil: 📖 :book:
|
||||
🎨 :art: 🎤 :microphone: 🎧 :headphones:
|
||||
🎺 :trumpet: 🎷 :saxophone: 🎸 :guitar:
|
||||
👞 :shoe: 👡 :sandal: 👠 :high_heel:
|
||||
💄 :lipstick: 👢 :boot: 👕 :shirt:
|
||||
👕 :tshirt: 👔 :necktie: 👚 :womans_clothes:
|
||||
👗 :dress: 🎽 :running_shirt_with_sash: 👖 :jeans:
|
||||
👘 :kimono: 👙 :bikini: 🎀 :ribbon:
|
||||
🎩 :tophat: 👑 :crown: 👒 :womans_hat:
|
||||
👞 :mans_shoe: 🌂 :closed_umbrella: 💼 :briefcase:
|
||||
👜 :handbag: 👝 :pouch: 👛 :purse:
|
||||
👓 :eyeglasses: 🎣 :fishing_pole_and_fish: ☕️ :coffee:
|
||||
🍵 :tea: 🍶 :sake: 🍼 :baby_bottle:
|
||||
🍺 :beer: 🍻 :beers: 🍸 :cocktail:
|
||||
🍹 :tropical_drink: 🍷 :wine_glass: 🍴 :fork_and_knife:
|
||||
🍕 :pizza: 🍔 :hamburger: 🍟 :fries:
|
||||
🍗 :poultry_leg: 🍖 :meat_on_bone: 🍝 :spaghetti:
|
||||
🍛 :curry: 🍤 :fried_shrimp: 🍱 :bento:
|
||||
🍣 :sushi: 🍥 :fish_cake: 🍙 :rice_ball:
|
||||
🍘 :rice_cracker: 🍚 :rice: 🍜 :ramen:
|
||||
🍲 :stew: 🍢 :oden: 🍡 :dango:
|
||||
🥚 :egg: 🍞 :bread: 🍩 :doughnut:
|
||||
🍮 :custard: 🍦 :icecream: 🍨 :ice_cream:
|
||||
🍧 :shaved_ice: 🎂 :birthday: 🍰 :cake:
|
||||
🍪 :cookie: 🍫 :chocolate_bar: 🍬 :candy:
|
||||
🍭 :lollipop: 🍯 :honey_pot: 🍎 :apple:
|
||||
🍏 :green_apple: 🍊 :tangerine: 🍋 :lemon:
|
||||
🍒 :cherries: 🍇 :grapes: 🍉 :watermelon:
|
||||
🍓 :strawberry: 🍑 :peach: 🍈 :melon:
|
||||
🍌 :banana: 🍐 :pear: 🍍 :pineapple:
|
||||
🍠 :sweet_potato: 🍆 :eggplant: 🍅 :tomato:
|
||||
🌽 :corn:
|
||||
|
||||
|
||||
## [Places]
|
||||
🏠 :house: 🏡 :house_with_garden: 🏫 :school:
|
||||
🏢 :office: 🏣 :post_office: 🏥 :hospital:
|
||||
🏦 :bank: 🏪 :convenience_store: 🏩 :love_hotel:
|
||||
🏨 :hotel: 💒 :wedding: ⛪️ :church:
|
||||
🏬 :department_store: 🏤 :european_post_office: 🌇 :city_sunrise:
|
||||
🌆 :city_sunset: 🏯 :japanese_castle: 🏰 :european_castle:
|
||||
⛺️ :tent: 🏭 :factory: 🗼 :tokyo_tower:
|
||||
🗾 :japan: 🗻 :mount_fuji: 🌄 :sunrise_over_mountains:
|
||||
🌅 :sunrise: 🌠 :stars: 🗽 :statue_of_liberty:
|
||||
🌉 :bridge_at_night: 🎠 :carousel_horse: 🌈 :rainbow:
|
||||
🎡 :ferris_wheel: ⛲️ :fountain: 🎢 :roller_coaster:
|
||||
🚢 :ship: 🚤 :speedboat: ⛵️ :boat:
|
||||
⛵️ :sailboat: 🚣 :rowboat: ⚓️ :anchor:
|
||||
🚀 :rocket: ✈️ :airplane: 🚁 :helicopter:
|
||||
🚂 :steam_locomotive: 🚊 :tram: 🚞 :mountain_railway:
|
||||
🚲 :bike: 🚡 :aerial_tramway: 🚟 :suspension_railway:
|
||||
🚠 :mountain_cableway: 🚜 :tractor: 🚙 :blue_car:
|
||||
🚘 :oncoming_automobile: 🚗 :car: 🚗 :red_car:
|
||||
🚕 :taxi: 🚖 :oncoming_taxi: 🚛 :articulated_lorry:
|
||||
🚌 :bus: 🚍 :oncoming_bus: 🚨 :rotating_light:
|
||||
🚓 :police_car: 🚔 :oncoming_police_car: 🚒 :fire_engine:
|
||||
🚑 :ambulance: 🚐 :minibus: 🚚 :truck:
|
||||
🚋 :train: 🚉 :station: 🚆 :train2:
|
||||
🚅 :bullettrain_front: 🚄 :bullettrain_side: 🚈 :light_rail:
|
||||
🚝 :monorail: 🚃 :railway_car: 🚎 :trolleybus:
|
||||
🎫 :ticket: ⛽️ :fuelpump: 🚦 :vertical_traffic_light:
|
||||
🚥 :traffic_light: ⚠️ :warning: 🚧 :construction:
|
||||
🔰 :beginner: 🏧 :atm: 🎰 :slot_machine:
|
||||
🚏 :busstop: 💈 :barber: ♨️ :hotsprings:
|
||||
🏁 :checkered_flag: 🎌 :crossed_flags: 🏮 :izakaya_lantern:
|
||||
🗿 :moyai: 🎪 :circus_tent: 🎭 :performing_arts:
|
||||
📍 :round_pushpin: 🚩 :triangular_flag_on_post: 🇯🇵 :jp:
|
||||
🇰🇷 :kr: 🇨🇳 :cn: 🇺🇸 :us:
|
||||
🇫🇷 :fr: 🇪🇸 :es: 🇮🇹 :it:
|
||||
🇷🇺 :ru: 🇬🇧 :gb: 🇬🇧 :uk:
|
||||
🇩🇪 :de:
|
||||
|
||||
|
||||
## [Symbols]
|
||||
1️⃣ :one: 2️⃣ :two: 3️⃣ :three:
|
||||
4️⃣ :four: 5️⃣ :five: 6️⃣ :six:
|
||||
7️⃣ :seven: 8️⃣ :eight: 9️⃣ :nine:
|
||||
🔟 :keycap_ten: 🔢 :1234: 0️⃣ :zero:
|
||||
#️⃣ :hash: 🔣 :symbols: ◀️ :arrow_backward:
|
||||
⬇️ :arrow_down: ▶️ :arrow_forward: ⬅️ :arrow_left:
|
||||
🔠 :capital_abcd: 🔡 :abcd: 🔤 :abc:
|
||||
↙️ :arrow_lower_left: ↘️ :arrow_lower_right: ➡️ :arrow_right:
|
||||
⬆️ :arrow_up: ↖️ :arrow_upper_left: ↗️ :arrow_upper_right:
|
||||
⏬ :arrow_double_down: ⏫ :arrow_double_up: 🔽 :arrow_down_small:
|
||||
⤵️ :arrow_heading_down: ⤴️ :arrow_heading_up: ↩️ :leftwards_arrow_with_hook:
|
||||
↪️ :arrow_right_hook: ↔️ :left_right_arrow: ↕️ :arrow_up_down:
|
||||
🔼 :arrow_up_small: 🔃 :arrows_clockwise: 🔄 :arrows_counterclockwise:
|
||||
⏪ :rewind: ⏩ :fast_forward: ℹ️ :information_source:
|
||||
🆗 :ok: 🔀 :twisted_rightwards_arrows: 🔁 :repeat:
|
||||
🔂 :repeat_one: 🆕 :new: 🔝 :top:
|
||||
🆙 :up: 🆒 :cool: 🆓 :free:
|
||||
🆖 :ng: 🎦 :cinema: 🈁 :koko:
|
||||
📶 :signal_strength: 🈹 :u5272: 🈴 :u5408:
|
||||
🈺 :u55b6: 🈯️ :u6307: 🈷️ :u6708:
|
||||
🈶 :u6709: 🈵 :u6e80: 🈚️ :u7121:
|
||||
🈸 :u7533: 🈳 :u7a7a: 🈲 :u7981:
|
||||
🈂️ :sa: 🚻 :restroom: 🚹 :mens:
|
||||
🚺 :womens: 🚼 :baby_symbol: 🚭 :no_smoking:
|
||||
🅿️ :parking: ♿️ :wheelchair: 🚇 :metro:
|
||||
🛄 :baggage_claim: 🉑 :accept: 🚾 :wc:
|
||||
🚰 :potable_water: 🚮 :put_litter_in_its_place: ㊙️ :secret:
|
||||
㊗️ :congratulations: Ⓜ️ :m: 🛂 :passport_control:
|
||||
🛅 :left_luggage: 🛃 :customs: 🉐 :ideograph_advantage:
|
||||
🆑 :cl: 🆘 :sos: 🆔 :id:
|
||||
🚫 :no_entry_sign: 🔞 :underage: 📵 :no_mobile_phones:
|
||||
🚯 :do_not_litter: 🚱 :non-potable_water: 🚳 :no_bicycles:
|
||||
🚷 :no_pedestrians: 🚸 :children_crossing: ⛔️ :no_entry:
|
||||
✳️ :eight_spoked_asterisk: ✴️ :eight_pointed_black_star: 💟 :heart_decoration:
|
||||
🆚 :vs: 📳 :vibration_mode: 📴 :mobile_phone_off:
|
||||
💹 :chart: 💱 :currency_exchange: ♈️ :aries:
|
||||
♉️ :taurus: ♊️ :gemini: ♋️ :cancer:
|
||||
♌️ :leo: ♍️ :virgo: ♎️ :libra:
|
||||
♏️ :scorpius: ♐️ :sagittarius: ♑️ :capricorn:
|
||||
♒️ :aquarius: ♓️ :pisces: ⛎ :ophiuchus:
|
||||
🔯 :six_pointed_star: ❎ :negative_squared_cross_mark: 🅰️ :a:
|
||||
🅱️ :b: 🆎 :ab: 🅾️ :o2:
|
||||
💠 :diamond_shape_with_a_dot_inside: ♻️ :recycle: 🔚 :end:
|
||||
🔛 :on: 🔜 :soon: 🕐 :clock1:
|
||||
🕜 :clock130: 🕙 :clock10: 🕥 :clock1030:
|
||||
🕚 :clock11: 🕦 :clock1130: 🕛 :clock12:
|
||||
🕧 :clock1230: 🕑 :clock2: 🕝 :clock230:
|
||||
🕒 :clock3: 🕞 :clock330: 🕓 :clock4:
|
||||
🕟 :clock430: 🕔 :clock5: 🕠 :clock530:
|
||||
🕕 :clock6: 🕡 :clock630: 🕖 :clock7:
|
||||
🕢 :clock730: 🕗 :clock8: 🕣 :clock830:
|
||||
🕘 :clock9: 🕤 :clock930: 💲 :heavy_dollar_sign:
|
||||
©️ :copyright: ®️ :registered: ™️ :tm:
|
||||
❌ :x: ❗️ :heavy_exclamation_mark: ‼️ :bangbang:
|
||||
⁉️ :interrobang: ⭕️ :o: ✖️ :heavy_multiplication_x:
|
||||
➕ :heavy_plus_sign: ➖ :heavy_minus_sign: ➗ :heavy_division_sign:
|
||||
💮 :white_flower: 💯 :100: ✔️ :heavy_check_mark:
|
||||
☑️ :ballot_box_with_check: 🔘 :radio_button: 🔗 :link:
|
||||
➰ :curly_loop: 〰️ :wavy_dash: 〽️ :part_alternation_mark:
|
||||
🔱 :trident:
|
||||
✅ :white_check_mark: 🔲 :black_square_button: 🔳 :white_square_button:
|
||||
⚫️ :black_circle: ⚪️ :white_circle: 🔴 :red_circle:
|
||||
🔵 :large_blue_circle: 🔷 :large_blue_diamond: 🔶 :large_orange_diamond:
|
||||
🔹 :small_blue_diamond: 🔸 :small_orange_diamond: 🔺 :small_red_triangle:
|
||||
🔻 :small_red_triangle_down: :shipit: :shipit:
|
||||
|
||||
|
||||
출처: https://inpa.tistory.com/464 [👨💻 Dev Scroll]
|
||||
153
src/content/blog/study/markdown/2022-05-24-github-profile.md
Normal file
153
src/content/blog/study/markdown/2022-05-24-github-profile.md
Normal file
@@ -0,0 +1,153 @@
|
||||
---
|
||||
title: 눈을끄는 Github Profile 꾸미기
|
||||
date: 2022-05-24
|
||||
tags: markdown, 공부
|
||||
excerpt: Github profile 꾸미기
|
||||
---
|
||||
# Github profile 꾸미기
|
||||
- 깃허브에서 제공하는 나의 profile 꾸미기 기능을 이용해 나만의 독특한 profile을 만들 수 있다.
|
||||
- 유니크함을 더해주는 badge 등을 이용하여 눈에띄는 profile을 만들 수 있다.
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
# Git profile을 위한 repository 만들기
|
||||
|
||||

|
||||
|
||||
우선 깃허브 프로필을 설정하려면 본인의 ID와 일치하는 이름으로 레퍼지토리를 생성해야 한다.
|
||||
|
||||
나의 경우 github ID가 gahusb이니 gahusb으로 레포지토리를 만들어줬다.
|
||||
|
||||
일반적인 레퍼지토리 생성때와는 다르게 생성화면에서 고양이가 나타나며 말을 건다.
|
||||
|
||||
README.md 파일 생성하도록 체크하라는 내용이다. 바로 체크하고 레퍼지토리를 생성하자!
|
||||
|
||||
바로 이 레퍼지토리의 README.md 파일이 내 깃허브 프로필에 출력되는 것임을 알 수 있다.
|
||||
|
||||
# Read.me 꾸미기
|
||||
|
||||
## 헤더
|
||||
|
||||
우선 맨 위에 **Hello World**를 보여주는 헤더 부분을 추가 할 수 있다.
|
||||
|
||||
이 부분은 'capsule-render'라는 오픈API를 사용하였다.
|
||||
|
||||
[https://github.com/kyechan99/capsule-render](https://github.com/kyechan99/capsule-render)
|
||||
|
||||
이 오픈 소스는 awesome 하게도 크기, 모양, 문구 등을 자신의 취향에 맞게 선택하여 사용할 수 있고, 나의 프로필을 더욱 눈에 띄게 만들어줄 수 있다.
|
||||
|
||||
## 방문자 수
|
||||
|
||||
프로필인란것은 결국에 나에 대한 정보를 다른 사람에게 보여주기 위한 것이라고 생각한다.
|
||||
|
||||
때문에 얼마나 노출되었는지 판단할 수 있다면 좋다고 생각한다.
|
||||
|
||||
이것을 나타내주기 위해서 Hit라는 오픈 소스를 사용했다.
|
||||
|
||||
[https://hits.seeyoufarm.com/](https://hits.seeyoufarm.com/)
|
||||
|
||||

|
||||
|
||||
위의 사이트에서 나의 github 주소를 입력하고 OPTIONS를 통해 색상과 끝의 라운드 정도 등을 선택하고
|
||||
|
||||
아래부분에 MARKDOWN의 주소를 COPY하여 내 read.me의 원하는 위치에 넣으면 방문하는 수에 따라서 카운트가 증가한다.
|
||||
|
||||
## 나에 대한 상세 설명
|
||||
|
||||
위에 간단한 방문 인사말고 나에 대해서 좀더 재미있게 표현하기 위해서 코드로 나를 표현하는 부분을 넣어 볼 수 있다.
|
||||
|
||||
```
|
||||
(``` Grave + 언어)
|
||||
```javascript
|
||||
const jaeoh = {
|
||||
pronouns: "He" | "Him",
|
||||
code: ["Java", "C", "C++", "Javascript", "Python"],
|
||||
liveIn: Yeongdeungpo-gu, Seoul, Republic of Korea
|
||||
};
|
||||
```
|
||||
|
||||
위 코드처럼 내가 넣을 코드 스타일을 선택하여 나에 대한 정보를 입력해서 나를 소개하였다.
|
||||
|
||||
## 소셜 정보 & contact
|
||||
|
||||
나에게 연락 할 수 있는 Email이나 소셜 정보를 넣어주었다.
|
||||
|
||||
```
|
||||
[](https://github.com/gahusb)
|
||||
[](https://www.linkedin.com/in/jaeoh-park-gahusb/)
|
||||
[](https://www.instagram.com/gahusb/)
|
||||
```
|
||||
|
||||
위와 같이 나의 정보와 누가봐도 해당 소셜에 해당하는 아이콘으로 표시해줄 수 있다.
|
||||
|
||||
아이콘은 [여기](https://github.com/gahusb/gahusb/tree/main/icons)서 다운로드 받아서 나의 레포지토리에 넣고 사용할 수 있다.
|
||||
|
||||
## 기술 스택
|
||||
|
||||
뱃지(Badge)를 사용하여 나의 기술 스택을 이쁘게 표현할 수 있다.
|
||||
|
||||
[https://shields.io/](https://shields.io/)
|
||||
|
||||
위 shields라는 곳에서 내가 원하는 형태로 뱃지를 만들어서 사용할 수도 있고,
|
||||
|
||||
[https://simpleicons.org/](https://simpleicons.org/)
|
||||
|
||||
위 simpleicons라는 사이트에서 내가 원하는 기술 스택에 해당하는 아이콘을 받아서 뱃지로 만들어 사용할 수 있다.
|
||||
|
||||
```
|
||||

|
||||
```
|
||||
|
||||
예를 들어 JAVA의 경우 위 **Java-orange**라는 뱃지의 모양에 내가 원하는 뱃지의 이름을 입력하고, 스타일, 로고 등을 선택하여 사용할 수 있다.
|
||||
|
||||
이런 나만의 뱃지를 만들기 귀찮다면,
|
||||
|
||||
[https://cocoon1787.tistory.com/689](https://cocoon1787.tistory.com/689)
|
||||
|
||||
이런 뱃지들을 만들어서 공유하는 오픈 소스를 가져다가 사용할 수 있다.
|
||||
|
||||
나만의 기술 스택들을 좀 더 자유롭고 눈에 띄게 바꿔보자
|
||||
|
||||
## Github stat
|
||||
|
||||
내가 지금까지 commit한 횟수나 repositories에 있는 언어를 분석하여 어떤 언어를 가장 많이 사용했는지 표시할 수 있다.
|
||||
일종의 My github analytics 이라고 할까?
|
||||
|
||||
자신이 깃에서 어떤 활동을 하고 있는지 자세히 보여주는 지표이다.
|
||||
|
||||
```markdown
|
||||

|
||||
```
|
||||
**아이디**로 되어 있는 부분에 나의 github ID를 넣어서 사용할 수 있다.
|
||||
|
||||
나의 경우
|
||||
|
||||
```html
|
||||
<p>
|
||||
<a href="https://github.com/gahusb">
|
||||
<img src="https://github-readme-stats.vercel.app/api/top-langs/?username=gahusb&layout=compact&show_icons=true&show_owner=false&hide_title=false&theme=gruvbox" />
|
||||
</a>
|
||||
<a href="https://github.com/gahusb">
|
||||
<img src="https://github-readme-stats.vercel.app/api?username=gahusb&hide_title=false&show_icons=true&include_all_commits=false&theme=gruvbox" />
|
||||
</a>
|
||||
</p>
|
||||
```
|
||||
|
||||
위에 처럼 html 태그에 url을 넣어서 좀더 옵션을 제어하여 사용하였다.
|
||||
|
||||
나의 ID인 gahusb 부분을 지우고 자신의 github ID를 넣어서 사용하시면 됩니다.
|
||||
|
||||
# 더하기
|
||||
|
||||
중간중간 markdown에 나타나는 emoji의 경우 아래 글을 참고해서 사용하시면 됩니다.
|
||||
|
||||
[https://gahusb.github.io/devlog/markdown-emoji.html](https://gahusb.github.io/devlog/markdown-emoji.html)
|
||||
|
||||
또한 더 다양한 사람들의 github profile을 참고해서 나만의 프로필을 꾸미고 싶다면
|
||||
|
||||
[https://github.com/abhisheknaiidu/awesome-github-profile-readme](https://github.com/abhisheknaiidu/awesome-github-profile-readme
|
||||
)
|
||||
|
||||
위의 사이트에서 여러 사람들의 awesome한 read.me를 참고하여 나의 프로필에 적용해보자 😊
|
||||
216
src/content/blog/study/react/2022-06-07-web-reactjs.md
Normal file
216
src/content/blog/study/react/2022-06-07-web-reactjs.md
Normal file
@@ -0,0 +1,216 @@
|
||||
---
|
||||
title: ReactJS
|
||||
date: 2022-06-07
|
||||
tags: react, 공부, 개발
|
||||
excerpt: 리액트를 활용 공부
|
||||
---
|
||||
# 리액트를 활용하여 영화 웹 서비스 개발
|
||||
|
||||
## What ReactJS ?
|
||||
|
||||
|
||||
## ReacJS를 사용하는 이유
|
||||
- interactive(상호작용을 위해)
|
||||
|
||||
|
||||
## VanilliaJS vs ReactJS
|
||||
|
||||
VaniliaJS
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<body>
|
||||
<span>Total click: 0</span>
|
||||
<button id="btn">Click me</button>
|
||||
</body>
|
||||
<script>
|
||||
let counter = 0;
|
||||
const button = document.querySelector("btn");
|
||||
const span = document.querySelector("span");
|
||||
function handleClick() {
|
||||
counter += 1;
|
||||
span.innerText = `Total clicks: ${counter}`;
|
||||
}
|
||||
button.addEventListener("click", handleClick);
|
||||
</script>
|
||||
</html>
|
||||
```
|
||||
|
||||
ReactJS
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<body>
|
||||
<div id="root"></div>
|
||||
</body>
|
||||
<script src="https://unpkg.com/react@17/umd/react.development.js"></script>
|
||||
<script src="https://unpkg.com/react-dom@17/umd/react-dom.development.js"></script>
|
||||
<script>
|
||||
let counter = 0;
|
||||
const root = document.getElementById("root");
|
||||
const h3 = React.createElement(
|
||||
"h3",
|
||||
{
|
||||
id: "title",
|
||||
},
|
||||
`Total click: ${counter}`
|
||||
);
|
||||
const btn = React.createElement(
|
||||
"button",
|
||||
{
|
||||
onClick: () => counter += 1,
|
||||
},
|
||||
"Click me"
|
||||
);
|
||||
const container = React.createElement("div", null, [h3, btn]);
|
||||
ReactDOM.render(container, root);
|
||||
</script>
|
||||
</html>
|
||||
```
|
||||
|
||||
위에서 간단한 버튼을 삽입하여 카운트를 증가하는 작업을 하는 파일을 만들었다. <br />
|
||||
간단히 보더라도 body태그 안에 데이터를 넣을 태그를 선언해주고 **querySelector**에서 태그를 찾아서 넣고 Event Listener를 선언해서 연결해주고... <br />
|
||||
|
||||
위에처럼 간단하게 만든 버튼 클릭 시, 카운트 증가하는 경우에는 비슷해보일지 모르지만 저런 기능 하나하나가 모인다고 생각해보면 보기만해도 어질어질해진다...
|
||||
|
||||
그래서 ReactJS를 사용해서 상호작용해주는 멋진 프레임워크를 사용한다.
|
||||
|
||||
## Introducing JSX !
|
||||
```
|
||||
Babel compiles JSX down to React.createElement() calls.
|
||||
```
|
||||
위 문구에서 볼 수 있듯이 **reactjs.org**에 소개된 JSX의 첫 소개 문구이다. <br />
|
||||
JSX는 Javascript를 확장한 문법으로, createElement()를 선언하여 태그와 속성을 가져오는 부분을 더 심플하게 컴파일해주는 Babel의 기능이다.
|
||||
|
||||
```JSX
|
||||
const element = (
|
||||
<h1 className="greeting">
|
||||
Hello, world!
|
||||
</h1>
|
||||
);
|
||||
```
|
||||
|
||||
```javascript
|
||||
const element = React.createElement(
|
||||
'hi',
|
||||
{className: 'greeting'},
|
||||
'Hello, world!'
|
||||
);
|
||||
```
|
||||
|
||||
첫 번째 코드가 JSX를 사용한 코드이고, 아래가 그냥 JS에 createElement()를 사용해서 속성을 선언한 코드이다.
|
||||
|
||||
이를 반영해서 위의 간단한 카운트 코드를 변경해보았다.
|
||||
|
||||
```JSX
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<body>
|
||||
<div id="root"></div>
|
||||
</body>
|
||||
<script src="https://unpkg.com/react@17/umd/react.development.js"></script>
|
||||
<script src="https://unpkg.com/react-dom@17/umd/react-dom.development.js"></script>
|
||||
<script src="https://unpkg.com/@babel/standalone/babel.min.js"></script>
|
||||
<script type="text/babel">
|
||||
let counter = 0;
|
||||
const root = document.getElementById("root");
|
||||
const Title = (
|
||||
<h3 id="title">
|
||||
Total click: `${counter}`
|
||||
</h3>
|
||||
);
|
||||
const Button = (
|
||||
<button
|
||||
style={{
|
||||
backgroundColor: "tomato",
|
||||
}}
|
||||
onClick={() => counter += 1}
|
||||
>
|
||||
Click me
|
||||
</button>
|
||||
);
|
||||
const container = React.createElement("div", null, [Title, Button]);
|
||||
ReactDOM.render(container, root);
|
||||
</script>
|
||||
</html>
|
||||
```
|
||||
|
||||
위 코드에서처럼 JSX를 사용하기 위해서는 **Babel**을 import할 필요가 있다.<br />
|
||||
왜냐하면 브라우저는 JSX라는 형태를 인식하지 못하기 때문에 JSX를 브라우저가 알 수 있는 코드로 변형해주기 위해서이다.
|
||||
|
||||
그리고서 안을 보자면 일반적으로 알고 있는 HTML의 형태와 유사한 코드를 볼 수 있다.<br />
|
||||
각 태그가 있고, 그 태그 안에는 class, style등의 속성이나 event가 들어갈 수 있고, 모든 정보들을 알아보기 간편해졌다!<br />
|
||||
|
||||
|
||||
## Understanding State
|
||||
ReactJS에서 State란 무엇인가? <br />
|
||||
State는 데이터를 저장하는 장소이다.
|
||||
|
||||
아래 코드를 살펴보자
|
||||
|
||||
```html
|
||||
...
|
||||
<script type="text/babel">
|
||||
const root = document.getElementById("root");
|
||||
let counter = 0;
|
||||
function countUp () {
|
||||
counter += 1;
|
||||
render();
|
||||
}
|
||||
function render() {
|
||||
ReactDOM.render(<Container />, root);
|
||||
}
|
||||
function Container() {
|
||||
return (
|
||||
<div>
|
||||
<h3>Total click: {counter}</h3>
|
||||
<button onClick={countUp}>Click me</button>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
render();
|
||||
</script>
|
||||
</html>
|
||||
```
|
||||
|
||||
위의 코드를 보면 버튼을 클릭할 때마다 다시 render() 함수를 불러와 호출하는것을 볼 수 있다.<br />
|
||||
그러나 저 방식은 코드가 많아지거나 컨테이너의 포함 범위가 많아지게되면 rerender를 어느 시점에서 다시 해줘야 하는지 설계하기도 어렵고 나중에 유지보수도 힘들게 된다.
|
||||
|
||||
이것을 위해 useState()를 사용하여 데이터와 해당 데이터의 변화를 감지하여 해당 데이터 부분만 리렌더링 해줄 수 있다.
|
||||
|
||||
아래의 코드를 살펴보자
|
||||
|
||||
```html
|
||||
...
|
||||
<script type="text/babel">
|
||||
const root = document.getElementById("root");
|
||||
function App() {
|
||||
const [counter, setCounter] = React.useState(0);
|
||||
const onClick = () => {
|
||||
setCounter((current) => current + 1);
|
||||
}
|
||||
return (
|
||||
<div>
|
||||
<h3>Total click: {counter}</h3>
|
||||
<button onClick={onClick}>Click me</button>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
ReactDOM.render(<App />, root);
|
||||
</script>
|
||||
</html>
|
||||
```
|
||||
|
||||
간단하게 useState()를 통해 초기값 0을 가진 counter와 setCounter라는 데이터의 상태를 변화시켜주는 함수를 같이 선언할 수 있다.<br />
|
||||
그리고 버튼을 클릭할때마다 counter를 증가시켜주도록 하면, 위에서 rerender를 위해 다시 호출하여 리렌더링해주는 작업을 별도로 선언하지 않아도 해당 데이터 부분에 변화가 생기면 해당 데이터 부분만 리렌더링 된다!!<br />
|
||||
정말 멋진 기능이 아닐 수 없다!<br />
|
||||
|
||||
이 동작은 modifier라고 하는 setCounter라고 명명한 부분이 실행이되면 해당 컴포넌트(여기선 App)를 재실행하게 된다. <br />
|
||||
그래서 setCounter가 실행되는 부분부터 순차적으로 아래로 실행이되며, return()되는 부분이 재실행되고, 리렌더링이 되는것이다. <br />
|
||||
|
||||
바로 이 부분이 ReactJS의 기능의 가장 중점이되는 부분이다. 데이터가 바뀔때마다 컴포넌트를 리렌더링하고 UI를 refresh해준다. <br />
|
||||
|
||||
이는 vanillaJS처럼 HTML의 요소를 찾을 필요없고, 이벤트리스너를 더해줄 필요도, UI를 업데이트해줄 필요도 없도록 해주었다! <br />
|
||||
JSX를 통해 바로 HTML을 넣고, 곧바로 이벤트리스너를 더해주고, state가 변화하면 자동으로 리렌더링 되는 것이다!! So Cool ❗️❗️😆
|
||||
|
||||
|
||||
286
src/content/blog/study/spring/2022-11-01-jpa-lombok.md
Normal file
286
src/content/blog/study/spring/2022-11-01-jpa-lombok.md
Normal file
@@ -0,0 +1,286 @@
|
||||
---
|
||||
title: Spring 개념
|
||||
date: 2022-11-01
|
||||
tags: spring, 공부
|
||||
excerpt: Spring 개념 이해
|
||||
---
|
||||
# 스프링 프로젝트
|
||||
## JPA, 자바 지속성 API(JAVA Persistence API)
|
||||
자바 플랫폼 SE와 EE를 사용하는 응용프로그래메서 관계형 데이터베이스의 관리를 표현하는 Java API이다.
|
||||
이전에 SSAFY를 다니며 배운 경험은 있지만 다시 한 번 사용하면서 정리해보기로 한다.
|
||||
|
||||
## lombok
|
||||
getter, setter 등의 반복 메서드를 자동으로 연결하고 도구를 빌드하여 Java를 향상시키는 Java 라이브러리이다. <br />
|
||||
[lombok](https://projectslombok.org/)
|
||||
|
||||
## 1. Dependency 추가 (jpa, lombok, mariaDB)
|
||||
> Maven의 경우 pom.xml에 추가
|
||||
|
||||
```xml
|
||||
<!-- JPA -->
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-data-jpa</artifactId>
|
||||
</dependency>
|
||||
|
||||
<!-- lombok -->
|
||||
<dependency>
|
||||
<groupId>org.projectlombok</groupId>
|
||||
<artifactId>lombok</artifactId>
|
||||
<optional>true</optional>
|
||||
</dependency>
|
||||
|
||||
<!-- mariaDB -->
|
||||
<dependency>
|
||||
<groupId>org.mariadb.jdbc</groupId>
|
||||
<artifactId>mariadb-java-client</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
> gradle의 경우 build.gradle에 추가
|
||||
|
||||
```gradle
|
||||
dependencies {
|
||||
// JPA
|
||||
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
|
||||
// lombok
|
||||
implementation 'org.projectlombok:lombok'
|
||||
// mariaDB
|
||||
implementation 'org.mariadb.jdbc:mariadb-java-client'
|
||||
}
|
||||
```
|
||||
|
||||
여기서 의문점이 좀 들었다. <br />
|
||||
Maven과 Gradle의 차이점은 무엇일까? 바로 알아보자 <br />
|
||||
-> [Maven과 Gradle](https://gahusb.github.io/devlog/maven-gradle.html)
|
||||
|
||||
## 2. 데이터베이스 설정
|
||||
> application.properties
|
||||
|
||||
```java
|
||||
spring.datasource.driverClassName=org.mariadb.jdbc.Driver
|
||||
spring.datasource.url=jdbc:mariadb://IP:3306/databaseName
|
||||
spring.datasource.username=user
|
||||
spring.datasource.password=pwd
|
||||
```
|
||||
|
||||
> aplication.yml
|
||||
|
||||
```java
|
||||
spring:
|
||||
datasource:
|
||||
driverClassName: org.mariadb.jdbc.Driver
|
||||
url: jdbc:mariadb://IP:3306/databaseName
|
||||
username: user
|
||||
password: pwd
|
||||
```
|
||||
|
||||
## 3. 재사용될 컬럼을 추상 클래스로 작성
|
||||
> CommonVo.java
|
||||
|
||||
```java
|
||||
import java.time.LocalDateTime;
|
||||
import javax.persistence.Column;
|
||||
import javax.persistence.MappedSuperclass;
|
||||
import org.hibernate.annotations.CreationTimestamp;
|
||||
import lombok.Data;
|
||||
|
||||
// Getter, Setter Auto Create
|
||||
@Data
|
||||
// 공통 매핑 정보가 필요할 때, 부모 클래스에 선언하고 속성만 상속 받아서 사용하고 싶을 때 사용한다.
|
||||
@MappedSuperclass
|
||||
public abstract class CommonVo {
|
||||
|
||||
// register id
|
||||
private String regId;
|
||||
|
||||
// modify id
|
||||
private String modId;
|
||||
|
||||
// register Date time
|
||||
@CreationTimestamp
|
||||
/*
|
||||
* 보통 JPA는 SAVE시에 모든 칼럼을 INSERT한다.
|
||||
* 그럴 경우, NOT NULL로 설정된 칼럼은 기본값으로 삽입되는 것이 아닌 NULL로 삽입을 시도한다.
|
||||
* 이로 인해 에러가 발생하는데, 이럴 경우에 아예 쿼리에서 빼버려서 실행이 안되게 만들 수 있다.
|
||||
* 쿼리에서 제외된 칼럼은 DB에 지정된 default값으로 삽입이 된다.
|
||||
* 특정 칼럼을 제외하고 save하는 방법은 다음과 같다.
|
||||
* insertable = false, updatable = false
|
||||
*/
|
||||
@Column(updatable = false)
|
||||
private LocalDateTime regDtm;
|
||||
|
||||
// modify Date time
|
||||
@CreationTimestamp
|
||||
private LocalDateTime modDtm;
|
||||
}
|
||||
```
|
||||
|
||||
## 4. CommonVo를 상속받은 MemberVo 작성
|
||||
> MemberVo.java
|
||||
|
||||
```java
|
||||
import javax.persistence.Entity;
|
||||
import javax.persistence.GeneratedValue;
|
||||
import javax.persistence.GenerationType;
|
||||
import javax.persistence.Id;
|
||||
import com.melon.boot.common.vo.CommonVo;
|
||||
import lombok.Data;
|
||||
|
||||
// Getter, Setter Auto Create
|
||||
@Data
|
||||
@Entity(name = "member")
|
||||
public class MemberVo extends CommonVo {
|
||||
@Id
|
||||
@GeneratedValue(strategy = GenerationType.IDENTITY)
|
||||
private Long mbrSeq;
|
||||
private String id;
|
||||
private String pwd;
|
||||
private String name;
|
||||
private String addrLoad;
|
||||
}
|
||||
```
|
||||
|
||||
## 5. JpaRepository를 상속받은 interface 작성
|
||||
> MemberRepository.java
|
||||
|
||||
```java
|
||||
package com.melon.boot.member.service.repository;
|
||||
|
||||
import org.springframework.data.jpa.repository.JpaRepository;
|
||||
import com.melon.boot.member.vo.MemberVo;
|
||||
|
||||
public interface MemberRepository extends JpaRepository<MemberVo, Long> {
|
||||
}
|
||||
```
|
||||
|
||||
## 6. Service Class 작성
|
||||
> MemberService.java
|
||||
|
||||
```java
|
||||
import java.util.List;
|
||||
import java.util.Optional;
|
||||
import org.springframework.beans.factory.annotation.Autowired;
|
||||
import org.springframework.stereotype.Service;
|
||||
import com.melon.boot.member.service.repository.MemberRepository;
|
||||
import com.melon.boot.member.vo.MemberVo;
|
||||
|
||||
@Service
|
||||
public class MemberService {
|
||||
|
||||
@Autowired
|
||||
private MemberRepository memberRepository;
|
||||
|
||||
// INSERT
|
||||
public MemberVo insert(MemberVo memberVo) throws Exception {
|
||||
return memberRepository.save(memberVo);
|
||||
}
|
||||
|
||||
// SELECT LIST
|
||||
public List<MemberVo> findAll() throws Exception {
|
||||
return memberRepository.findAll();
|
||||
}
|
||||
|
||||
// SELECT BY ID
|
||||
public Optional<MemberVo> findById(Long mbrSeq) throws Exception {
|
||||
return memberRepository.findById(mbrSeq);
|
||||
}
|
||||
|
||||
// UPDATE
|
||||
public MemberVo updateById(MemberVo memberVo) throws Exception {
|
||||
Optional<MemberVo> e = memberRepository.findById(memberVo.getMbrSeq());
|
||||
|
||||
MemberVo resultMember = null;
|
||||
if(e.isPresent()) {
|
||||
resultMember = memberRepository.save(memberVo);
|
||||
}
|
||||
return resultMember;
|
||||
}
|
||||
|
||||
// DELETE
|
||||
public void deleteById(Long mbrSeq) throws Exception {
|
||||
memberRepository.deleteById(mbrSeq);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 7. Controller Class 작성
|
||||
> MemberController.java
|
||||
|
||||
```java
|
||||
import java.time.LocalDateTime;
|
||||
import org.springframework.beans.factory.annotation.Autowired;
|
||||
import org.springframework.stereotype.Controller;
|
||||
import org.springframework.web.bind.annotation.GetMapping;
|
||||
import org.springframework.web.bind.annotation.RequestMapping;
|
||||
import com.melon.boot.member.service.MemberService;
|
||||
import com.melon.boot.member.vo.MemberVo;
|
||||
|
||||
@Controller
|
||||
@RequestMapping("/member")
|
||||
public class MemberController {
|
||||
|
||||
@Autowired
|
||||
MemberService memberService;
|
||||
|
||||
@GetMapping("/insert")
|
||||
public void insertMember() throws Exception {
|
||||
try {
|
||||
MemberVo memberVo = new MemberVo();
|
||||
|
||||
memberService.insert(memberVo);
|
||||
} catch(Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
@GetMapping("/selectList")
|
||||
public void selectMemberList() throws Exception {
|
||||
try {
|
||||
memberService.findAll();
|
||||
} catch(Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
@GetMapping("/select")
|
||||
public void selectMember() throws Exception {
|
||||
try {
|
||||
memberService.findById((long) 1);
|
||||
} catch(Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
@GetMapping("/update")
|
||||
public void updateMember() throws Exception {
|
||||
try {
|
||||
MemberVo memberVo = new MemberVo();
|
||||
|
||||
memberService.updateById(memberVo);
|
||||
} catch(Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
@GetMapping("/delete")
|
||||
public void deleteMember(MemberVo memberVo) throws Exception {
|
||||
try {
|
||||
memberService.deleteById(memberVo.getMbrSeq);
|
||||
} catch(Exception e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 8. 테스트 URL
|
||||
- /member/insert
|
||||
- /member/selectList
|
||||
- /member/select
|
||||
- /member/update
|
||||
- /member/delete
|
||||
|
||||
|
||||
위에서처럼 jpa, lombok, mariadb를 사용해서 CRUD 통신하는 서버를 만들어보았다. <br />
|
||||
이제 이것을 바탕으로 GLotto에 해당하는 데이터 테이블을 만들고 데이터를 넣은다음 돌아가는 서버를 만들 수 있겠다. <br />
|
||||
100
src/content/blog/study/spring/2022-11-01-maven-gradle.md
Normal file
100
src/content/blog/study/spring/2022-11-01-maven-gradle.md
Normal file
@@ -0,0 +1,100 @@
|
||||
---
|
||||
title: Maven과 Gradle 차이점
|
||||
date: 2022-11-01
|
||||
tags: spring, 공부
|
||||
excerpt: Maven? Gradle?
|
||||
---
|
||||
# Maven? Gradle?
|
||||
Maven의 경우에는 스프링 프로젝트에서 pom.xml이란 이름으로 다루고 있다.
|
||||
|
||||
Gradle은 스프링부트, 안드로이드에서 쓰는걸로 기억하고 있는데, 이것이 맞는 것인가?! 바로 알아보자<br />
|
||||
|
||||
## Maven 이란?
|
||||
프로젝트를 진행하게 되면 단순히 자신이 작성한 코드만으로 개발하는 것이 아니라 많은 라이브러리들을 활용해서 개발을 하게 된다.<br />
|
||||
세상에 많은 천재들이 개발한 라이브러리를 활용해서 개발을 하게 되면 개발 시간도 단축될뿐 아니라 안정성도 그만큼 보장되지 않겠는가! 적극 활용한다!👍<br />
|
||||
|
||||
이 때 사용되는 라이브러리들의 수가 수십개가 훌쩍 넘어가버리는 일이 발생해 이 많은 라이브러리들을 관리하는 것이 힘들어지는 경우가 종종 발생하게 된다.<br />
|
||||
**Maven**은 이러한 문제를 해결해 줄 수 있는 도구이다.<br />
|
||||
Maven은 내가 사용할 라이브러리 뿐만 아니라 해당 라이브러리가 작동하는데 필요한 다른 라이브러리들까지 관리하여 네트워크를 통해 자동으로 다운 받아 준다.
|
||||
|
||||
Maven은 프로젝트의 전체적인 라이프사이클을 관리하는 도구이며, 많은 편리함과 이점이 있어 널리 사용되고 있다. <br />
|
||||
Maven은 JDK설치와 같이 설치할 수 있다. 환경변수를 잡아주면 cmd에서 **mvn -version**을 통해 버전을 알 수 있고 설치가 가능하다. <br />
|
||||
설치는 [메이븐 홈페이지](https://maven.apache.org/download.cgi)에서 할 수 있다.
|
||||
|
||||
### Maven의 Lifecycle
|
||||
maven 에서는 미리 정의하고 있는 빌드 순서가 있으며 이 순서를 라이프사이클이라고 한다. 라이프 사이클의 각 빌드 단계를 Phase라고 하는데, 이런 Phase들은 의존관계를 가지고 있다. <br />
|
||||
|
||||
- Clean : 이전 빌드에서 생성된 파일들을 삭제하는 단계
|
||||
- Validate : 프로젝트가 올바른지 확인하고 필요한 모든 정보를 사용할 수 있는지 확인하는 단계
|
||||
- Compile : 프로젝트의 소스코드를 컴파일하는 단계
|
||||
- Test : 단위 테스트를 수행하는 단계
|
||||
- 테스트 실패 시, 빌드 실패로 처리
|
||||
- 스킵 가능
|
||||
- Package : 실제 컴파일된 소스 코드와 리소스들을 jar등의 배포를 위한 패키지로 만드는 단계
|
||||
- Verify : 통합테스트 결과에 대한 검사를 실행하여 품질 기준을 충족하는지 확인하는 단계
|
||||
- Install : 패키지를 로컬 저장소에 설치하는 단계
|
||||
- Site : 프로젝트 문서를 생성하는 단계
|
||||
- Deploy : 만들어진 Package를 원격 저장소에 release하는 단계
|
||||
|
||||
위 9개의 라이프 사이클 말고도 더 많은 종류가 존재한다. <br />
|
||||
이를 크게 Clean, Build, Site 세 가지로 나누고 있다. <br />
|
||||
각 단계를 모두 수행하는 것이 아니라 원하는 단계까지만 수행할 수도 있으며 test단계는 큰 프로젝트의 경우에 몇 시간이 소요될 수 있으니 수행하지 않도록 스킵이 가능하다. <br />
|
||||
|
||||
#### Phase와 Goal
|
||||
위에서 잠깐 언급헀던 Phase는 Maven의 Build LifeCycle의 각각의 단계를 의미한다. 각각의 Phase는 의존관계를 가지고 있어서 해당 Phase가 수행되려면 선행 단계의 Phase가 모두 수행되어야 한다. <br />
|
||||
|
||||
메이븐에서 제공되는 모든 기능은 플러그인 기반으로 동작하는데 메이븐은 라이프 사이클에 포함 되어있는 Phase마저도 플러그인을 통해 실질적인 작업이 수행된다. 즉 각가의 Phase는 어떤 일을 할지 정의하지 않고 어떤 플러그인의 Goal을 실행할지 설정한다. <br />
|
||||
|
||||
메이븐에서는 하나의 플러그인에서 여러작업을 수행할 수 있도록 지원하며, 플러그인에서 실행할 수 있는 각각의 기능을 Goal이라고 한다. <br />
|
||||
플러그인의 Goal을 실행하는 방법은 다음과 같다. <br />
|
||||
- mvn groupId:artifactId:version:goal (아래와 같이 생략 가능)
|
||||
- mvn plugin:goal
|
||||
|
||||
### POM(Project Object Model)
|
||||
pom은 이름 그대로 Project Object Model의 정보를 담고 있는 파일이다. 이 파일에서 주요하게 다루는 기능들은 다음과 같다. <br />
|
||||
- 프로젝트 정보 : 프로젝트의 이름, 개발자 목록, 라이센스 등
|
||||
- 빌드 설정 : 소스, 리소스, 라이프 사이클별 실행한 플러그인(Goal)등 빌드와 관련된 설정
|
||||
- 빌드 환경 : 사용자 환셩 별로 달라질 수 있는 프로파일 정보
|
||||
- POM연관 정보 : 의존 프로젝트(모듈), 상위 프로젝트, 포함하고 있는 하위 모듈 등
|
||||
|
||||
POM은 pom.xml파일을 말하며 Maven의 기능을 이용하기 위해 사용된다.
|
||||
|
||||
---
|
||||
|
||||
## Gradle 이란?
|
||||
Gradle이란 기본적으로 빌드 배포 도구(Build Tool)이다. <br />
|
||||
안드로이드 앱을 개발할때 필요한 공식 빌드시스템이기도 하며 JAVA, C/C++, Python 등을 지원한다. <br />
|
||||
|
||||
빌드툴인 Ant Builder와 그루비 스크립트를 기반으로 구축되어 기존 Ant의 역할과 배포 스크립트의 기능을 모두 사용가능하다. <br />
|
||||
|
||||
Maven의 경우 XML로 라이브러리를 정의하고 활용하도록 되어 있으나, Gradle의 경우 별도의 빌드스크립트를 통하여 사용할 어플리케이션 버전, 라이브러리등의 항목을 설정 할 수 있다. <br />
|
||||
|
||||
장점으로는 스크립트 언어로 구성되어 있기 때문에 XML과 달리 변수선언, if else for 등의 로직이 구현 가능하여 간결하게 구성이 가능하다. <br />
|
||||
|
||||
- 라이브러리 관리 : Maven repository를 동일하게 사용할 수 있어서 설정된 서버를 통하여 라이브러리를 다운로드 받아 모두 동일한 의존성을 가진 환경을 수정할 수 있다. 또한 자신이 추가한 라이브러리도 repo 서버에 올릴 수 있다.
|
||||
- 프로젝트 관리 : 모든 프로젝트가 일관된 디렉토리 구조를 가지고 빌드 프로세스를 유지하도록 도와준다.
|
||||
- 단위 테스트 시 의존성 관리 : junit 등을 사용하기 위해서 명시한다.
|
||||
|
||||
### Gradle 장점
|
||||
Maven에는 Gradle과 비교문서가 없지만, Gradle에는 비교문서가 있다. <br />
|
||||
그만큼 Maven의 모든 기능을 포함하고 있고, 더 뛰어나다고 표현하는것일까?<br />
|
||||
Gradle이 시기적으로 늦게 나온만큼 사용성, 성능 등 비교적 뛰어난 스펙을 가지고 있다.
|
||||
|
||||
### 그래서 Gradle이 Maven보다 좋은점은?
|
||||
- Build라는 동적인 요소를 XML로 정의하기에는 어려운 부분이 많다.
|
||||
- 설정 내용이 길어지고 가독성이 떨어짐
|
||||
- 의존관계가 복잡한 프로젝트 설정하기에는 부적절
|
||||
- 상속구조를 이용한 멀티 모듈 구현
|
||||
- 특정 설정을 소수의 모듈에서 공유하기 위해서는 부모 프로젝트를 생성하여 상속하게 해야함 (상속의 단점이 생김)
|
||||
- Gradle은 그루비를 사용하기 때문에, 동적인 빌드는 Groovy 스크립트로 플러그인을 호출하거나 직접 코드를 짜면 된다.
|
||||
- Configuration Injection 방식을 사용해서 공통 모듈을 상속해서 사용하는 단점을 커버했다.
|
||||
- 설정 주입시 프로젝트의 조건을 체크할 수 있어서 프로젝트별로 주입되는 설정을 다르게 할 수 있다.
|
||||
|
||||
> Gradle은 Maven보다 최대 100배 빠르다고 한다.
|
||||
|
||||
---
|
||||
|
||||
## 그래서 결론은?
|
||||
Gradle이 출시되었을 때는 Maven이 지원하는 Scope를 지원하지 않았고 성능면에서도 앞설것이 없었다. Ant의 유연한 구조적 장점과 Maven의 편리한 의존성 관리 기능을 합쳐놓은 것만으로도 많은 인기를 얻었던 Gradle은 버전이 올라가며 성능이라는 장점까지 더해지면서 대세가 되었다. <br />
|
||||
|
||||
리드미컬하게 테스트를 진행하고 민첩한 지속적 배포를 생각하고 있다면 새로운 배움이 필요하더라도 Gradle을 사용하는것이 좋다고 생각한다. <br />
|
||||
14
src/content/blog/study/webdev/2022-03-24-web-note.md
Normal file
14
src/content/blog/study/webdev/2022-03-24-web-note.md
Normal file
@@ -0,0 +1,14 @@
|
||||
---
|
||||
title: Web 개발 환경에 대한 정리
|
||||
date: 2022-03-24
|
||||
tags: webdev, 공부
|
||||
excerpt: Web 개발 환경에 대한 정리
|
||||
---
|
||||
# Web 프론트엔드 개발 환경에 대한 이해와 정리
|
||||
이전에 webpack babel eslint 등 기본 프론트엔드 개발에 대한 개념의 이해와 정리를 한 적이 있었다.
|
||||
|
||||
그러나 오래되기도 했고, 정리한 내용이 없어져서(이것이 정말 큰 문제다...) 다시 복습을 하면서 정리하는 시간을 가져보려고 한다.
|
||||
|
||||
도구를 사용하면서 그 도구의 사용법을 정확히 알지 못하고 사용하던대로만 사용하면 다른 유형의 사용법이 필요할 경우에는 대처하지 못한다고 개인적으로 생각한다.
|
||||
|
||||
그렇기 때문에 확실하게 그 내용을 잡고 정리하면서 다시 한 번 내것으로 만들고, 목표로하는 역량을 키워보도록 하자.
|
||||
273
src/content/blog/study/webdev/2022-03-24-web-npm.md
Normal file
273
src/content/blog/study/webdev/2022-03-24-web-npm.md
Normal file
@@ -0,0 +1,273 @@
|
||||
---
|
||||
title: Web 개발 환경에 대한 이해 - NPM
|
||||
date: 2022-03-24
|
||||
tags: webdev, 공부
|
||||
excerpt: NPM 이란?
|
||||
---
|
||||
# 프론트엔드 개발 환경의 이해 : NPM
|
||||
Node.js는 백엔드를 구현하는 기술이라고 생각했던 때가 있었다. 그러나 요즘은 FE 공고에도 Node.js 기술이 우대사항이 되고 있는것을 볼 수 있었다. 웹 어플리케이션을 개발하는데 있어서 직접적으로 사용하는것은 아니지만 개발 환경을 구성하고 이해하는데에는 Node.js를 모른다면 언젠가 막히는 때가 온다고 한다.
|
||||
|
||||
---
|
||||
|
||||
## 1. 프론트엔드 개발에 Node.js가 필요한 이유
|
||||
### 최신 스펙으로 개발 할 수 있다
|
||||
자바스크립트 스펙의 빠른 발전에 비해 브라우져의 지원 속도는 항상 뒤쳐진다. 아무리 편리한 스펙이 나오더라도 이것을 구현해 주는 중간다리의 역할, 예를 들자면 바벨과 같은 도구의 도움 없이는 부족하다. 더불어 웹팩, NPM 같은 노드 기술로 만들어진 환경에서 사용할 때 비로소 자동화된 프론트엔드 개발 환경을 갖출 수 있다.
|
||||
|
||||
마찬가지로 Typescript, SASS 같은 고수준 프로그래밍 언어를 사용하려면 전용 **트랜스파일러**가 필요하다. 물론 이것 역시 Node.js 환경이 뒷받침 되어야 우리가 말하는 프론트엔드 개발 환경을 만들 수 있다.
|
||||
|
||||
### 빌드 자동화
|
||||
과거처럼 코딩 결과물을 브라우져에 바로 올리는 경우는 흔치 않다고 한다. <br>
|
||||
파일을 압축하고, 코드를 난독화하고, 폴리필을 추가하는 등 개발 이외의 작업을 거친 후에야 배포를 하게 된다. <br>
|
||||
Node.js는 이러한 일련의 빌드 과정을 이해하는데 많은 역할을 하고 있다. 또한 라이브러리 의존성을 해결하고, 각종 테스트를 자동화하는데도 사용된다.
|
||||
|
||||
### 개발 환경 커스터마이징
|
||||
각 프레임워크에서 제공하는 도구를 사용하면 손쉽게 개발환경을 갖출 수 있도록 지원하고 있다. <br>
|
||||
React.js의 CRA(create-react-app), Vuejs의 vue-cli를 사용한다면 손쉽게 개발환경을 갖출 수 있는 것이다. <br>
|
||||
그러나 개발 프로젝트는 각자의 목적이나 사용방법에 있어서 형편이라는 것이 있어서 툴을 그대로 사용할 수 없는 경우도 빈번하다. <br> 어쩌면 자동화된 도구를 사용할 수 없는 환경이 다가올수도 있는데, 그 때에 직접 환경을 구축해야 할 수도 있다. <br>
|
||||
커스터마이징을 하려면 반드시 Node.js 지식이 필요하다. <br>
|
||||
|
||||
|
||||
위에서 배경하에 Node.js는 프론트엔드 개발에서 필수 기술로 자리매김하고 있다. <br>
|
||||
이번에는 Node.js 기술을 바탕으로 프론트엔드 개발 환경을 이해하고 직접 구성해보면 좋을 것 같다.
|
||||
|
||||
--------
|
||||
|
||||
## 2. Node.js 설치
|
||||
노드 설치는 무척 간단하다. 자신의 운영체제에 맞게 설치파일을 다운받으면 된다. <br>
|
||||
[Nodejs.org](https://Nodejs.org) 사이트에서 노드 최신 버전을 다운로드 받아 보자. <br>
|
||||
|
||||
두 가지 버전을 선택하여 설치할 수 있다. 왼쪽 짝수 버전, 오른쪽이 홀수 버전이다. 안정적이고 장기간 지원하는 것이 짝수 버전이고, 불안정할 수 있지만 최신 기능을 지원하는 것이 홀수 버전이다. 리눅스 배포버전과 비슷한 관례를 따른다고 한다. <br>
|
||||
|
||||
- 짝수 버전 : 안정적, 신뢰도 높음 (LTS)
|
||||
- 홀수 버전 : 최신 기능
|
||||
|
||||
이왕이면 오른쪽에 있는 최신 버전을 선택해서 다운로드 받아보자. 개발 환경에 대한 이해니까! (만약 Node.js로 서버를 구성하는 경우라면 어떤 버전을 사용할지 신중하게 선택해야 한다.)
|
||||
|
||||

|
||||
|
||||
설치화면이 나오고 버튼을 몇 번 클릭하면 아래 경로로 Node.js와 NPM이 설치가 완료된다. <br>
|
||||
|
||||
- Node.js : `\usr\local\bin\node`
|
||||
- NPM : `\usr\local\bin\npm`
|
||||
|
||||
설치가 완료된 후, 터미널을 열어서 명령어를 통해 확인해 볼 수 있다.
|
||||
```
|
||||
$ node
|
||||
> 1 + 2
|
||||
3
|
||||
```
|
||||
|
||||
`>` 프롬프트와 함께 입력 대기화면이 나온다. 정수 계산이나 `console.log()` 같은 내용도 실행 할 수 있다.
|
||||
|
||||
이것을 노드 REPL(read-eval-print loop)이라고 부르는데, 자바스크립트 코드를 입력하고 즉시 결과를 확인할 수 있는 프로그램이다. 파이썬이나 PHP 같은 언어도 제공하는 기능이다.
|
||||
|
||||
`.exit` 명령을 실행하거나 `ctrl + c`를 연속 두 번 입력하면 REPL 프로그램에서 빠져 나올 수 있다. <br>
|
||||
|
||||
이번에는 `--version` 옵션을 추가해서 설치된 버전을 확인해 본다.
|
||||
```
|
||||
$ node --version
|
||||
v17.3.1
|
||||
```
|
||||
NPM(Node Package Manage)도 확인 할 수 있다.
|
||||
```
|
||||
$ npm
|
||||
Usage: npm <command>
|
||||
|
||||
$ npm --version
|
||||
8.3.0
|
||||
```
|
||||
이렇게 각 Node.js와 NPM을 설치하고 각 설치된 버전을 확인해 볼 수 있다.
|
||||
|
||||
---
|
||||
|
||||
## 3. 프로젝트 초기화
|
||||
개발 프로젝트는 외부 라이브러리를 다운로드 받고 빌드하는 등 일련의 명령어를 자동화하여 프로젝트를 관리하는 도구가 존재한다. PHP의 컴포저(Composer)나 자바의 그래들(Gradle) 같은 툴이 그러한 프로그램이라고 할 수 있다. <br>
|
||||
NPM은 자바스크립트 기반 프로젝트의 빌드 도구인 셈이다. NPM을 이용해 프론트엔드 개발 프로젝트를 세팅해보자.
|
||||
|
||||
### 3-1. INIT
|
||||
NPM은 다양한 하위 명령어를 제공하는데, 그 중 `init` 명령어를 사용하면 프로젝트를 생성 할 수 있다.
|
||||
```shell
|
||||
$ npm init
|
||||
|
||||
package name: (npm sampple)
|
||||
version:
|
||||
description:
|
||||
entry point:
|
||||
test command:
|
||||
git repository:
|
||||
keywords:
|
||||
author:
|
||||
license:
|
||||
```
|
||||
|
||||
위의 내용에서 볼 수 있듯이 패키지 이름, 버전 등 프로젝트와 관련된 정보들을 얻기 위한 몇 가지 질문들을 볼 수 있다.<br>
|
||||
빈칸으로 남겨 놓으면 괄호 안에 기본 값으로 세팅할 수 있다. 모든 질문에 답하면 명령어를 실행한 폴더에 package.json 파일이 생성된다.<br>
|
||||
모두 기본값으로 세팅하려면 `npm init -y` 명령어로 질문을 스킵하고 package.json 파일을 생성할 수 있다. <br>
|
||||
|
||||
### 3-2. Package.json
|
||||
Node.js는 package.json 파일에 프로젝트의 모든 정보를 기록한다.
|
||||
|
||||
- name: 프로젝트 이름
|
||||
- version: 프로젝트 버전 정보
|
||||
- description: 프로젝트 설명
|
||||
- main: 노드 어플리케이션일 경우 진입점 경로. 프론트엔드 프로젝트일 경우 사용하지 않는다.
|
||||
- scripts: 프로젝트 명령어를 등록할 수 있다.초기화시 test 명령어가 샘플로 등록되어 있다
|
||||
- author: 프로그램 작성자
|
||||
- license: 라이센스
|
||||
|
||||
각 항목의 의미는 위의 내용과 같다.
|
||||
|
||||
--------
|
||||
|
||||
## 4. 프로젝트 명령어
|
||||
생성한 프로젝트는 package.json에 등록한 스크립트(script)를 이용해 실행한다. <br>
|
||||
어플리케이션 빌드, 테스트, 배포, 실행 등의 명령어를 등록하여 실행하는데에는 다음과 같다. <br>
|
||||
|
||||
```shell
|
||||
$ npm test
|
||||
|
||||
Error: no test specified
|
||||
npm ERR! Test failed. See above for more details.
|
||||
```
|
||||
|
||||
에러 메세지를 출력하고 그 다음 줄에 npm 에러가 발생한다. 이것은 npm 스크립트에 등록된 쉘 스크립트 코드를 실행했기 때문이다.
|
||||
|
||||
package.json
|
||||
```javascript
|
||||
{
|
||||
"script": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
}
|
||||
}
|
||||
```
|
||||
echo 명령어로 메세지 "Error: no test specified"를 출력한뒤 에러 코드 1을 던지면서 종료하는 동작이다. 에러 코드 1을 확인하면 에러("npm ERR!...")를 출력하게된다.
|
||||
|
||||
NPM에서 사용할 수 있는 명령어는 몇 가지나 될까? 확인해보자면 아래를 살펴보자.
|
||||
```shell
|
||||
Usage: npm <command>
|
||||
|
||||
where <command> is one of:
|
||||
access, adduser, audit, bin, bugs, c, cache, ci, cit,
|
||||
clean-install, clean-install-test, completion, config,
|
||||
create, ddp, dedupe, deprecate, dist-tag, docs, doctor,
|
||||
edit, explore, get, help, help-search, hook, i, init,
|
||||
install, install-ci-test, install-test, it, link, list, ln,
|
||||
login, logout, ls, org, outdated, owner, pack, ping, prefix,
|
||||
profile, prune, publish, rb, rebuild, repo, restart, root,
|
||||
run, run-script, s, se, search, set, shrinkwrap, star,
|
||||
stars, start, stop, t, team, test, token, tst, un,
|
||||
uninstall, unpublish, unstar, up, update, v, version, view,
|
||||
whoami
|
||||
```
|
||||
엄청나게 많다. 보통 사용하는 명령어는 start, test, install, uninstall이다.
|
||||
- start : 어플리케이션 실행
|
||||
- test : 테스트
|
||||
- install : 패키지 설치
|
||||
- uninsatll : 패키지 삭제
|
||||
|
||||
명령어를 추가할 수도 있다. 빌드를 위한 'build' 스크립트는 package.json의 scripts에 build 키를 등록하여 사용할 수 있다.
|
||||
```javascript
|
||||
{
|
||||
"scripts": {
|
||||
"build" : "여기에 빌드 스크립트를 등록한다."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
커스텀으로 등록한 스크립트는 다음과 같이 실행한다.
|
||||
```shell
|
||||
$ npm run build
|
||||
```
|
||||
|
||||
프론트엔드 개발을 위해 등록해야할 스크립트는 두 가지 정도가 있겠다.
|
||||
- build : 소스 빌드
|
||||
- lint : 소스 컨벤션 검사
|
||||
|
||||
---
|
||||
|
||||
## 5. 패키지 설치
|
||||
### 5-1. CDN을 이용한 방법
|
||||
외부 라이브러리를 가져다 쓰는 것은 무척 자연스러운 일이다. 간단한 방법은 CDN(Content Delivery Network)으로 제공하는 라이브러리를 직접 가져 오는 방식이다. 리액트의 주소를 html에서 로딩한다.
|
||||
```javascript
|
||||
<script src="https://unpkg.com/react@16/umd/react.development.js"></script>
|
||||
```
|
||||
|
||||
CDN의 서버 장애로 인해 외부 라이브러리를 사용할 수 없다면 어떻게 될까?? <br>
|
||||
아무리 우리 어플리케이션 서버가 정상이더라도 필수 라이브러리를 가져오지 못한다면 웹 어플리케이션은 정상적으로 동작하지 않을 것이다. <br>
|
||||
|
||||
### 5-2. 직접 다운로드 받는 방법
|
||||
그렇다면 라이브러리 코드를 우리 프로젝트 폴더에 다운받아 놓는건 어떨까? CDN을 사용하지 않기 때문에 장애와 독립적으로 웹 어플리케이션을 제공할 수 있을 것 같다. <br>
|
||||
|
||||
하지만 이런 상황도 있다. 라이브러리는 계속해서 업데이트 될 것이고, 우리 프로젝트에서도 최신 버전으로 교체해야 한다. 매번 직접 다운로드하는 것은 매우 귀찮은 일이 될 것이다. 버전에 따라 하위 호환성 여부까지 확인하려면 실수할 여지가 많다. <br>
|
||||
|
||||
라이브러리를 어느 한 곳에서 업데이트하고 하위 호환되는 안전한 버전만 다운받아 사용할 수 있다면 어떨까? <br>
|
||||
|
||||
### 5-3. NPM을 이용한 방법
|
||||
NPM은 이런 방식으로 패키지를 관리한다. `npm install` 명령어로 외부 패키지를 우리 프로젝트 폴더에 다운로드 해보자.
|
||||
```shell
|
||||
$ npm install react
|
||||
```
|
||||
최신 버전의 react를 NPM 저장소에서 찾아 우리 프로젝트로 다운로드 하는 명령어다. package.json에는 설치한 패키지 정보를 기록한다.
|
||||
```javascript
|
||||
{
|
||||
"dependencies": {
|
||||
"react": "^16.12.0"
|
||||
}
|
||||
}
|
||||
```
|
||||
버전 16.12.0을 설치했다는 의미이다.
|
||||
|
||||
### 5-4. 유의적 버전
|
||||
"^16.12.0"이 의미하는 바는 무엇일까? <br>
|
||||
|
||||
위 질문에 답하기 전에 버전 관리에 대해서 생각해 볼 필요가 있다. 만약 프로젝트에서 사용하는 패키지의 버전을 엄격하게 제한한다면 어떨까? 프로젝트를 버전업 하는데 꽤 힘들 수 있다. **사용하는 패키지를 전부 버전업해야 하기 때문**이다. 어쩌면 우리 프로젝트는 현재 버전에 갇혀 버릴지도 모른다.
|
||||
|
||||
그럼 프로젝트에서 사용하는 패키지 버전을 느슨하게 풀어 놓으면 문제가 해결될까? 오히려 여러 버전별로 코드를 관리해야하는 혼란스러움을 겪게될 수 있다.
|
||||
|
||||
버전 번호를 관리하기 위한 규칙이 필요한데 이 체계를 **"유의적 버전"**이라고 한다. NPM은 이 유의적 버전(Sementic Version)을 따르는 전제 아래 패키지 버전을 관리한다.
|
||||
|
||||
유의적 버전은 주(Major), 부(Minor), 수(Patch) 세 가지 숫자를 조합해서 버전을 관리한다. 위에 설치한 react의 버전은 v16.12.0인데 주 버전이 16, 부 버전이 12, 수 버전이 0인 셈이다.
|
||||
|
||||
- 주 버전(Major Version): 기존 버전과 호환되지 않게 변경한 경우
|
||||
- 부 버전(Minor version): 기존 버전과 호환되면서 기능이 추가된 경우
|
||||
- 수 버전(Patch version): 기존 버전과 호환되면서 버그를 수정한 경우
|
||||
|
||||
### 5-5. 버전의 범위
|
||||
NPM이 버전을 관리하는 방식은 유의적 버전 명시뿐만 아니라 버전의 범위를 자신만의 규칙으로 관리한다. 가장 단순한 것이 특정 버전을 사용하는 경우다.
|
||||
```
|
||||
1.2.3
|
||||
```
|
||||
|
||||
특정 버전보다 높거나 낮은 범위를 나타내는 방법은 다음과 같다.
|
||||
```
|
||||
>1.2.3
|
||||
>=1.2.3
|
||||
<1.2.3
|
||||
<=1.2.3
|
||||
```
|
||||
마지막으로 틸드(~)와 캐럿(^)을 이용해 범위를 명시한다.
|
||||
```
|
||||
~1.2.3
|
||||
^1.2.3
|
||||
```
|
||||
|
||||
틸트(~)는 마이너 버전이 명시되어 있으면 패치버전만 변경한다. 예를 들어 ~1.2.3 표기는 1.2.3 부터 1.3.0 미만 까지를 포함한다. 마이너 버전이 없으면 마이너 버전을 갱신한다. ~0 표기는 0.0.0부터 1.0.0 미만 까지를 포함한다.
|
||||
|
||||
캐럿(^)은 정식버전에서 마이너와 패치 버전을 변경한다. 예를 들어 ^1.2.3 표기는 1.2.3부터 2.0.0 미만 까지를 포함한다. 정식버전 미만인 0.x 버전은 패치만 갱신한다. ^0 표기는 0.0.0부터 0.1.0 미만 까지를 포함한다.
|
||||
|
||||
보통 라이브러리 정식 릴리즈 전에는 패키지 버전이 수시로 변한다. 0.1에서 0.2로 부버전이 변하더라도 하위 호환성을 지키지 않고 배포하는 경우가 빈번하다. ~0로 버전 범위를 표기한다면 0.0.0부터 1.0.0미만까지 사용하기 때문에 하위 호완성을 지키지 못하는 0.2로도 업데이트 되어버리는 문제가 생길수 있다.
|
||||
|
||||
반면 캐럿을 사용해 ^0.0으로 표기한다면 0.0.0부터 0.1.0 미만 내에서만 버전을 사용하도록 제한한다. 따라서 하위 호완성을 유지할 수 있다. (자세한 내용은 [여기](/_posts/devlog/webdev/2022-03-26-web-npmcarrot.md)를 참고)
|
||||
|
||||
NPM으로 패키지를 설치하면 package.json에 설치한 버전을 기록하는데 캐럿 방식을 이용한다. 초기에는 버전 범위에 틸트를 사용하다가 캐럿을 도입해서 기본 동작으로 사용했다. 그래서 우리가 설치한 react는 ^16.12.0 표기로 버전 범위를 기록한 것이다.
|
||||
|
||||
---
|
||||
|
||||
## 6. 정리
|
||||
Node.js 기술을 기반으로 하는 프로트엔드 개발 환경 구축을 위해 Node.js와 NPM을 설치했다.
|
||||
|
||||
npm init 명령어를 사용하면 package.json에 정보를 기록하고 프로젝트를 초기화 한다.
|
||||
|
||||
NPM이 제공하는 기본 명령어와 커스텀 명령어 추가방법을 알아보았다.
|
||||
|
||||
npm install로 외부 패키지를 다운로드 할 수 있고, 버전을 관리하는 방식에 대해 살펴 보았다.
|
||||
31
src/content/blog/study/webdev/2022-03-25-web-seo.md
Normal file
31
src/content/blog/study/webdev/2022-03-25-web-seo.md
Normal file
@@ -0,0 +1,31 @@
|
||||
---
|
||||
title: SEO란 무엇인가?
|
||||
date: 2022-03-25
|
||||
tags: webdev, 공부
|
||||
excerpt: SEO란?
|
||||
---
|
||||
# SEO란? 검색엔진최적화(Search Engine Optimization) 이해
|
||||
요즘 사람들은 궁금한 것에 대한 답을 대부분 Naver, Google 등에 검색하여 답을 얻곤 합니다. 그렇기 때문에 당연히 모든 비즈니스 및 웹사이트 소유주들은 Google에서 자신들의 정보를 사람들이 찾기 쉽도록 만들기 위해서라면 할 수 있는 모든 것을 하고 있습니다. 검색 결과에서 상위에 노출될 수 있도록 내 콘텐츠를 최적화하는 방식 즉, 이것이 바로 SEO입니다.
|
||||
|
||||
성공적인 SEO를 수행하기 위한 첫 번째 단계는 간편한 사용자 지정과 콘텐츠 업데이트를 지원하고, 사이트 요소를 최적화하는 데 필요한 도구를 제공하는 플랫폼을 통해 웹사이트를 제작하는 것입니다. Wix와 같은 웹사이트 제작 도구를 활용해 보세요. 간편하게 사이트를 업데이트 할 수 있으며, SEO 도구가 내장되어 있어 편리합니다.
|
||||
|
||||
사이트의 토대가 얼추 지어졌다면 순위 향상에 도움이 되는 메타데이터, 링크와 같은 세부 사항을 신경 써야 합니다. 지금부터 이러한 세부 사항을 시행하기 위해 무엇이 필요한지, 세부사항들이 SEO 표준을 충족하는지 살펴보도록 하겠습니다.
|
||||
|
||||
## SEO 란?
|
||||
SEO(검색 엔진 최적화)는 웹사이트가 유기적인(무료) 검색 방식을 통해 검색 엔진에서 상위에 노출될 수 있도록 최적화하는 과정을 말합니다. 비즈니스 유형이 어떤 것이든 SEO는 가장 중요한 마케팅 유형 중 하나입니다.
|
||||
|
||||
왜냐하면 Google은 검색하는 사람들에게 긍정적인 사용자 경험을 선사하는 것이 목표이기 때문에 가능한 한 최고의 정보를 제공하길 원합니다. 따라서, SEO 노력은 검색 엔진이 여러분의 콘텐츠를 특정 검색어에 대한 웹 상의 주요한 정보로 인식하도록 하는 과정에 포커스를 맞추어야 합니다.
|
||||
|
||||
## SEO는 어떻게 이루어지나?!
|
||||
검색 엔진은 웹페이지가 어떤 콘텐츠를 가지고 있는지, 해당 페이지가 무엇에 대한 것인지 판단하기 위해 인터넷을 통하여 웹페이지를 크롤링하는 로봇인 웹 크롤러를 사용합니다. 웹 크롤러는 코드를 스캔하여 웹페이지에 표시되는 텍스트, 이미지, 동영상을 등을 수집하여 가능한 모든 정보를 얻습니다. 웹 크롤러가 각 페이지에서 사용할 수 있는 정보 유형에 대한 충분한 정보를 수집하여 해당 내용이 검색자에게 유용하다고 판단하면 해당 페이지를 색인에 추가합니다. 여기서 말하는 색인은 본질적으로 검색 엔진이 잠재적인 검색자에게 제공하기 위해 저장한 모든 가능성 있는 웹 결과입니다.
|
||||
|
||||
검색 엔진은 검색자들이 찾고 있는 것뿐만 아니라 온라인에 이미 존재하는 다른 정보들을 기반으로 최상의 결과가 무엇인지 평가합니다. 검색자가 검색을 하면 알고리즘은 검색어를 색인의 관련 정보와 일치시켜 검색자가 입력한 검색어에 대한 정확한 답변을 제공합니다. 그 다음 플랫폼은 수백 개의 신호를 사용하여 각 검색자에게 표시될 콘텐츠 순서를 결정합니다. 그리고 SEO 전문가들은 이러한 신호들을 완벽하게 마스터하려고 합니다.
|
||||
|
||||
Google은 알고리즘이나 프로세스에 대한 자세한 사항을 공개하지 않기 때문에 어떤 요소가 색인화와 순위에 영향을 미치는지 정확하게 알 수 없다는 점을 아는 것이 중요합니다. 그러므로 SEO는 정확하게 맞아 떨어지는 과학이 아니며, 최적화를 완벽하게 구현한 것처럼 보이더라도 그에 대한 결과를 보기 위해서는 인내심이 필요하고, 지속적으로 조정을 해주어야 할 수 있습니다.
|
||||
|
||||
## 온-페이지 SEO vs 오프-페이지 SEO
|
||||
무엇이 검색 엔진의 순위에 가장 큰 영향을 미치는지 정확히 알 방법이 없기 때문에 전문가들은 SEO 전략에는 다양한 전술을 포함하는 것을 권장합니다. 이러한 전술은 크게 On-page SEO와 Off-page SEO라는 두 가지 범주로 나눌 수 있습니다.
|
||||
|
||||
On-page SEO는 디자인 및 작성한 콘텐츠에서부터 메타데이터, 대체 텍스트 등에 이르기까지 웹페이지 자체에 구현하는 전략을 말합니다. Off-page SEO는 페이지의 외부에서 수행하는 단계를 말합니다. 여기에는 외부 링크, SNS 게시물, 다른 웹사이트 프로모션 방식 등이 포함됩니다.
|
||||
|
||||
On-page SEO 및 Off-page SEO 모두 내 사이트로 트래픽을 유도하고, 궁극적으로 내 사이트가 인터넷에서 중요한 참가자라는 신호를 Google에 보내기 위해 필수적입니다. 내 페이지들이 중요하고, 사람들이 내가 제공하는 것들을 아는 것에 관심이 있다는 것을 Google에 알림으로써 내 페이지가 상위에 노출되고, 더 많은 트래픽을 유도하도록 만들 수 있습니다.
|
||||
70
src/content/blog/study/webdev/2022-03-26-web-npmcarrot.md
Normal file
70
src/content/blog/study/webdev/2022-03-26-web-npmcarrot.md
Normal file
@@ -0,0 +1,70 @@
|
||||
---
|
||||
title: npm package 틸트(~)를 대신해서 캐럿(^) 사용
|
||||
date: 2022-03-26
|
||||
tags: webdev, 공부
|
||||
excerpt: 틸트 대신해서 캐럿을 사용하기
|
||||
---
|
||||
## 틸트(~)
|
||||
일단 틸트(`~`)에 대해서 알아보자. <br>
|
||||
[NPM문서](https://docs.npmjs.com/cli/v8/configuring-npm/package-json#dependencies)에 따르면 npm을 사용할 때 `package.json`에서 버전 명시를 다음과 같이 할 수 있다.
|
||||
- `1.2.3`
|
||||
- `>1.2.3`
|
||||
- `>=1.2.3`
|
||||
- `<1.2.3`
|
||||
- `<=1.2.3`
|
||||
- `~1.2.3`
|
||||
|
||||
여기서 가장 많이 사용하는 방식이 틸트(`~`) 방식이고, ``npm install MODULE --save``나 ``npm install MODULE --save-dev``를 사용하면 자동으로 ``package.json``에 의존성을 추가 할 수 있는데, 이 때 기본으로 사용하는 방법이 틸트(`~`) 방식이다. <br>
|
||||
틸트는 간단히 말하자면 현재 지정한 버전의 마지막 자리 내의 범위에서만 자동으로 업데이트 한다. <br>
|
||||
- `~0.0.1` : `>=0.0.1 <0.1.0`
|
||||
- `~0.1.1` : `>=0.1.1 <0.2.0`
|
||||
- `~0.1` : `>=0.1.0 <0.2.0`
|
||||
- `~0` : `>=0.0 <0.1`
|
||||
|
||||
그래서 다양한 방식으로 버전을 명시했을 때 위와 같은 범위내에서 자동으로 업데이트를 한다.
|
||||
|
||||
---
|
||||
|
||||
## 캐럿(^)
|
||||
그러면 캐럿(`^`)은 틸트와 어떻게 다를까?
|
||||
|
||||
캐럿을 설명하기 이전에 먼저 [SemanticVersioning](https://semver.org/lang/ko/) (보통 SemVer라고 부른다)에 대해서 알아야 하는데, Node.js도 그렇고 npm 모듈들은 모두 SemVer를 따르고 있다. SemVer는 ``MAJOR.MINOR.PATCH``의 버저닝을 따르는데 각 의미는 다음과 같다.
|
||||
- 주 버전(Major Version): 기존 버전과 호환되지 않게 변경한 경우
|
||||
- MAJOR version when you make incompatible API changes
|
||||
- 부 버전(Minor version): 기존 버전과 호환되면서 기능이 추가된 경우
|
||||
- MINOR version when you add functionality in a backwards-compatible manner
|
||||
- 수 버전(Patch version): 기존 버전과 호환되면서 버그를 수정한 경우
|
||||
- PATCH version when you make backwards-compatible bug fixes
|
||||
|
||||
즉, MAJOR 버전은 API의 호환성이 깨질만한 변경사항을 의미하고 MINOR 버전은 하위호환성을 지키면서 기능이 추가된 것을 의미하고 PATCH 버전은 하위호환성을 지키는 범위내에서 버그가 수정된 것을 의미한다.
|
||||
|
||||
**캐럿(^)은 Node.js의 모듈이 이 SemVer의 규약을 따르는 것을 신뢰한다는 가정하에 동작한다.** <br>
|
||||
그래서 MINOR나 PATCH버전은 하위호환성이 보장되어야 하므로 업데이트를 한다.
|
||||
- `^1.0.2` : `>=1.0.2 <2.0`
|
||||
- `^1.0` : `>=1.0.0 <2.0`
|
||||
- `^1` : `>=1.0.0 <2.0`
|
||||
|
||||
그래서 캐럿을 사용했을 때에는 위와 같이 동작한다. <br>
|
||||
틸트와 비교해보면 차이점이 명확한데, `1.x.x` 내에서는 하위호환성이 보장되므로 그 내에서는 모두 업데이트 하겠다는 의미이다.
|
||||
|
||||
하지만! 여기에는 **예외사항**이 있다.
|
||||
- `^0.1.2` : `>=0.1.2 <0.2.0`
|
||||
- `^0.1` : `>=0.1.0 <0.2.0`
|
||||
- `^0` : `>=0.0.0 <1.0.0`
|
||||
- `^0.0.1` : `==0.0.1`
|
||||
|
||||
**버전이 1.0.0 미만인 경우에는 (SemVer에서는 pre-releases라고 부른다) 상황이 다르다.** <br>
|
||||
소프트웨어 대부분에서 1.0 버전을 내놓기 전에는 API 변경이 수시로 일어난다. 그래서 `0.1`을 사용하다가 `0.2`를 사용하면 API가 모두 달려졌을 수 있다. 그래서 캐럿(`^`)을 사용할 때, 0.x.x에서는 마치 틸트처럼 동작해서 지정한 버전 자릿수 내에서만 업데이트한다. <br>
|
||||
그리고 `0.0.x`인 경우에는 하위호환성이 보장되지 않을 가능성이 높으므로 위의 마지막 예시처럼 지정한 버전만을 사용한다.
|
||||
|
||||
--------
|
||||
|
||||
## 캐럿에 대한 오류!
|
||||
캐럿은 동작방식을 이해하면 수긍 할만하다.(물론 배포용으로는 어렵지만 이건 틸드도 마찬가지) 하지만 약간 복잡한 부분이 있어서 그냥 틸드를 쓰고자 할 수도 있는데 그럼에도 캐럿의 존재 정도는 알고 있어야 한다. 캐럿은 근래에 추가된 기능이므로 과거 버전의 npm은 캐럿을 이해하지 못한다.(정확히 어느 버전부터 추가되었는지 찾지 못헀다) 그래서 캐럿이 없는 구 버전의 npm에서 캐럿을 사용하면 오류가 발생한다.
|
||||
|
||||
구문을 이해하지 못하므로 버전을 찾지 못하고 "Error: No compatible version found"이라는 설치 오류가 발생한다. 이는 ``npm install -g`` npm을 통해서 npm을 최신 버전으로 올리면 해결할 수 있다. 캐럿을 모른 상태에서 저 오류를 보면 좀 당황스러울수 있다.
|
||||
|
||||
npm **v1.4.3**부터는 ``npm install MODULE --save``나 ``npm install MODULE --save-dev``를 사용했을 때 기본값이 틸드 대신 캐럿이 되었기 때문에 틸드를 사용하고자 한다면 매번 직접 수정해야 한다. 그리고 본인은 틸드방식을 사용하더라도 참조한 모듈이 다른 모듈을 참조할 때 캐럿을 사용할 수도 있으므로 npm을 최신 버전으로 업데이트하지 않으면 결국 오류가 나서 제대로 설치가 안 될 것이다.
|
||||
|
||||
|
||||
Reference : [npm package.json에서 틸드(~) 대신 캐럿(^) 사용하기](https://blog.outsider.ne.kr/1041)
|
||||
@@ -6,12 +6,15 @@ const collectFrontmatter = (raw) => {
|
||||
if (lines[0]?.trim() === '---') {
|
||||
cursor = 1;
|
||||
for (; cursor < lines.length; cursor += 1) {
|
||||
const line = lines[cursor].trim();
|
||||
const rawLine = lines[cursor];
|
||||
const line = rawLine.trim();
|
||||
if (line === '---') {
|
||||
cursor += 1;
|
||||
break;
|
||||
}
|
||||
if (!line) continue;
|
||||
if (/^\s+/.test(rawLine)) continue;
|
||||
if (!line.includes(':')) continue;
|
||||
const [key, ...rest] = line.split(':');
|
||||
meta[key.trim()] = rest.join(':').trim();
|
||||
}
|
||||
@@ -38,10 +41,20 @@ const extractExcerpt = (body) => {
|
||||
|
||||
const normalizeTags = (value) => {
|
||||
if (!value) return [];
|
||||
return value
|
||||
const mapped = value
|
||||
.split(',')
|
||||
.map((tag) => tag.trim())
|
||||
.filter(Boolean);
|
||||
.filter(Boolean)
|
||||
.map((tag) => {
|
||||
const lower = tag.toLowerCase();
|
||||
if (lower === 'diary' || lower === 'dailylog') return '일상';
|
||||
if (lower === 'dev' || lower === 'development') return '개발';
|
||||
if (lower === 'study') return '공부';
|
||||
if (lower === 'idea' || lower === 'ideas') return '아이디어';
|
||||
return tag;
|
||||
});
|
||||
|
||||
return Array.from(new Set(mapped));
|
||||
};
|
||||
|
||||
const normalizeTitle = (slug) =>
|
||||
@@ -49,8 +62,24 @@ const normalizeTitle = (slug) =>
|
||||
.replace(/-/g, ' ')
|
||||
.replace(/\b\w/g, (letter) => letter.toUpperCase());
|
||||
|
||||
const inferTagFromPath = (path) => {
|
||||
const match = path.match(/\/blog\/([^/]+)\//);
|
||||
if (!match) return '';
|
||||
const folder = match[1];
|
||||
if (folder === 'daily') return '일상';
|
||||
if (folder === 'dev') return '개발';
|
||||
if (folder === 'study') return '공부';
|
||||
if (folder === 'ideas') return '아이디어';
|
||||
return '';
|
||||
};
|
||||
|
||||
const inferDateFromSlug = (slug) => {
|
||||
const match = slug.match(/\d{4}-\d{2}-\d{2}/);
|
||||
return match ? match[0] : '';
|
||||
};
|
||||
|
||||
export const getBlogPosts = () => {
|
||||
const modules = import.meta.glob('/src/content/blog/*.md', {
|
||||
const modules = import.meta.glob('/src/content/blog/**/*.md', {
|
||||
as: 'raw',
|
||||
eager: true,
|
||||
});
|
||||
@@ -58,15 +87,25 @@ export const getBlogPosts = () => {
|
||||
const posts = Object.entries(modules).map(([path, raw]) => {
|
||||
const slug = path.split('/').pop().replace(/\.md$/, '');
|
||||
const { meta, body } = collectFrontmatter(raw);
|
||||
const inferredTag = inferTagFromPath(path);
|
||||
const title = meta.title || extractTitle(body) || normalizeTitle(slug);
|
||||
const excerpt = meta.excerpt || extractExcerpt(body);
|
||||
const date = meta.date || '';
|
||||
const excerpt = meta.excerpt || meta.description || extractExcerpt(body);
|
||||
const date = meta.date || inferDateFromSlug(slug);
|
||||
const baseTags = normalizeTags(meta.tags);
|
||||
const categoryTags = normalizeTags(meta.category);
|
||||
const tags = Array.from(
|
||||
new Set([
|
||||
...baseTags,
|
||||
...categoryTags,
|
||||
...(inferredTag ? [inferredTag] : []),
|
||||
])
|
||||
);
|
||||
return {
|
||||
slug,
|
||||
title,
|
||||
excerpt,
|
||||
date,
|
||||
tags: normalizeTags(meta.tags),
|
||||
tags,
|
||||
body,
|
||||
};
|
||||
});
|
||||
|
||||
Reference in New Issue
Block a user